Significance
Keypoints
- Propose a text detection method for faster text detection using neural architecture search and efficient post-processing
- Demonstrate detection performance with respect to inference speed of the proposed method by experiments
Review
Background
Scene text detection is one of the tasks in computer vision with successful application of deep neural networks. Although there are a number of previous methods that achieve excellent performance with a reasonable speed, there still exists a need for faster methods which conserves the detection performance for real-time application in smaller devices. The authors address this issue by updating a previous method based on neural architecture search, and propose efficient post-processing step to achieve faster and better text detection.
Keypoints
Propose a method for faster text detection using neural architecture search and efficient post-processing
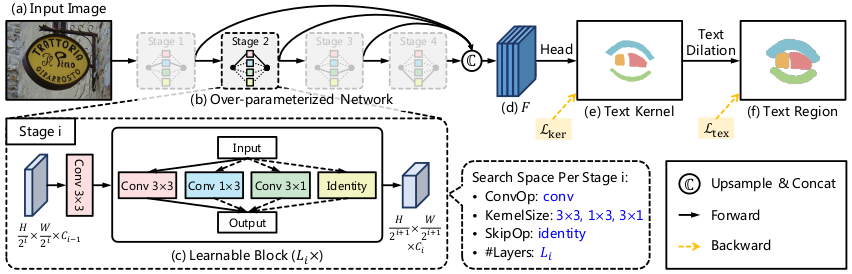 Schematic illustration of the proposed method
Schematic illustration of the proposed method
Main architecture of the proposed method largely inherits the ProxylessNAS but with different combination of convolutional layer kernel shapes in the learnable block $L_{i}$. (The authors claim that combination of vertical $3 \times 1$ or horizontal $1 \times 3$ kernels within the learnable block can capture the features of extreme aspect-ratio text lines, but I think that this statement requires further theoretical/experimental verification.) Optimal model $m$ is chosen from the over-parameterized initial network with the reward function $\mathcal{R}(m)$ incorporating both the detection performance metric IoU and the speed metric FPS: \begin{equation} \mathcal{R}(m) = (\text{IoU}_{k}(m) + \alpha \text{IoU}_{t}(m)) \times (\frac{\text{FPS}(m)}{T})^{w}. \end{equation}
The model $m$ outputs feature $F$ is used for predicting the text kernel label, rather than the coordinates of the bounding box.
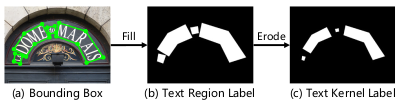 Generating region and kernel labels from the bounding box
The loss function is accordingly set as the DICE loss, which can represent the level of region overlap between the prediction and the label mask.
One of the important point is that the eroded text kernel and the dilated text region can be bidirectionally mapped by invertible and differentiable function, enabling end-to-end training and GPU computing for more efficient inference.
Generating region and kernel labels from the bounding box
The loss function is accordingly set as the DICE loss, which can represent the level of region overlap between the prediction and the label mask.
One of the important point is that the eroded text kernel and the dilated text region can be bidirectionally mapped by invertible and differentiable function, enabling end-to-end training and GPU computing for more efficient inference.
Demonstrate detection performance with respect to inference speed of the proposed method by experiments
The proposed method is extensively compared with previous methods for various datasets in terms of the detection performance with respect to the inference speed. Baseline methods include TextSnake, TextField, CRAFT, LOMO, SPCNet, PSENet for non-realtime methods and EAST, DB-R50, DB-R18, PAN, PAN++ for realtime methods. Comparison of Precision, recall, F-score with respect to FPS demonstrates solid performance/speed of the proposed method for Total-Text, CTW1500, ICDAR2015, and MSRA-TD500 datasets.
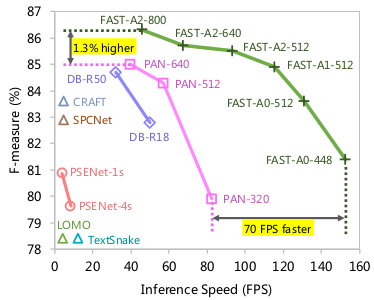 Performance curve of F-measure with respect to FPS
Performance curve of F-measure with respect to FPS
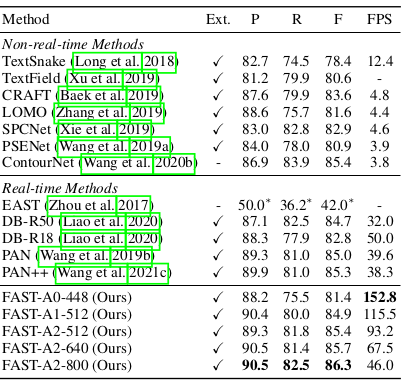 Quantiative performance of the proposed method for the Total-Text dataset
Quantiative performance of the proposed method for the Total-Text dataset
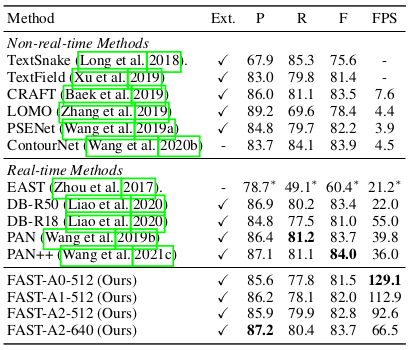 Quantiative performance of the proposed method for the CTW1500 dataset
Quantiative performance of the proposed method for the CTW1500 dataset
 Qualitative performance of the proposed method
Qualitative performance of the proposed method
Quantitative results of the proposed method for ICDAR2015, MSRA-TD500 are referred to the original paper.