Significance
Keypoints
- Propose a training framework using augmentation and pseudo-labeling for improving object detection model performance
- Demonstrate performance improvement in object detection with the proposed method compared to simple training frameworks
Review
Background
Object detection models are often trained in a supervised way with pairs of an input image (with augmentation) and its corresponding human-annotated bounding box coordinates. This simple training framework is straightforward but can easily be affected by input-label mismatch made by strong augmentation discarding appropriate input features, or annotation errors made by human mistakes. The authors address this issue of input-label mismatch by a form of bootstrapping during training. More specifically, the authors address these issues by providing separate augmentation pathways (normal / strong) and revising the human annotation with pretrained detection models.
Keypoints
Propose a training framework using augmentation and pseudo-labeling for improving object detection model performance
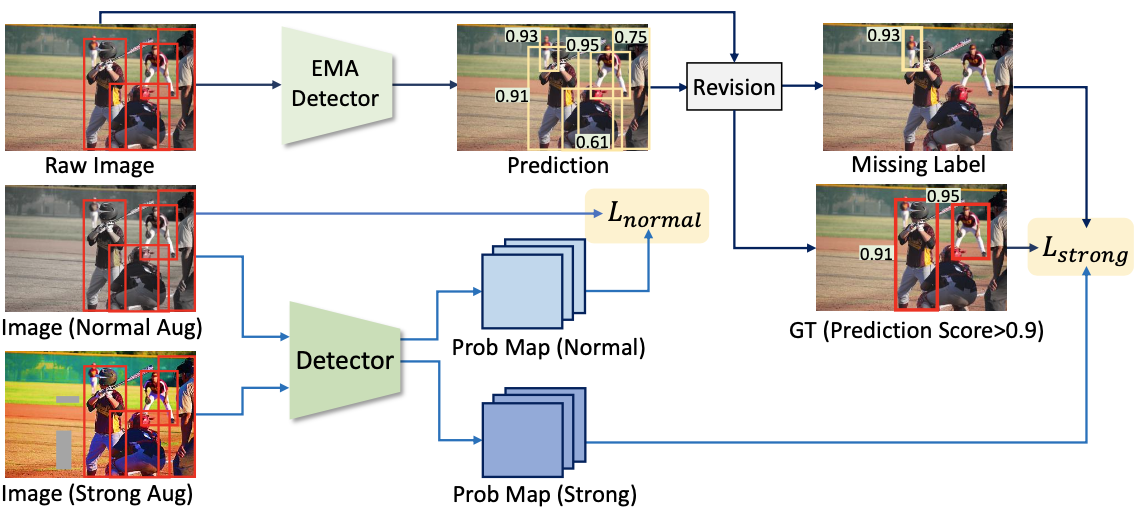 Schematic illustration of the proposed method
Schematic illustration of the proposed method
As mentioned in the background section, the propose a training framework by separating the input image augmentation to normal / strong augmentation paths. For augmented images (middle and bottom row of the above figure), probability map of the objects are obtained by the detector model that we are training. While normal augmented images are simply trained with human annotated labels, strong augmented images are trained with refined labels.
To obtain the refined label, exponential moving average of pre-trained detector is used to exploit model prediction of the bounding box annotation. Final training target labels are obtained by combining the label and the model prediction with IoU under 0.5 (missing label correction) and over 0.5 (noisy label correction). The denoised labels with IoU over 0.5 is further filtered by the condition which satisfies that model prediction score over 0.9 is only used, because labels with low prediction score may not appropriately contain strong augmented image features in the input.
 Pseudo-labeling scheme. (a) Blue and (b) green boxes are human annotations and model predictions, respectively. Application of (c) missing label correction, (d) noisy label correction, and (e) hybrid (both).
Pseudo-labeling scheme. (a) Blue and (b) green boxes are human annotations and model predictions, respectively. Application of (c) missing label correction, (d) noisy label correction, and (e) hybrid (both).
Demonstrate performance improvement in object detection with the proposed method compared to simple training frameworks
Performance of the proposed method (MixTraining) is validated on the COCO2017 dataset by comparing it with simple training (SiTraining) frameworks with single augmentation (normal or strong).
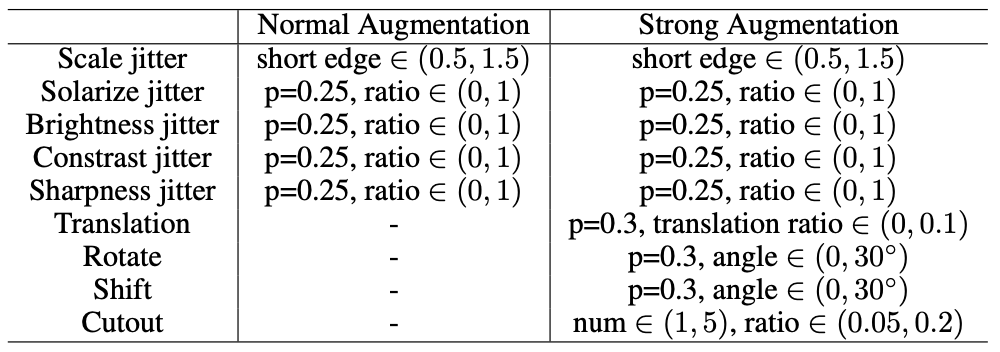 Definition of normal and strong augmentation
Definition of normal and strong augmentation
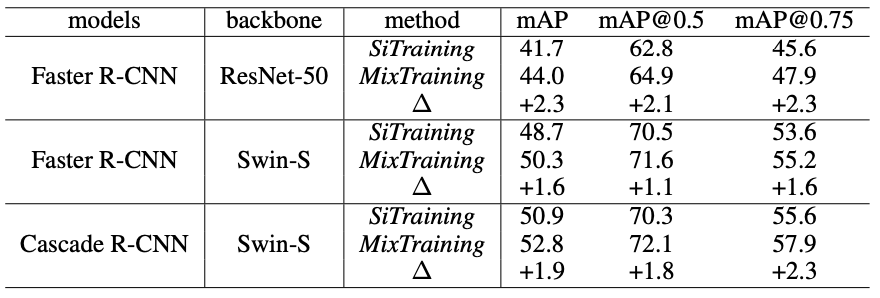 Quantiative performance of MixTraining compared to SiTraining
Quantiative performance of MixTraining compared to SiTraining
Experiments demonstrate that MixTraining is especially beneficial with longer training setting, suggesting the stabilizing effect of MixTraining compared to SiTraining.
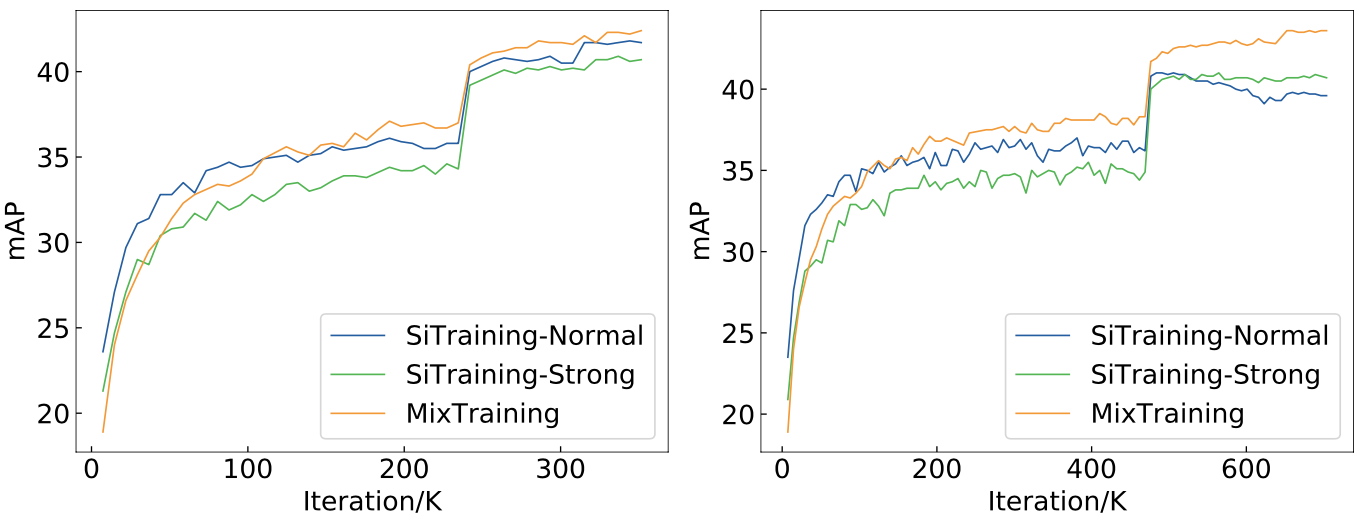 MixTraining is beneficial for longer training
MixTraining is beneficial for longer training
Further ablation study results are referred to the original paper.