Significance
Keypoints
- Propose a method for applying denoising diffusion models for image-to-image translation tasks
- Introduce an unified evaluation protocol for inpainting, uncropping, and JPEG decompression
- Demonstrate performance and general applicability of the proposed method by experiments
Review
Background
Diffusion models are a class of generative models, gaining big interest in the field owing to its state-of-the-art generative performance. Although there have been attempts on applying the diffusion models to conditional generation problems, the results have not been sufficient to rival GANs on image-to-image translation tasks, such as colorization, inpainting, uncropping, or JPEG decompression. The authors study and confirm versatility and general applicability of the diffusion model to these tasks, and show that the diffusion models can outperform GAN-based methods in terms of image quality and diversity.
Keypoints
Propose a method for applying denoising diffusion models for image-to-image translation tasks
The authors propose Palette, which the model is basically a 256 $\times$ 256 class-conditional U-Net used for conditional diffusion models. The training objective of Palette is formulated as: \begin{equation} \mathbb{E}_{(\mathbf{x},\mathbf{y})} \mathbb{E}_{\epsilon ~ \mathcal{N}(0,I)} \mathbb{E}_{\gamma} || f_{\theta} (\mathbf{x}, \sqrt{\gamma}\mathbf{y} + \sqrt{1-\gamma} \epsilon , \gamma) - \epsilon || ^{p} _{p}, \end{equation} where $\mathbf{x}$, $\mathbf{y}$ are input and target images, $f_{\theta}$ is a trainable neural network, and $\gamma \in [0,1]$ is the noise level indicator. The authors compare L1 and L2 norms for its effect on the final image characteristics, i.e. $p\in {1,2 }$, and find that L1 objective yields more conservative results with lower diversity, while L2 objective yields images with better diversity.
Introduce a unified evaluation protocol for inpainting, uncropping, and JPEG decompression
To correctly evaluate the model performance of image-to-image translation tasks, the authors propose a unified evaluation protocol for inpainting, uncropping, and JPEG decompression. The models are evaluated on ImageNet dataset with ctest10k split and proposed places10k subset images with Inception Score (IS), Fréchet Inception Distance (FID), Classification Accuracy (CA) of pretrained ResNet-50, Perceptual Distance (PD) from Inception-v1 feature space distance. Sample diversity is evaluated by visual inspection and histogram plots of pairwise SSIM scores between multiple model outputs. Human evaluation is further reported by fool rate from 2-alternative forced choice (2AFC) trials.
Demonstrate performance and general applicability of the proposed method by experiments
The authors experiment performance and general applicability of the proposed model in terms of colorization, inpainting, uncropping, and JPEG decompression. The authors further test the performance of Palette for JPEG decompression with the model trained from other three tasks (named Multi-Task Palette) to show general applicability in image-to-image translation tasks. The results suggest that Palette outperforms other previous methods in these four tasks, and achieve state-of-the-art results both qualitatively and quantitatively.
Colorization
 Qualitative results of the proposed method in colorization
Qualitative results of the proposed method in colorization
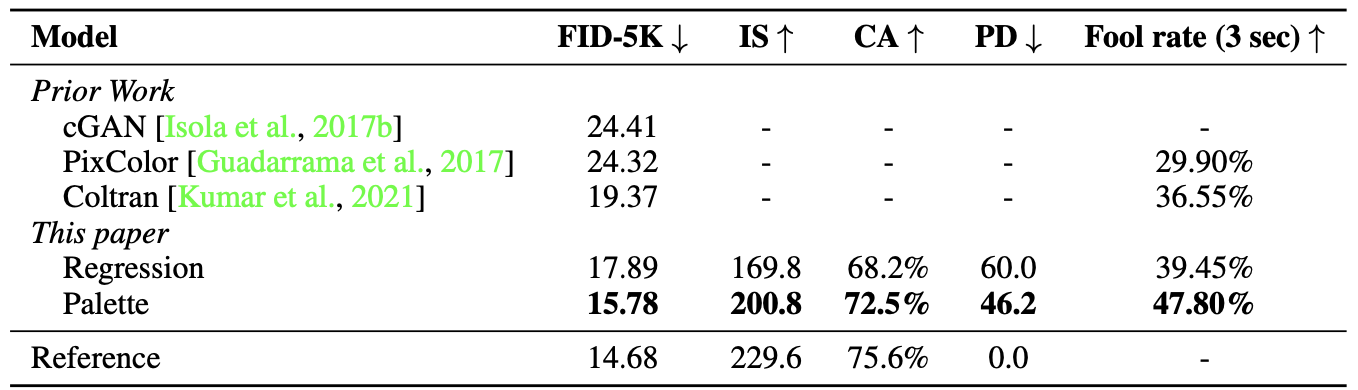 Quantitative results of the proposed method in colorization
Quantitative results of the proposed method in colorization
Inpainting
 Qualitative results of the proposed method in inpainting
Qualitative results of the proposed method in inpainting
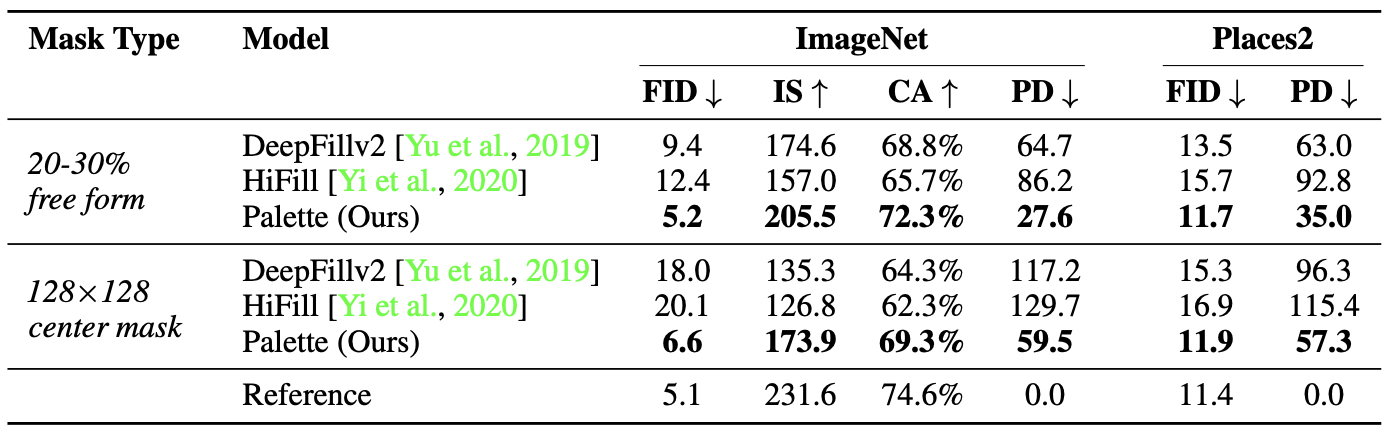 Quantitative results of the proposed method in inpainting
Quantitative results of the proposed method in inpainting
Uncropping
 Qualitative results of the proposed method in uncropping
Qualitative results of the proposed method in uncropping
 Quantitative results of the proposed method in uncropping
Quantitative results of the proposed method in uncropping
JPEG decompression
 Qualitative results of the proposed method in JPEG decompression
Qualitative results of the proposed method in JPEG decompression
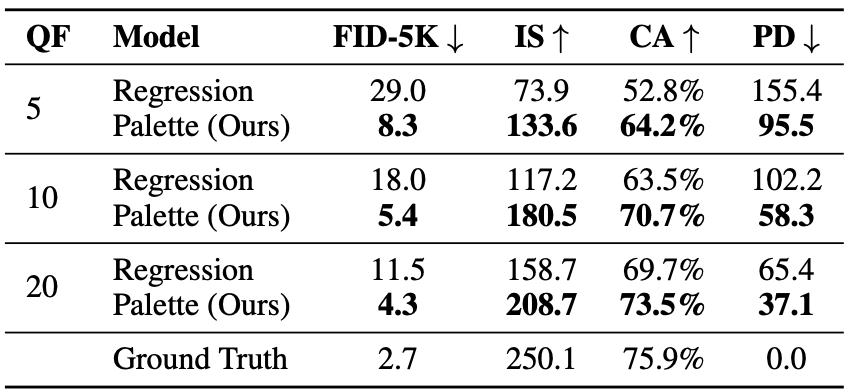 Quantitative results of the proposed method in JPEG decompression
Quantitative results of the proposed method in JPEG decompression
Another important point of the Palette is the output sample diversity, which GAN based methods usually suffer from mode collapse leading to less diverse output images.
 Exemplar image outputs from Palette, suggesting diversity
Exemplar image outputs from Palette, suggesting diversity
Further results on Multi-Task Palette and the role of self-attention in the model architecture are referred to the original paper.
Related
- Collaborative Score Distillation for Consistent Visual Synthesis
- Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
- Deep reparameterization of Multi-Frame Super-Resolution and Denoising
- Image Synthesis and Editing with Stochastic Differential Equations
- Cascaded Diffusion Models for High Fidelity Image Generation