Significance
Keypoints
- Propose a method for training a image representation encoder by autoencoding masked images
- Demonstrate speed and performance of the representation learning with proposed method
Review
Background
Self-supervised learning has greatly helped the field of natural language processing by enabling models to learn the representation of the input data itself. Masked language models, such as BERT or GPT, have led the self-supervised learning scheme which are to mask a certain number of words within the input and to recover the masked word. Similar scheme of training has been applied to computer vision models, but usually exploiting image augmentation instead of masking the image. This work tries to adopt the masking - recovering scheme to the self-supervised training of computer vision models. The authors address the issues of differences between the natural language processing tasks and the computer vision tasks, including the (i) difference of model computation, difference of information density of the data components, and the difference of reconstruction task nature. It should be noted that the proposed method can be thought of an extension of the denoising autoencoders (DAE) which have long been known for its capability for learning image representation in the encoded latent space.
Keypoints
Propose a method for training a image representation encoder by autoencoding masked images
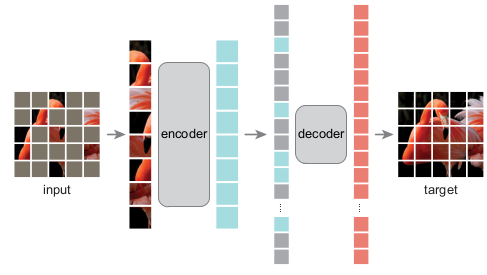 Schematic illustration of the proposed method
The method is very simple and straight forward.
The authors employ ViT as the encoder and the decoder to address the issue of (i) difference of model computation.
During training, the input image is randomly patch-masked by a prespecified proportion and only the un-masked portion of the images are input to the encoder.
The encoded latents are concatenated with the mask tokens and the decoder takes the encoded+mask tokens to reconstruct the original image.
After the training has finished, only the pretrained encoder part (which learned to extract the image representation) is used for downstream tasks.
Based on comparative studies, the authors mention that the best practice is to use mean squared error for reconstruction objective with 75\% of input image masked with uniformly random position patches.
Schematic illustration of the proposed method
The method is very simple and straight forward.
The authors employ ViT as the encoder and the decoder to address the issue of (i) difference of model computation.
During training, the input image is randomly patch-masked by a prespecified proportion and only the un-masked portion of the images are input to the encoder.
The encoded latents are concatenated with the mask tokens and the decoder takes the encoded+mask tokens to reconstruct the original image.
After the training has finished, only the pretrained encoder part (which learned to extract the image representation) is used for downstream tasks.
Based on comparative studies, the authors mention that the best practice is to use mean squared error for reconstruction objective with 75\% of input image masked with uniformly random position patches.
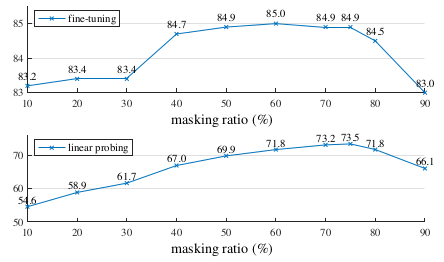 Masking ratio of 75\% shows good tradeoff between the performance and speed
Masking ratio of 75\% shows good tradeoff between the performance and speed
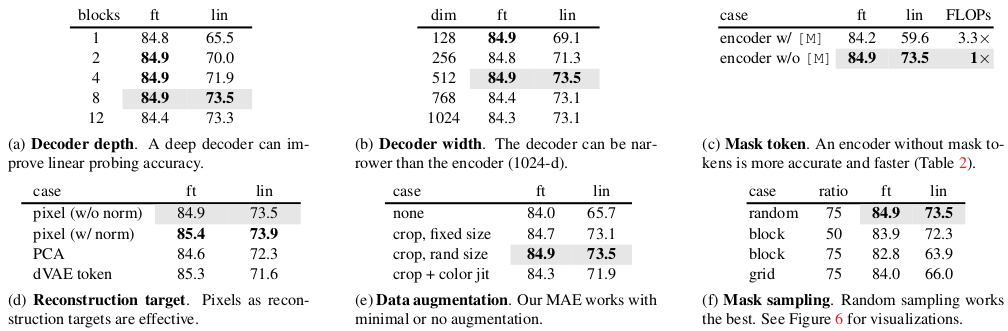 Comparative study results for the best training practices
Comparative study results for the best training practices
Demonstrate speed and performance of the representation learning with proposed method
Since the method takes only 25\% of the input image, computating speed and scalability is greatly improved when compared to other self-supervised training methods. Comparative study of the fine-tuned model with baseline self-supervised pre-training methods demonstrate the exceptional performance and scalability of the proposed method.
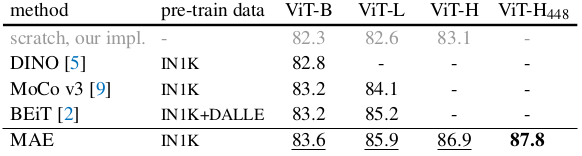 Comparison with other self-supervised training methods of ViT
Comparison with other self-supervised training methods of ViT
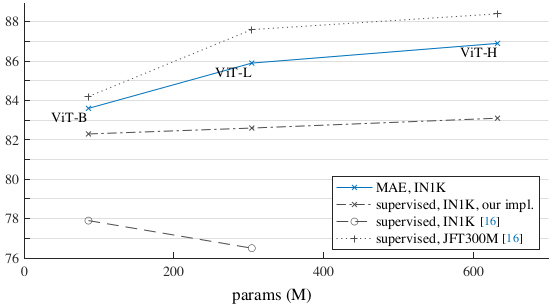 Comparison with supervised pre-training results
Comparison with supervised pre-training results
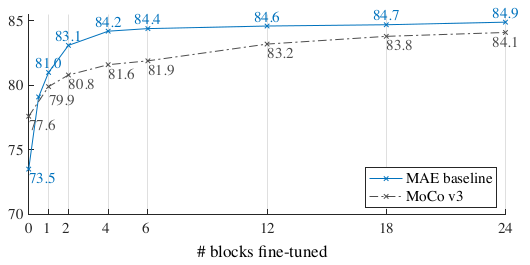 Comparison with MoCo-v3 with limited number of Transformer blocks (partial fine-tuning)
Comparison with MoCo-v3 with limited number of Transformer blocks (partial fine-tuning)
Further transfer learning performance results are referred to the original paper. I would say that the proposed is method is very meaningful in that (i) it improves scalability and performance of ViT model pre-training significantly, and that (ii) it generalizes a well-known previous method (DAE) with a simple approach.