Significance
Keypoints
- Propose a method for image-text contrastive learning with pre-trained image model
- Demonstrate performance gain of the proposed method by experiments
Review
Background
Contrastive learning usually refers to a training scheme that minimizes the latent space distance between the same input sample with different view, while maximizing the distance from different samples. A different, but contrastive approach has recently been proposed which is to minimize (or maximize) the latent space distance between the paired (or unpaired) image-text data from separate text and image models. This contrastive image-text training has shown to be capable of zero-shot image classification tasks. In this paper, the authors propose contrastive-tuning by adopting a heavily pre-trained image model to this contrastive image-text training scheme. The idea does not seem to be very novel, but the performance gain of the contrastive-tuning is exceptional which is demonstrated by extensive comparative experiments.
Keypoints
Propose a method for image-text contrastive learning with pre-trained image model
Two possible options exist for adopting a pre-trained image model. First option is to load weights of the pre-trained model, and freeze the model during the image-text contrastive learning (denoted L). Second option is to let the pre-trained model be fine-tuned during the image-text contrastinve learning (denoted U). Previous methods trained from randomly initialized model weights (denoted u) for both image and text models.
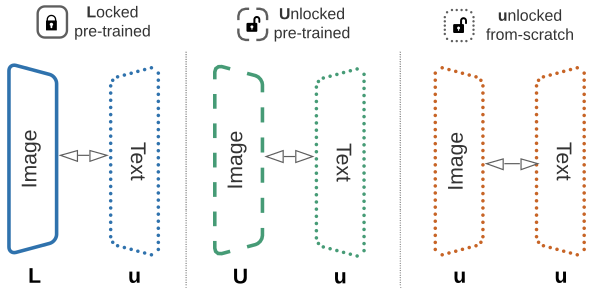 Lu, Uu, uu training schemes for image-text contrastive learning
Lu, Uu, uu training schemes for image-text contrastive learning
The authors find that the Lu (or LiT short for Locked-image Text) scheme, which is to use locked-weight pre-trained image model and randomly initialized text model improves the performance of the zero-shot transfer learning most.
 Design choice comparison experiment results
Design choice comparison experiment results
Another important question that can be asked is whether pre-trained text models can help zero-shot transfer performance.
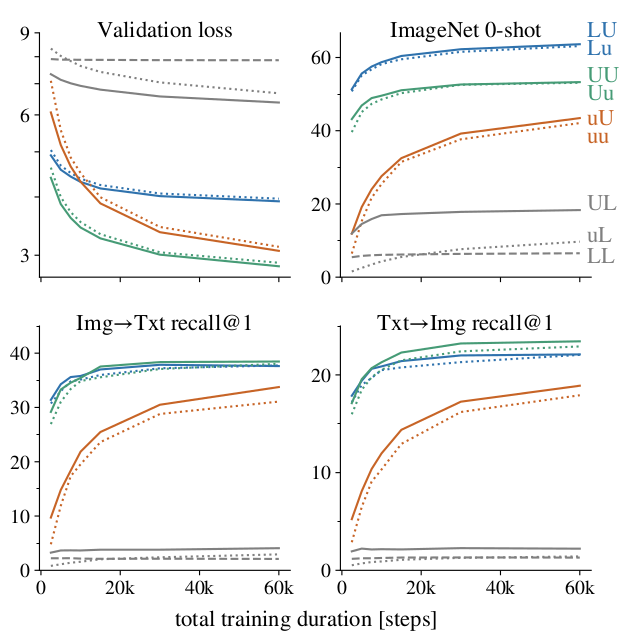 Final performance for different training durations for all training combinations
Final performance for different training durations for all training combinations
As can be seen from above figure, pre-trained text models did not provide significant performance gain.
Demonstrate performance gain of the proposed method by experiments
LiT-tuning is performed on the public CC12M, YFCC100m datasets along with in-house 4 billion image/alt-text pair datasets. Experimented image models include the ResNet, ViT, and MLP-Mixer. The performance is evaluated on zero-shot ImageNet classification and MSCOCO image-text retrieval tasks.
Performance of the proposed LiT-tuning scheme is compared to baseline methods including CLIP and ALIGN.
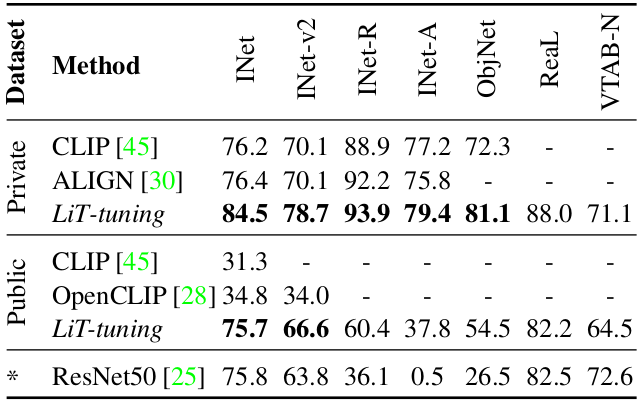 Quantitative performance of the proposed method compared to baseline methods
Quantitative performance of the proposed method compared to baseline methods
It can be seen that on five out-of-distribution (OOD) test variants, the proposed method shows significant robustness over baseline methods.
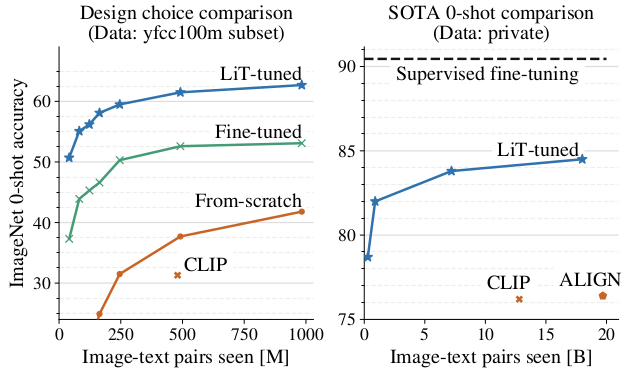 Training on YFCC or private datasets both show significant performance gain over baseline methods
Training on YFCC or private datasets both show significant performance gain over baseline methods
The authors performed extensive comparative/ablation studies to evaluate the best training scheme of the proposed method, which is referred to the original paper. These are not detailed in this review, since the most important point in this work can be summarized into: pre-trained image models locked + random initialized text models contrastive learning significantly boosts zero-shot transfer performance.
Related
- A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
- Video Language Planning
- PaLI-3 Vision Language Models: Smaller, Faster, Stronger
- Collaborative Score Distillation for Consistent Visual Synthesis
- Improving Contrastive Learning on Imbalanced Seed Data via Open-World Sampling