Significance
Keypoints
- Introduce a self-supervised large-scale cross-lingual wav2vec model
- Demonstrate performance of the proposed model by experiments
Review
Background
Pre-trained language models at scale with over billions of parameters, such as GPT-3, HyperCLOVA have opened a new horizon in the field of natural language representation learning. The authors bring this simple fact to the domain of speech representation learning. A wav2vec 2.0 model with upto 2 billion parameters is pre-trained with multi-lingual speech data of 423K hours from multiple sources.
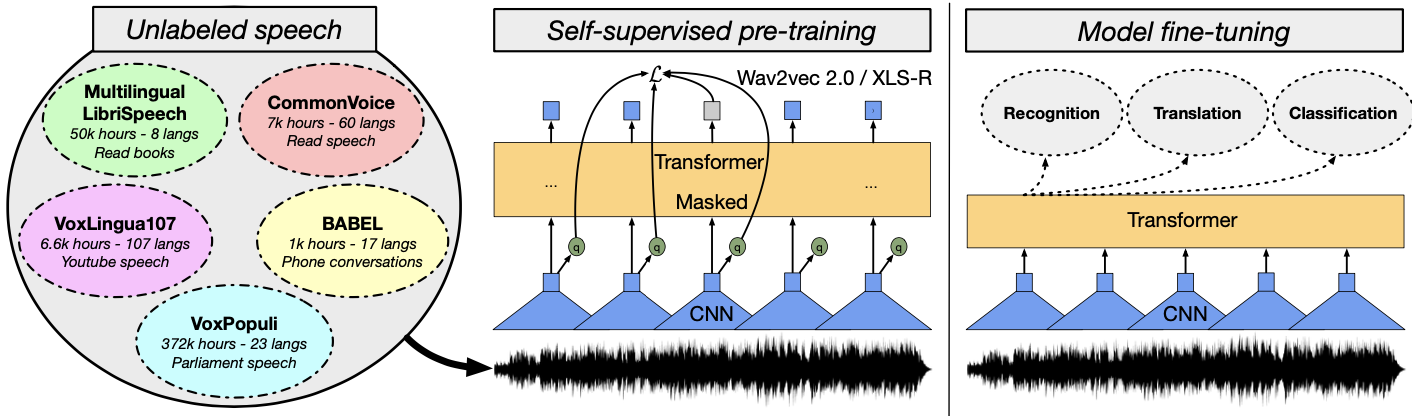 Multi-lingual speech data & wav2vec model at scale
Multi-lingual speech data & wav2vec model at scale
As can be expected (but cannot easily be experimented), the pre-trained model achieves state-of-the-art performance on downstream speech tasks.
Keypoints
Demonstrate performance of the proposed model by experiments
Detailed description of the dataset and the model is referred to the original paper. In short, the pre-training dataset includes 436K hours of speech data from VoxPopuli, Multilingual Librispeech, CommonVoice, VoxLingua107, and BABEL. The model is trained by solving a contrastive task over masked feature output.
 The XLS model architectures include three types depending on the number of parameters
The XLS model architectures include three types depending on the number of parameters
The model performance is tested on various speech representation tasks with benchmark datasets.
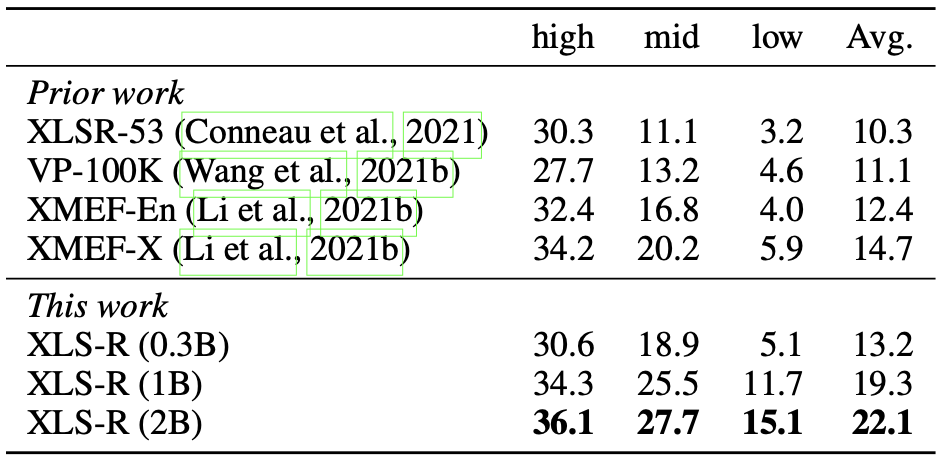 Speech translation BLEU performance (X->En) on CoVoST-2
Speech translation BLEU performance (X->En) on CoVoST-2
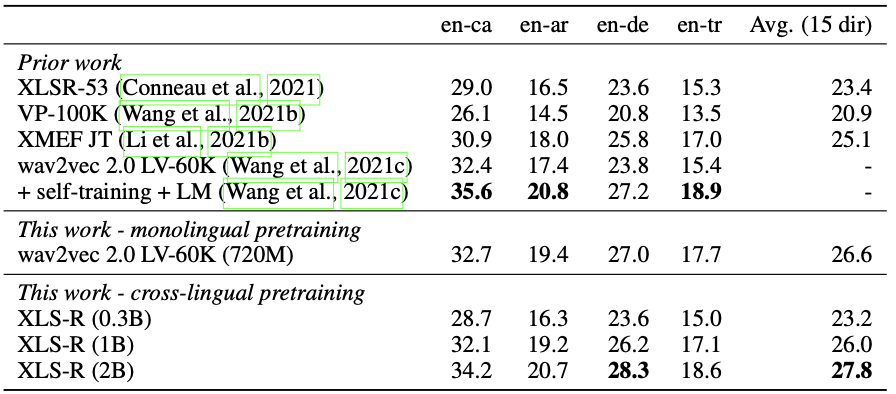 Speech translation BLEU performance (En->X) on CoVoST-2
Speech translation BLEU performance (En->X) on CoVoST-2
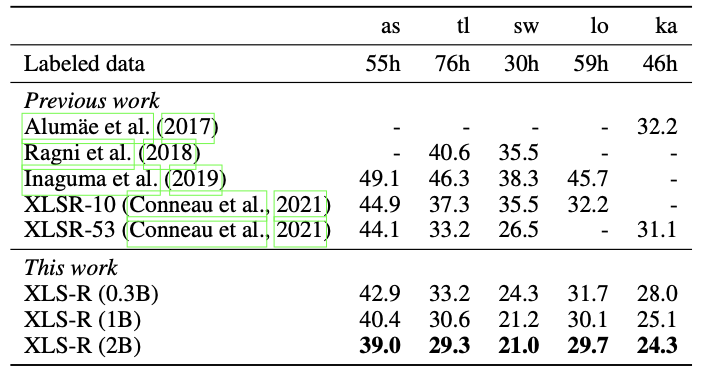 Speech recognition WER performance on BABEL
Speech recognition WER performance on BABEL
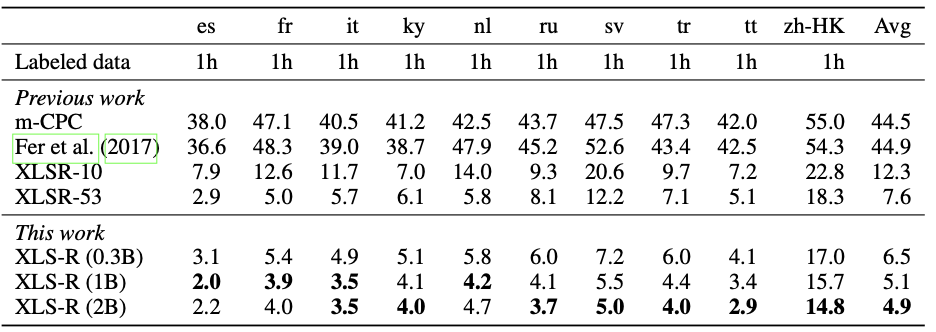 Phoneme recognition PER performance on CommonVoice
Phoneme recognition PER performance on CommonVoice
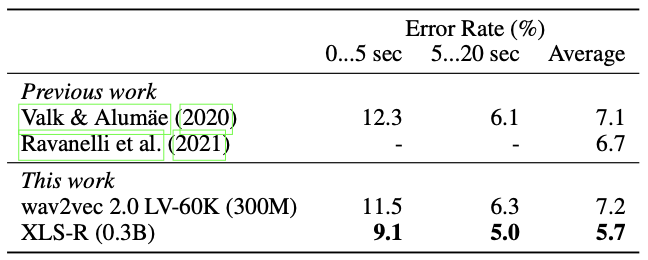 Language identification ER performance on VoxLingua107
Language identification ER performance on VoxLingua107
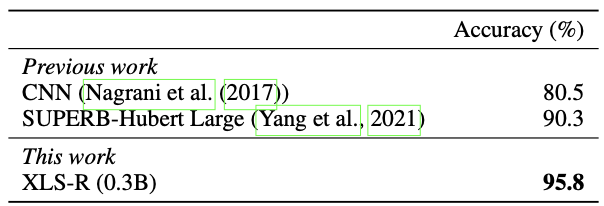 Speaker identification accuracy performance on VoxCeleb1
Speaker identification accuracy performance on VoxCeleb1
It can be seen that the pre-trained XLS-R outperforms most of the baseline methods in various speech tasks/datasets.