Significance
Keypoints
- Introduce a Mixture-of-Expert based large-scale language model
- Demonstrate performance of the proposed model by experiments
Review
Background
While scaling language models have brought unprecedented success in various natural language related tasks, training of large-scale model requires large number of data and compute. Energy consumption for training (and of course inferring from) these models are quite significant, and can be related to negative environmental/societal impact. The authors address this problem of high training power and compute of large-scale language models and bring Mixture-of-experts (MoE) to train 1.2T parameter model with fewer FLOPs and energy consumption when compared to the GPT-3.
Keypoints
Introduce a Mixture-of-Expert based large-scale language model
The proposed GLaM model architecture leverages sparsely activated MoE similar to the GShard A MoE layer is similar to that of the Transformer encoder layer, but the feed-forward network part is replaced by a Gating module which selects two most relevant from 64 experts.
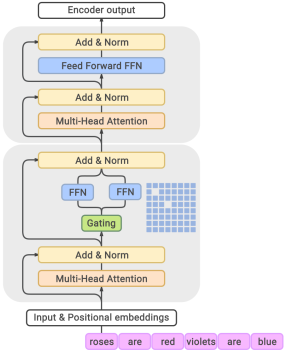 The GLaM model. The MoE layers (bottom) are interleaved with the Transformer layers (top)
The GLaM model. The MoE layers (bottom) are interleaved with the Transformer layers (top)
Other details on the model specification includes (i) replacing the positional embedding with per-layer relative positional bioas, (ii) replacing the first linear projection and the activation function with the Gated Linear Unit, and (iii) replacing the LayerNorm to RMSNorm.
Training dataset is newly built in this work, which consists of 1.6 trillion tokens with additional filtering algorithm for ensuring the quality of the text corpus.
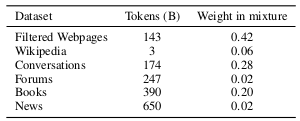 Data and mixture weights for training the GLaM
Data and mixture weights for training the GLaM
Training the GLaM model is very expensive due to the number of model parameters. Some training tricks that the authors employ are (i) training smaller-scale models to convergence first, (ii) skip weight updates for a minibatch containing NaN or Inf gradients and restart from an earlier healthy checkpoint. Details of the hyperparameters are referred to the original paper.
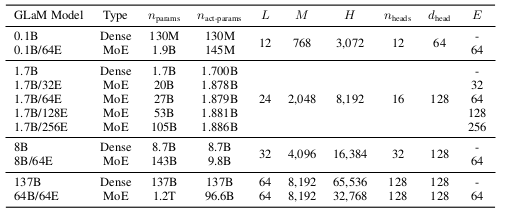 GLaM model specification
GLaM model specification
Demonstrate performance of the proposed model by experiments
Performance of the proposed model is evaluated with 29 datasets including 8 natural language generative (NLG) tasks and 21 natural language understanding (NLU) tasks. These datasets are further categorized into: (i) open-domain question answering, (ii) cloze and completion task, (iii) winograd-style tasks, (iv) common sense reasoning, (v) in-context reading comprehension, (vi) SuperGLUE, and (vii) natural language inference.
The results demonstrate that the proposed GLaM outperforms GPT-3 while requiring significantly lower compute during inference.
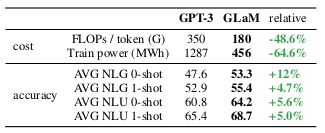 Comparison of GLaM and GPT-3 in terms of compute and performance
Comparison of GLaM and GPT-3 in terms of compute and performance
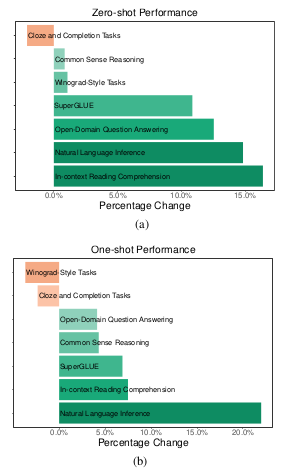 Percent change with respect to GPT-3 for (a) zero-shot and (b) one-shot performance
Percent change with respect to GPT-3 for (a) zero-shot and (b) one-shot performance
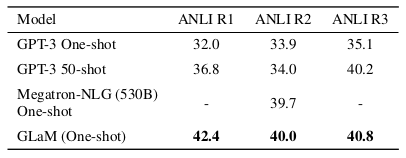 GLaM performance of natural language understanding on the ANLI benchmarks
GLaM performance of natural language understanding on the ANLI benchmarks
The GLaM model is also compared with its dense counterpart and the results suggest that GLaM with MoE layers performs better when the FLOPs are matched.
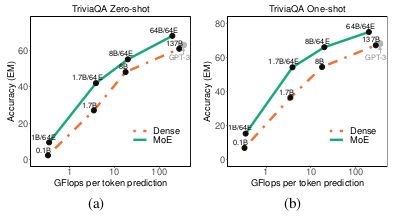 GLaM with MoE layer (proposed) compared with its dense counterpart on the TriviaQA zero-shot and one-shot tasks
GLaM with MoE layer (proposed) compared with its dense counterpart on the TriviaQA zero-shot and one-shot tasks
Effect of training data filtering for ensuring high quality corpus is experimented on the GLaM (1.7B64E) model by comparison. The results demonstrate that filtered training data produces better performing model, suggesting that the data quality should not be sacrificed for data quantity.
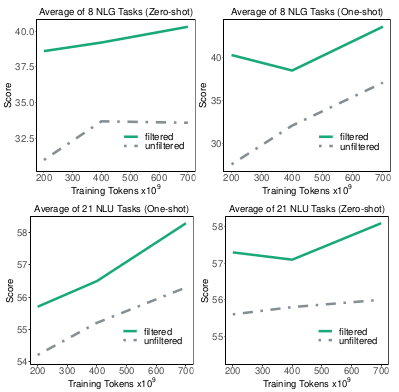 Effect of data filtering
Effect of data filtering
Experiments on the number of experts were also underwent, with the results suggesting that more experts generally leads to better performance.
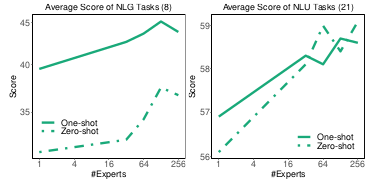 Number of experts and the zero-shot / one-shot performance
Number of experts and the zero-shot / one-shot performance
Finally, the authors provide evidences on better computation efficiency and energy consumption by comparing the TPU years of the GLaM model and its dense counterpart for achieving the same performance.
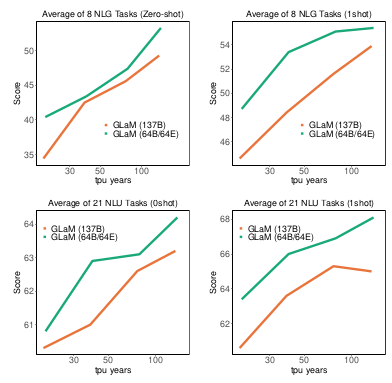 Average performance of GLaM with MoE layers and dense models with respect to the number of TPU years spent
Average performance of GLaM with MoE layers and dense models with respect to the number of TPU years spent
Further discussion regarding the societal impact is referred to the original paper.