Significance
Contrastive ViT Makes VLM Stronger
Review
The authors improve PaLI-based vision language model (VLM) by replacing the vision encoder from classification pre-trained ViT to a contrastive-pretrained ViT, the SigLIP. By introducing the SigLIP as the vision encoder, the authors show that the proposed PaLI-3 performs comparably on vision-language tasks to recent models with 10$\times$ larger parameters.
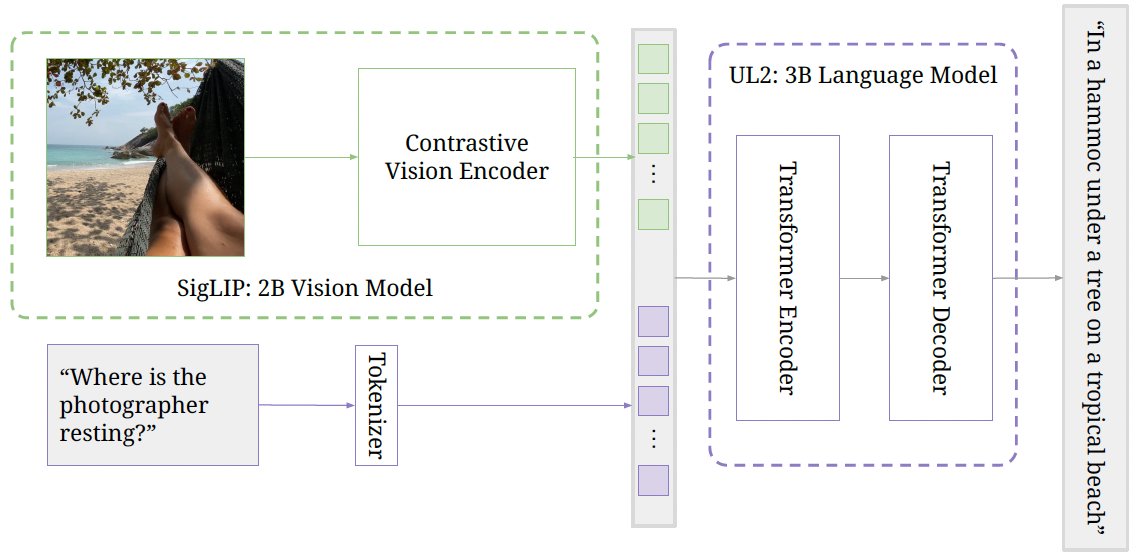 Diagram of the PaLI-3 VLM
Diagram of the PaLI-3 VLM