Significance
Review
The authors propose Visual Language Planning (VLP), which aims to enable visual planning for long horizon tasks. VLP exploits two large models and the tree search algorithm to realize this goal. Specifically, a vision-language model (PaLM-E) first takes an image and corresponding task instruction to generate action texts. The action texts are input into a text-to-video model to generate video rollouts of the future. These action text - video pairs are input to a vision-language model to evaluate and replace the least likely plans with tree-search. After these loops of planning, the optimal plan is executed with goal-conditioned policies.
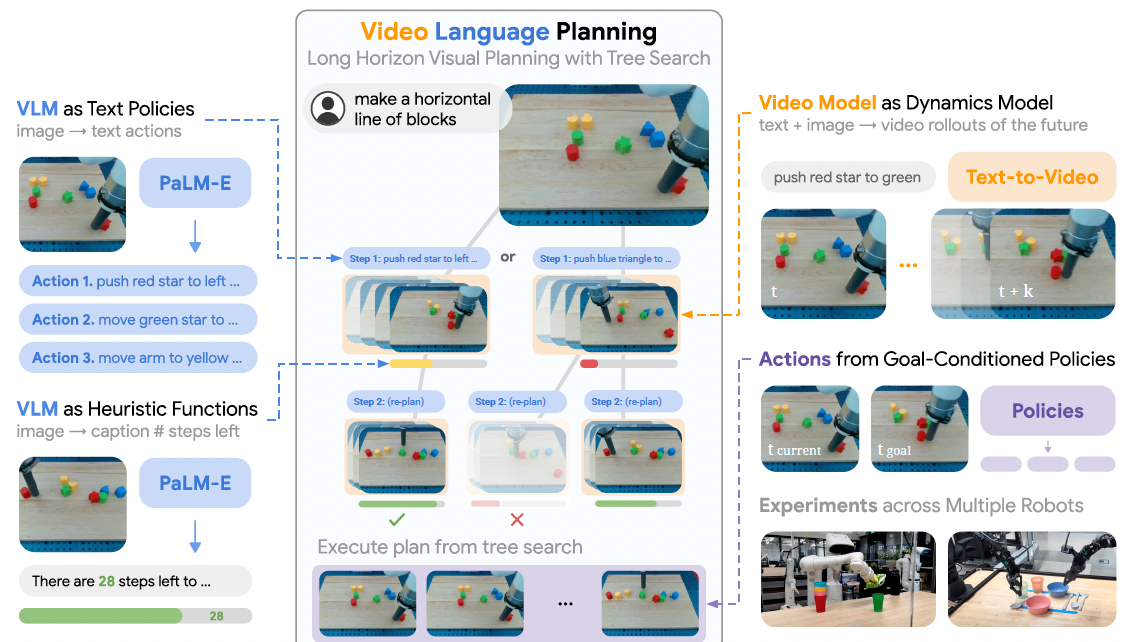 The Video Language Planning
The Video Language Planning
It can be seen from the demo videos of the project page that the proposed VLP shows an impressive performance in long horizon task planning.
Related
- A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
- Knowledge-Augmented Language Model Verification
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- PaLI-3 Vision Language Models: Smaller, Faster, Stronger
- Large Language Models Are Zero-Shot Time Series Forecasters