Significance
Keypoints
- Demonstrate performance of vision transformers with respect to scaling compute/model/dataset
- Improve performance and training efficiency of vision transformers heuristically
Review
Background
Vision transformers (ViTs) are fastly becoming a standard backbone model for solving computer vision tasks. While their robustness has been shown experimentally (see my previous post), not much is known about the effect of scaling the model. This work provides extensive experimental results on scaling the compute, model, and dataset for training the ViTs. Increasing the model and dataset size with heuristic improvements in training details achieve state-of-the-art top 1 accuracy for the image classification task on the ImageNet dataset.
Keypoints
Demonstrate performance of vision transformers with respect to scaling compute/model/dataset
Scaling up compute, model and data together
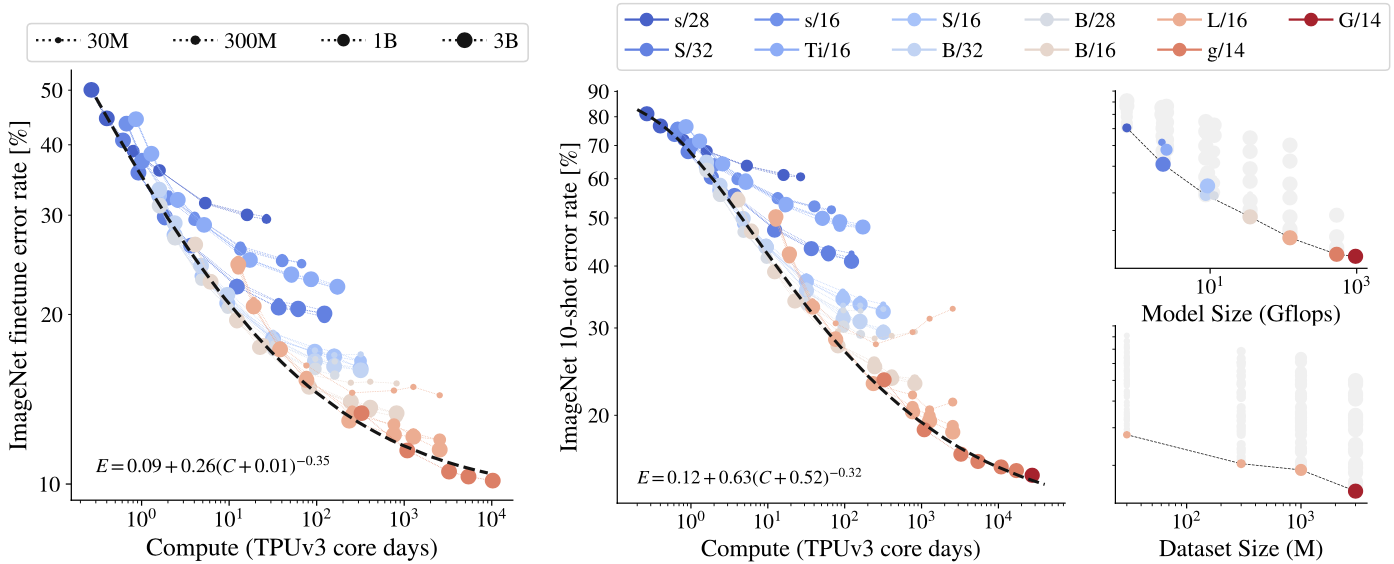 Scaling results of compute, model, and data
Left and center plots of the above figure present ImageNet finetune/10-shot error rate with respect to the total computation by TPU days.
Finetune refers to finetuning the model head of a pre-trained ViT, and 10-shot refers to training with 10 images per each class within the ImageNet dataset.
Both tasks demonstrate the representation quality of the trained ViT.
It can be seen that scaling up compute, model, and data together improves representation quality of the ViT.
On the upper-right plot of the above figure presents representation quality bottlenecked by model size, while the lower-right plot presents representation quality bottlenecked by dataset size.
These suggest that representation quality can be bottlenecked by model size and large models benefit from large dataset, beyond 1B images.
Scaling results of compute, model, and data
Left and center plots of the above figure present ImageNet finetune/10-shot error rate with respect to the total computation by TPU days.
Finetune refers to finetuning the model head of a pre-trained ViT, and 10-shot refers to training with 10 images per each class within the ImageNet dataset.
Both tasks demonstrate the representation quality of the trained ViT.
It can be seen that scaling up compute, model, and data together improves representation quality of the ViT.
On the upper-right plot of the above figure presents representation quality bottlenecked by model size, while the lower-right plot presents representation quality bottlenecked by dataset size.
These suggest that representation quality can be bottlenecked by model size and large models benefit from large dataset, beyond 1B images.
Big models are more sample efficient
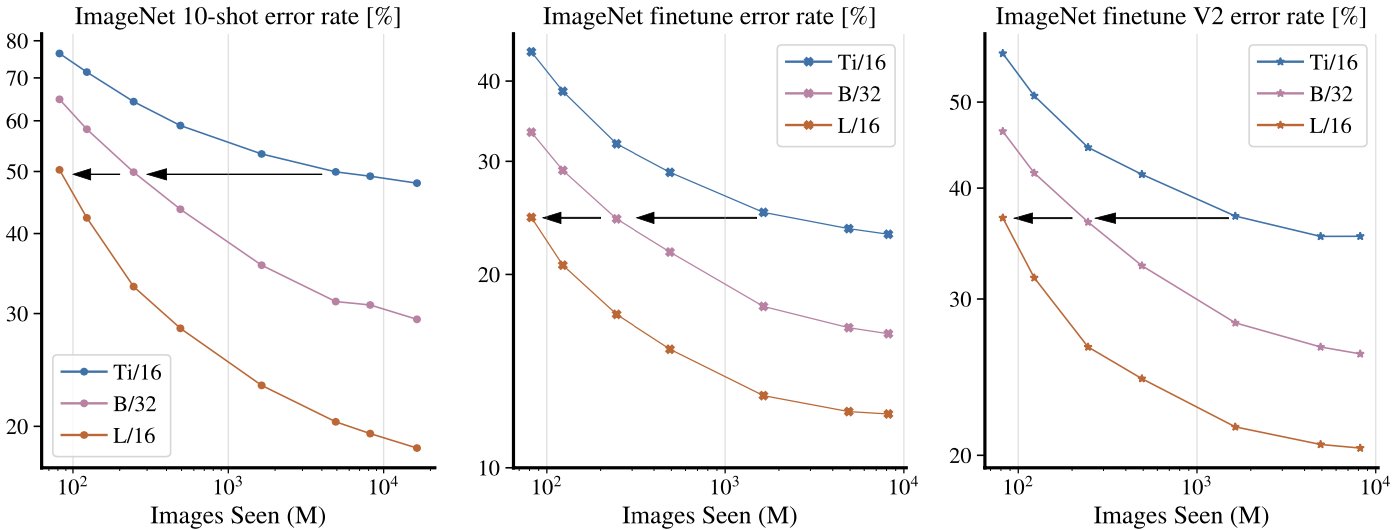 Training efficiency with respect to model size
Plots from the above figure show the the representation quality of ViTs with respect to the number of images seen during pre-training.
The plots suggest that bigger models (L > B > Ti) are more sample efficient.
Training efficiency with respect to model size
Plots from the above figure show the the representation quality of ViTs with respect to the number of images seen during pre-training.
The plots suggest that bigger models (L > B > Ti) are more sample efficient.
ViT-G/14 results
Based on the above findings, a giant ViT model ViT-G/14 which contains nearly two billion parameters is trained.
The ViT-G show significant improvement in few-shot learning on ImageNet dataset when compared to previous ViT-H model.
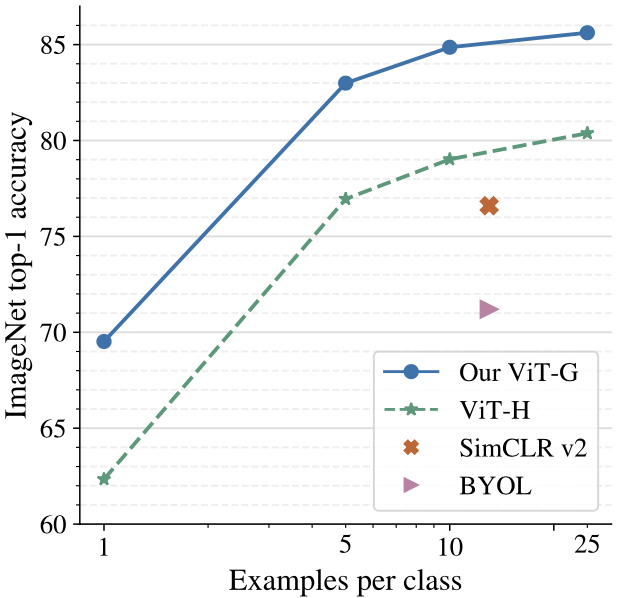 Few-shot learning results of ViT-G on ImageNet
Other tasks on various benchmark datasets including the ImageNet, ImageNet-v2, ReaL, ObjectNet, and VTAB-1k (transfer learning) demonstrate exceptional performance of the ViT-G/14.
In particular, the Vit-G/14 achieves state-of-the-art performance in ImageNet top-1 accuracy, reaching 90.45\%.
Few-shot learning results of ViT-G on ImageNet
Other tasks on various benchmark datasets including the ImageNet, ImageNet-v2, ReaL, ObjectNet, and VTAB-1k (transfer learning) demonstrate exceptional performance of the ViT-G/14.
In particular, the Vit-G/14 achieves state-of-the-art performance in ImageNet top-1 accuracy, reaching 90.45\%.
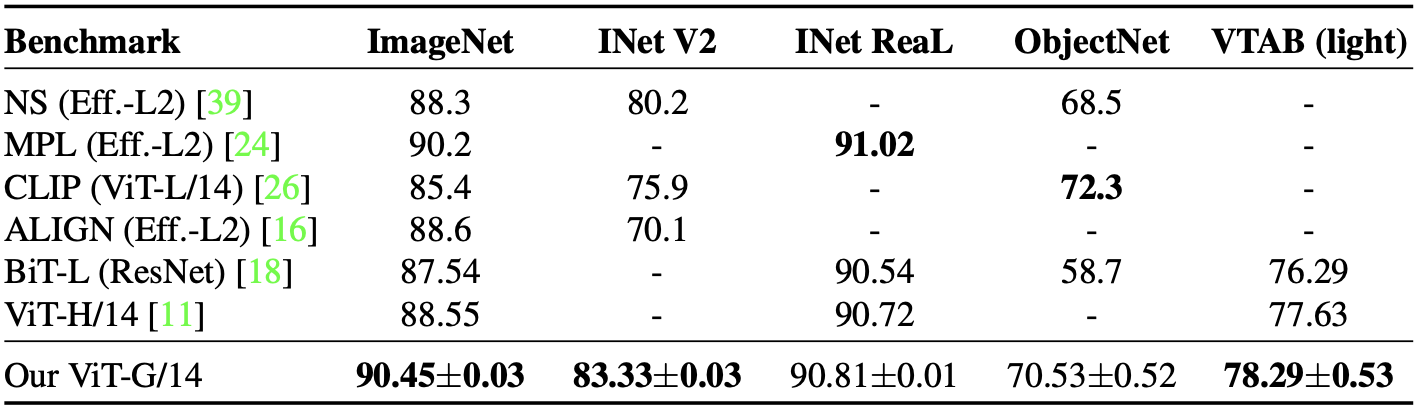 Performance of ViT-G in various benchmarks
Performance of ViT-G in various benchmarks
Improve performance and training efficiency of vision transformers heuristically
Decoupled weight decay for the “head”
The authors find that applying stronger weight decay regularization to the head (last linear layer) than the body of the ViTs can benefit few-shot learning performance.
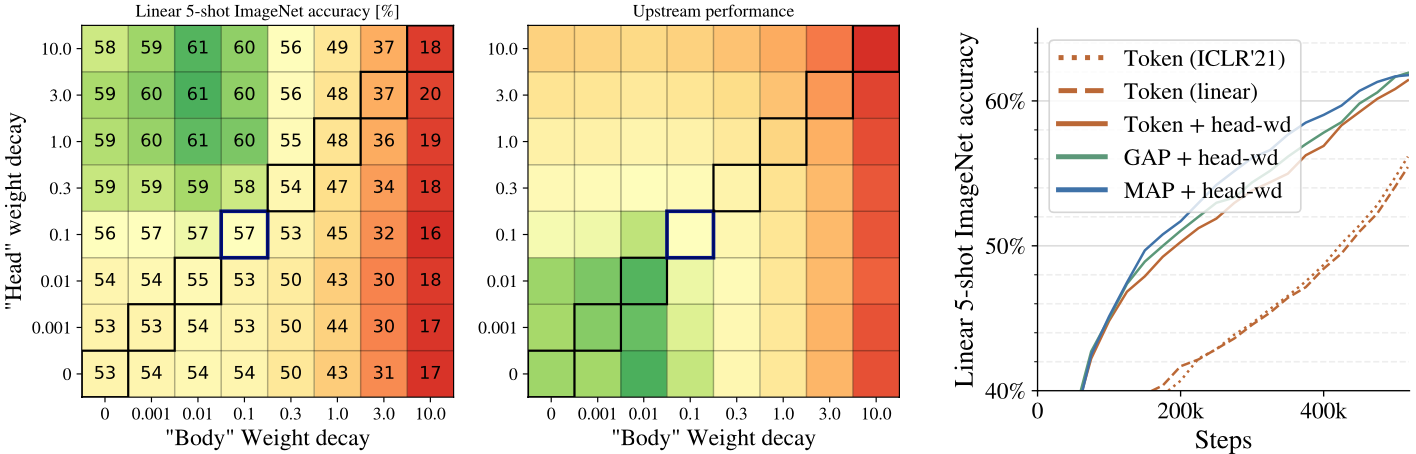 Head-body weight decay experiment / class token removal results
Head-body weight decay experiment / class token removal results
Saving memory by removing the [class] token
Scaling up ViTs require a large amount of computational resource. The authors evaluate replacing the extra class token with global average pooling (GAP) or multihead attention pooling (MAP) and show that these methods can perform similarly while being more memory efficient (right plot of the above figure). Accordingly, the MAP head is employed in training the ViT-G model.
Memory-efficient optimizers
Another detail for saving memory during training is to refine the optimizer. Adam optimizer requires storing two momentum parameters per each model parameter, resulting in an two-fold overhead. The authors modify Adam optimizer by (i) storing the first momentum parameter with half-precision and (ii) store second momentum using rank 1 factorization, reducing the memory overhead from 2 to 0.5.
Scaling up data
The authors use a proprietary dataset, called JFT-3B dataset, which is a larger version of the JFT-300M.
The JFT-3B dataset includes nearly 3 billion images annotated with around 30k class-hierarchy labels.
Training with the larger JFT-3B results in a better model.
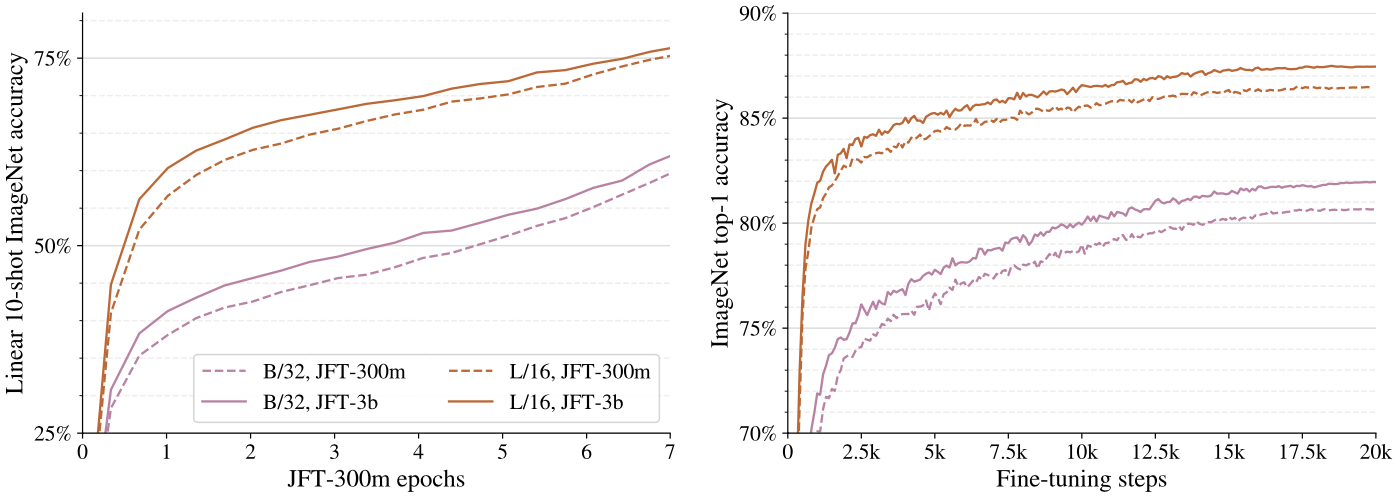 Trainiing with upscaled JFT-3B dataset
Trainiing with upscaled JFT-3B dataset
Learning-rate schedule
Learning-rate schedule with a cooldown schedule is experimented where the learning-rate is linearly annealed towards zero at the end of the training.
Between the warmup and the cooldown, the learning-rate is decayed slowly by using constant or reciprocal square-root schedule.
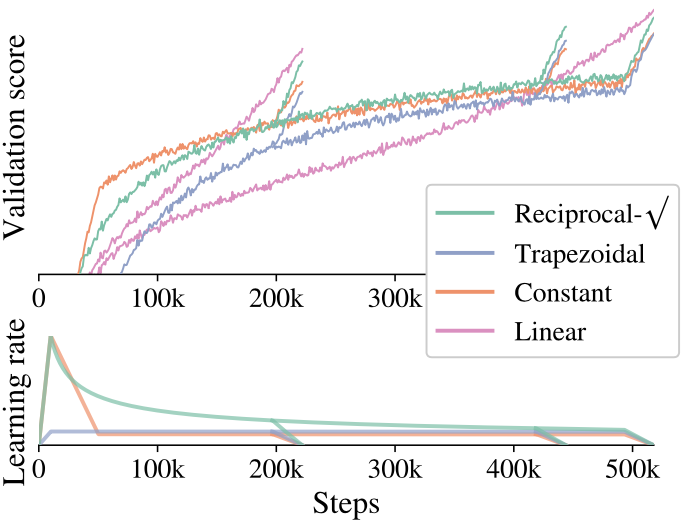 Learning-rate schedule and the validation score
The reciprocal square-root is chosen for based on the experimental results.
Learning-rate schedule and the validation score
The reciprocal square-root is chosen for based on the experimental results.
Selecting model dimensions
The scale of the model is selected by extensive experiments.
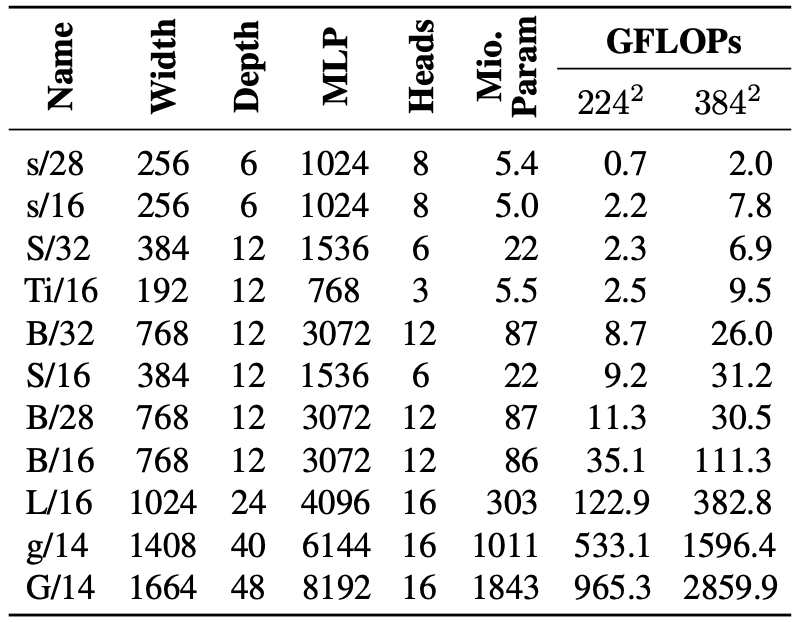 Model architecture details
A large amount of ViT models with various shapes/layers are compared and the recommended model is selected based on this result.
Model architecture details
A large amount of ViT models with various shapes/layers are compared and the recommended model is selected based on this result.
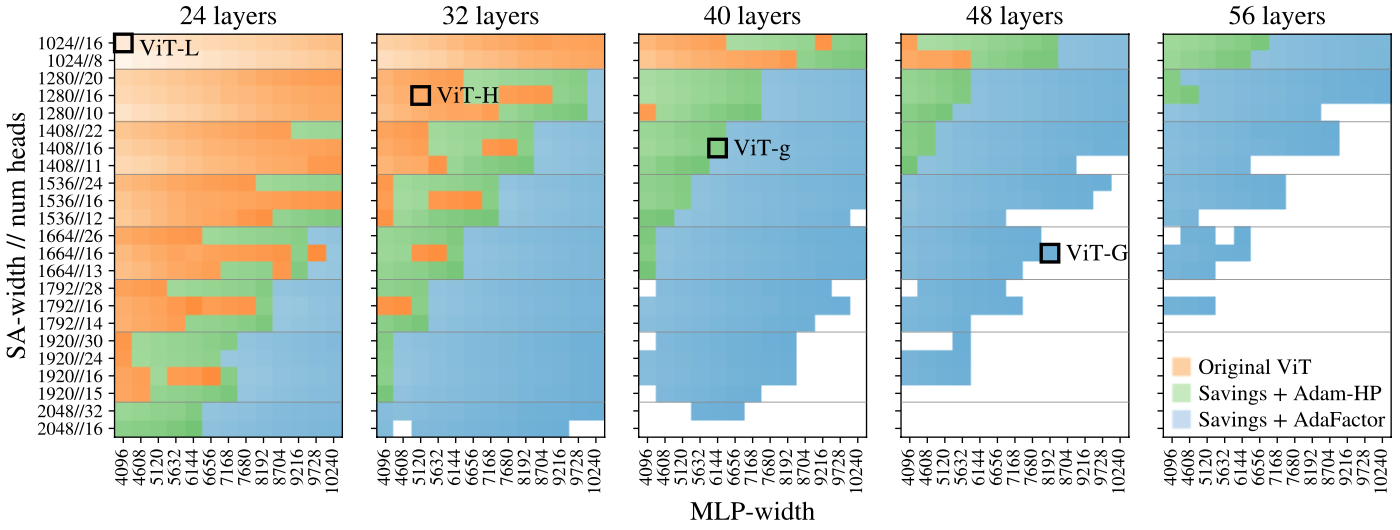 Results of model comparison. Brightness indicate training speed
Results of model comparison. Brightness indicate training speed
The paper includes a large amount of experimental results which requires large amount of computational / dataset resources. Optimistic results of scaling up ViTs in this work again leave us a question, “How far can scaling up AI models/datasets take us?”.
Related
- Efficient Large Scale Language Modeling with Mixture-of-Experts
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
- XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
- Mobile-Former: Bridging MobileNet and Transformer
- ViTGAN: Training GANs with Vision Transformers