Significance
Keypoints
- Propose methods for stabilizing GAN training with ViT based generator and discriminator
- Demonstrate image generation performance of the proposed method in low resolutions
Review
Background
Considering the recent trend in the computer vision field, it is not very surprising that attempts are being made to replace the convolution layers to self-attention modules for the generative adversarial networks (GANs) (see my previous review on a related work)
However, naively replacing the convolution layer to the vision transformer (ViT) style self-attention modules often faces unstable training and unsatisfactory results.
This paper studies the training unstability of the ViT based GANs, and propose methods to overcome these issues.
It should be noted that both the generator and the discriminator are free of convolutions in the proposed methods.
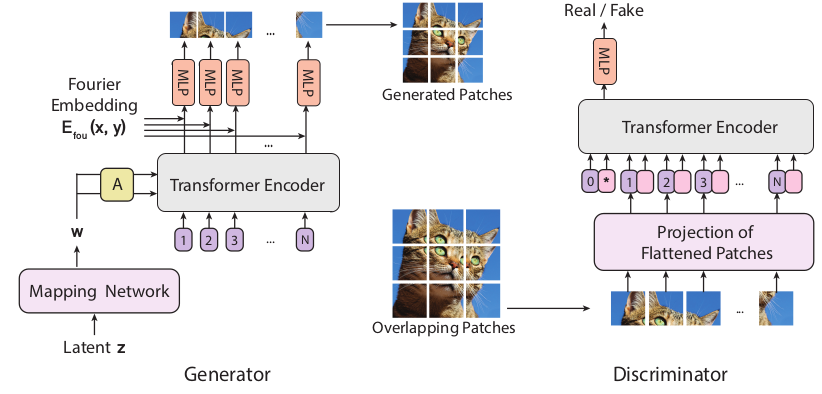 Schematic illustration of the proposed ViTGAN which is fully free from convolution layers
Schematic illustration of the proposed ViTGAN which is fully free from convolution layers
Keypoints
Propose methods for stabilizing GAN training with ViT based generator and discriminator
Lipschitz continuity of the discriminator
The main idea to stabilize the discriminator training follows the idea of Lipschitz continuity. Importance of the discriminator Lipschitz continuity was first addressed in the Wasserstein-GAN paper, and was further ensured easily by the Spectral Normalization. However, Lipschitz constant of standard dot product self-attention can be unbounded, so the dot product similarity is replaced with the Euclidean distance in this work: \begin{align} \text{Attention}_{h}(\mathbf{X}) = \mathrm{softmax}(\frac{d(\mathbf{XW}_{q}, \mathbf{XW}_{k})}{\sqrt{d_{h}}})\mathbf{XW}_{v},\quad \text{where}\mathbf{W}_{q}=\mathbf{W}_{k}, \end{align} where $d(\cdot , \cdot )$ is the vectorized L2 distance between the two points, $\sqrt{d_{h}}$ is the feature dimension of each head, $\mathbf{W}_{q}$, $\mathbf{W}_{k}$, and $\mathbf{W}_{v}$ are the projection matrices for query, key, and value, respectively.
To further strengthen the Lipschitz continuity of the discriminator, improved Spectral Normalization is applied by multiplying normalized weight matrix of each layer at initialization: \begin{align} W_{\text{ISN}}(\mathbf{W}) := \sigma(\mathbf{W}_{init}) \cdot \mathbf{W} / \sigma(\mathbf{W}). \end{align}
Design of the generator
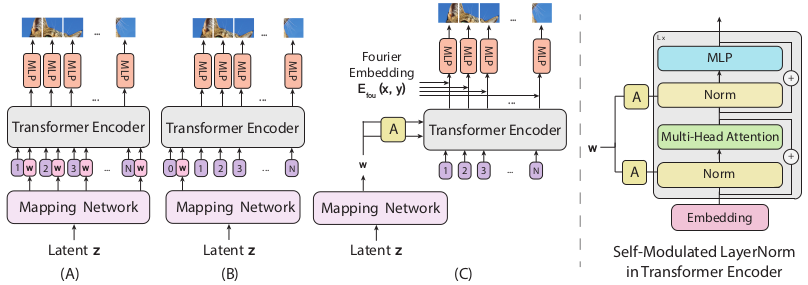 Design choices for the generator
ViT based generators can be implemented directly as the tokenized self-attention Transformer encoder as in the (A) and (B) of the above figure.
However, these baseline approaches fail to generate images of sufficient quality.
The authors propose to send the noise vector $\mathbf{z}$ to modulate the LayerNorm operation of the self attention module:
\begin{align}
\mathrm{SLN}(\mathbf{h}_{l}, \mathbf{w}) =\mathrm{SLN}(\mathbf{h}_{l},\text{MLP}(\mathbf{z})) = \gamma_{l}(\mathbf{w}) \odot \frac{\mathbf{h}_{l}-\mathbf{\mu}}{\mathbf{\sigma}}+\beta_{l} (\mathbf{w}).
\end{align}
Another trick is to use implicit neural representation to learn a continuous mapping from a patch embedding to patch pixel values, coupled with Fourier features.
The final design of the ViTGAN generator correspond to the (C) of the above figure.
Design choices for the generator
ViT based generators can be implemented directly as the tokenized self-attention Transformer encoder as in the (A) and (B) of the above figure.
However, these baseline approaches fail to generate images of sufficient quality.
The authors propose to send the noise vector $\mathbf{z}$ to modulate the LayerNorm operation of the self attention module:
\begin{align}
\mathrm{SLN}(\mathbf{h}_{l}, \mathbf{w}) =\mathrm{SLN}(\mathbf{h}_{l},\text{MLP}(\mathbf{z})) = \gamma_{l}(\mathbf{w}) \odot \frac{\mathbf{h}_{l}-\mathbf{\mu}}{\mathbf{\sigma}}+\beta_{l} (\mathbf{w}).
\end{align}
Another trick is to use implicit neural representation to learn a continuous mapping from a patch embedding to patch pixel values, coupled with Fourier features.
The final design of the ViTGAN generator correspond to the (C) of the above figure.
Demonstrate image generation performance of the proposed method in low resolutions
Image generation performance of the ViTGAN is compared with state-of-the-art GANs including the BigGAN+DiffAug and the StyleGAN2.
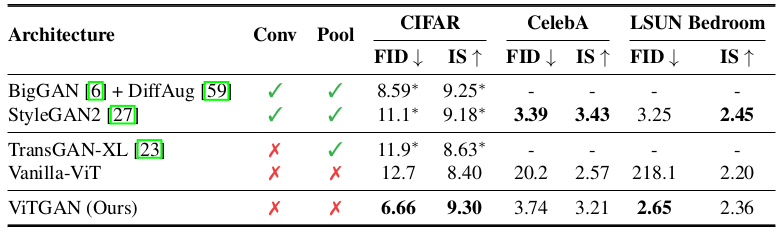 Quantitative result of the proposed method
It can be seen that the ViTGAN performs at least comparable to the baseline CNN GAN methods in terms of the FID and the Inception Score (IS).
Quantitative result of the proposed method
It can be seen that the ViTGAN performs at least comparable to the baseline CNN GAN methods in terms of the FID and the Inception Score (IS).
 Qualitative result of the proposed method
Examples of generated images are provided in the above figure.
Qualitative result of the proposed method
Examples of generated images are provided in the above figure.
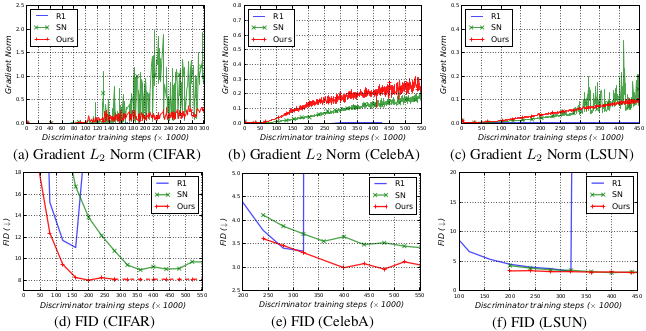 Training process of the proposed method
The training process of the proposed method is more stable than the baseline methods.
Training process of the proposed method
The training process of the proposed method is more stable than the baseline methods.
One limitation is that the proposed method is experimented only on generating low-resolution (upto 64$\times$64) images. However, this study still deserves its strengths in that the convolution layers are fully replaced to the self-attention modules in both the generator and the discriminator. Further ablation study results are referred to the original paper.