Significance
Keypoints
- Propose a method that combines MobileNet and ViT by parallel bridging
- Demonstrate efficiency and performance of the proposed method on image classification and image detection tasks
Review
Background
Although vision transformers (ViTs) have proven its performance in various computer vision tasks, lower computational efficiency and need for large-scale dataset is still a drawback of the model. This inefficiency is thought to come from the inability of ViTs to incorporate local information from the image data. To address this issue, many attempts have been made to inject locality prior to ViTs, or explicitly add convolution layers to the framework. The authors also try to tackle this limitation of ViTs, but not by merging convolution layers, but by bridging them to introduce locality. More specifically, the authors propose Mobile-Former, which consists of a MobileNet and a ViT with mobile-to-former and former-to-mobile bridge.
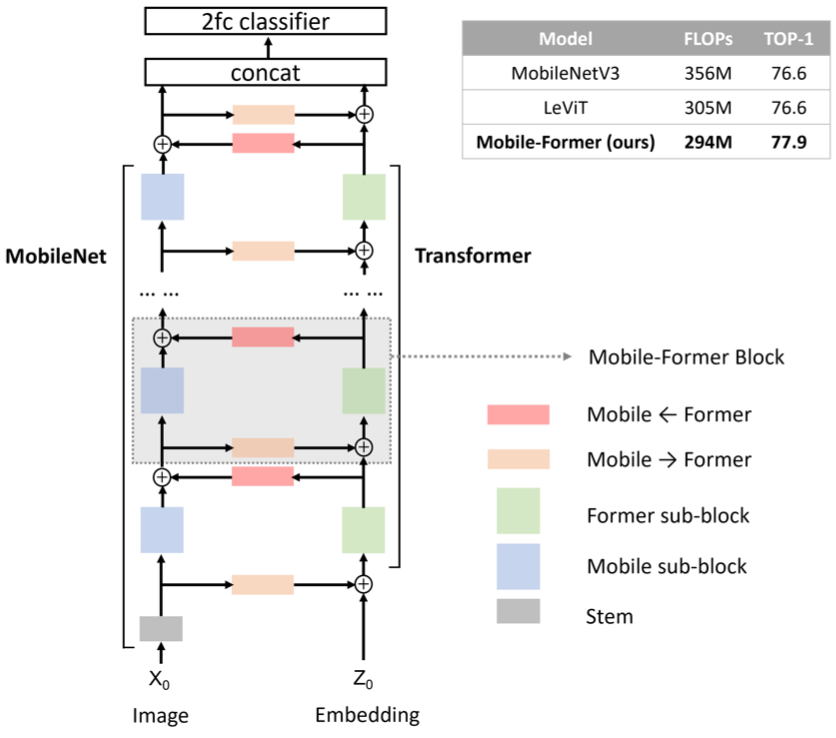 Schematic illustration of the proposed method Mobile-Former
Schematic illustration of the proposed method Mobile-Former
Keypoints
Propose a method that combines MobileNet and ViT by parallel bridging
The proposed Mobile-Former is a stack of Mobile-Former blocks, which includes four sub-blocks, Mobile sub-block, Former sub-block, Mobile$\rightarrow$Former sub-block, and Former$\rightarrow$Mobile sub-block. Mobile sub-block is a MobileNet style convolution layers with depthwise convolution, while the Former sub-block is a ViT style multi-head attention with feedforward network. The two bridges, Mobile$\rightarrow$Former and Former$\rightarrow$Mobile are key-query style attention which takes latent of the current sub-block serves as the key and the value vectors.
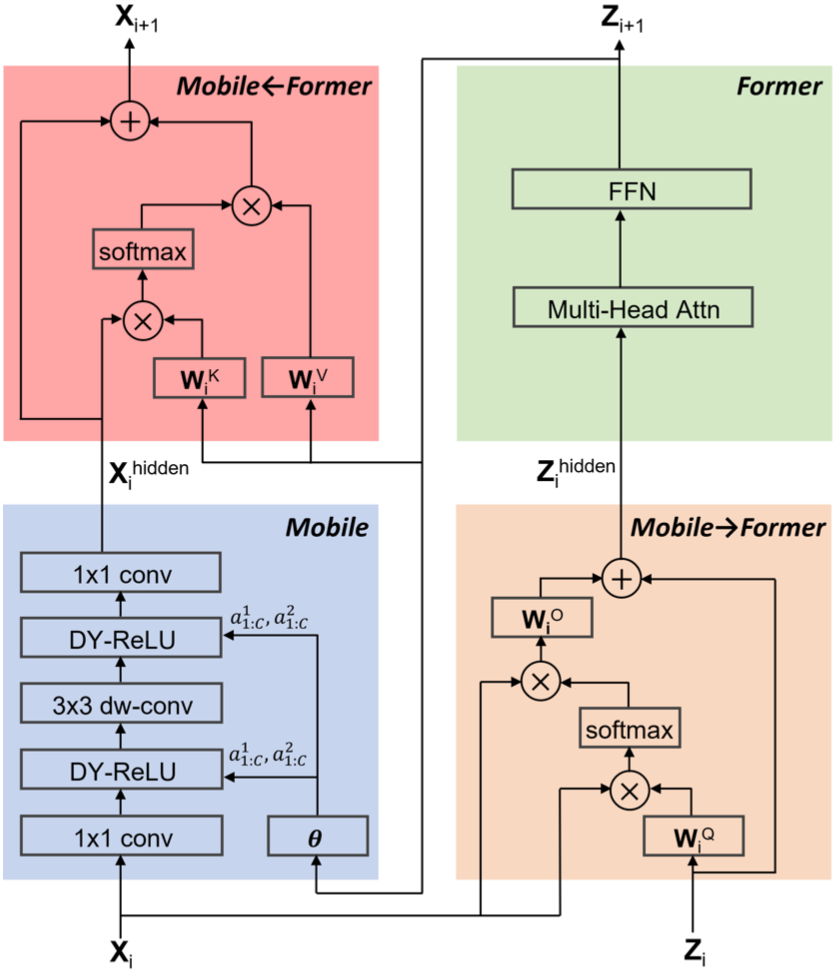 Mobile-Former block and its four sub-blocks
Mobile-Former block and its four sub-blocks
An example specification of Mobile-Former with 294M MAdds is as follows
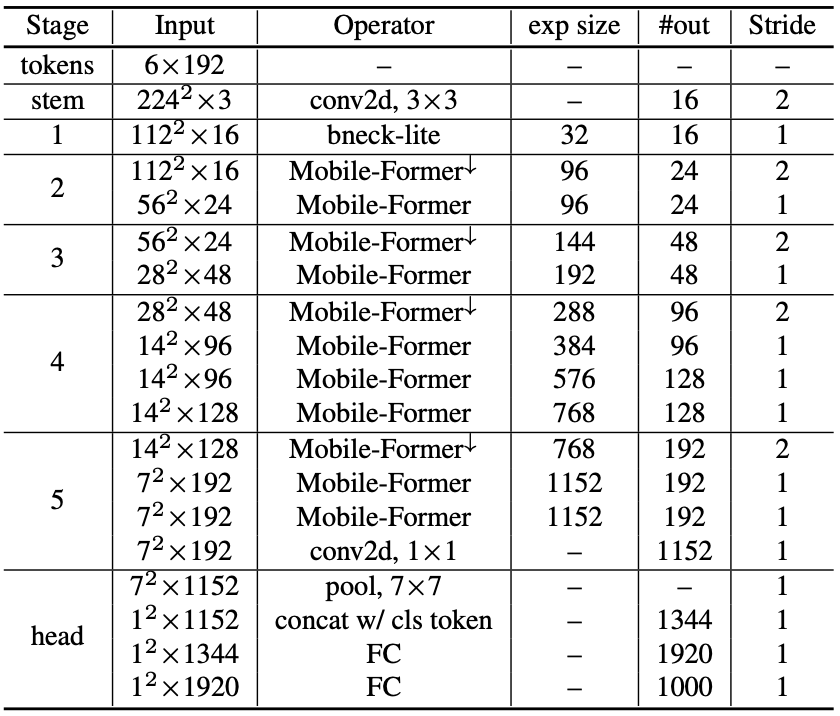 Mobile-Former-294M specification
Mobile-Former-294M specification
Demonstrate efficiency and performance of the proposed method on image classification and image detection tasks
The Mobile-Former with 26M, 52M, 96M, 151M, 214M, 294M, and 508M MAdds are compared with computational complexity matched efficient CNNs (MobileNet, ShuffleNet, EfficientNet) or ViTs for image classification task on ImageNet dataset.
 Performance of Mobile-Former compared to computational complexity matched CNNs
Performance of Mobile-Former compared to computational complexity matched CNNs
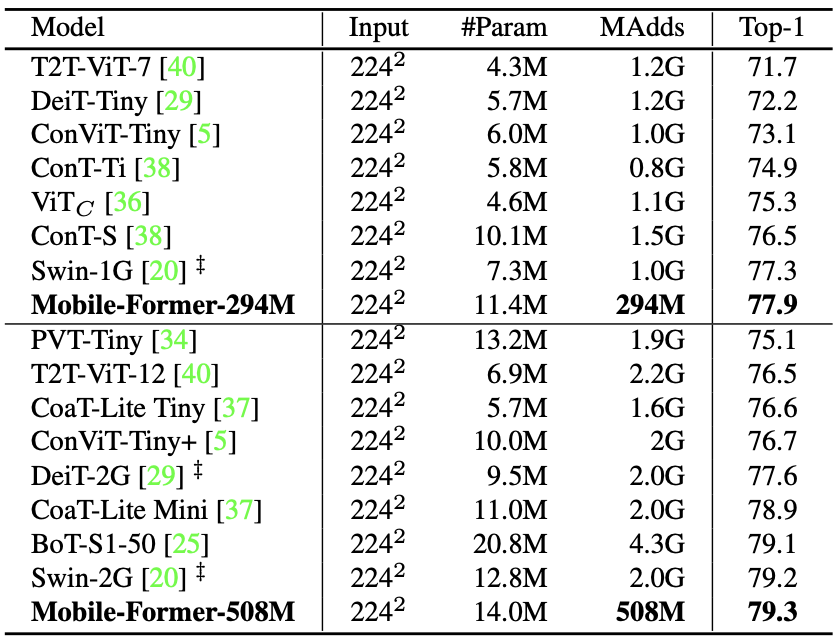 Performance of Mobile-Former compared to ViT variants
Performance of Mobile-Former compared to ViT variants
Performance of the proposed Mobile-Former is also tested on the COCO 2017 object detection task.
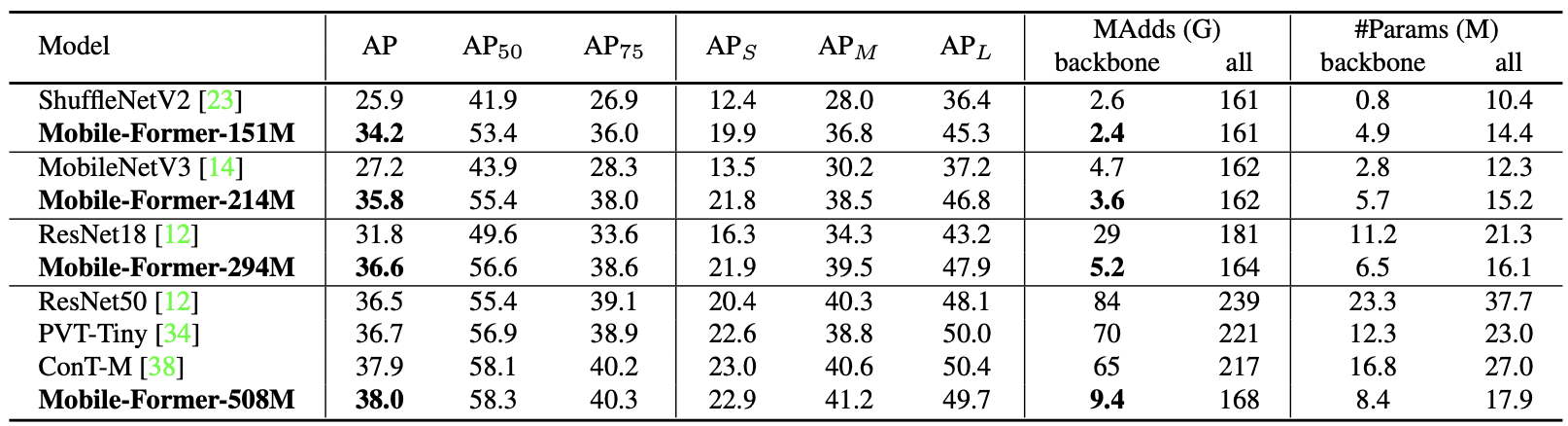 Performance of Mobile-Former on COCO object detection task
Performance of Mobile-Former on COCO object detection task
It can be seen that the Mobile-Former outperforms CNN and ViT variants on both object detection and image classification tasks while being computationally efficient.
Further ablation and explainability study results are referred to the original paper.