Significance
Keypoints
- Propose a vision transformer with self-attention across features
- Demonstrate performance of the proposed method for various computer vision tasks
Review
Background
Vision transformers (ViTs) are a family of models based on self-attention Transformers with promising results on computer vision tasks (see my previous post on performance and robustness of ViTs). However, one of the practical limitation of ViTs is that the time and memory complexity increases quadratically with the number of input tokens (i.e. image size) for computing the self-attention. The authors address this issue by applying self-attention across the features rather than the input tokens, which reduces the complexity to become linear with the number of input tokens. This is based on the observation that the self-attention correspond to computing a Gram matrix, which contains all pairwise inner products. The cross-covariance matrix correspond to the transpose of the Gram matrix and shares important properties with it, such as that non-zero part of the eigenspectrum are equivalent. This motivates applying self-attention across the features, which correspond to computing the cross-covariance matrix instead of the Gram matrix of the input tokens.
Keypoints
Propose a vision transformer with self-attention across features
The cross-covariance image Transformer (XCiT) layer consists of three blocks, each preceded by LayerNorm and followed by a residual connection.
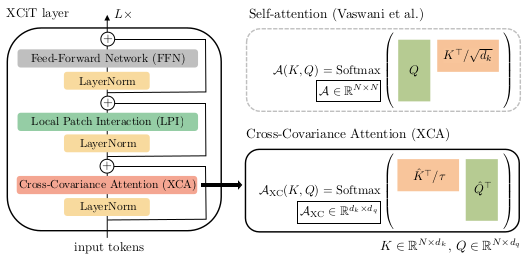 Schematic illustration of the proposed XCiT layer
Schematic illustration of the proposed XCiT layer
Cross-covariance attention
The cross-covariance attention (XCA) correspond to the self-attention layer in the original Transformer. The XCA layer computes self-attention across the feature dimension separated by a group of $h$ blocks as in the GroupNorm. This block-diagonal approach is easier to optimize and the complexity is reduced by the factor of $h$. Other differences from the original Transformer include $\mathcal{l}_{2}$-normalization and learnable temprature scaling. A Transformer with $h$ heads has a time complexity of $\mathcal{O}(N^{2} d)$ and memory complexity of $\mathcal{O}(h N^{2} N d)$, where $N$ is the number of input tokens and $d$ is the length of the feature dimension. The time and memory complexity of XCA are $\mathcal{O}(N d^{2} / h)$ and $\mathcal{O}(d^{2} / h + N d)$, respectively, scaling much better to the cases where the number of input tokens is large.
Local patch interaction
As interaction between the input image patches are not explicitly modeled through the XCA blocks, additional local patch interaction (LPI) blocks are introduced after each XCA block. The LPI block consists of two 3$\times$3 depth-wise convolution layers.
Feed-forward network
The feed-forward network (FFN) follows the original Transformer to have a single hidden layer with $4d$ hidden units. Global aggregation of the patch embeddings utilize the class attention layer approach.
Demonstrate performance of the proposed method for various computer vision tasks
The XCiT is experimented for various computer vision tasks, including image classification, object detection and semantic segmentation.
Image classification
Image classification performance is evaluated on the ImageNet-1k dataset.
Comparison with EfficientNet, NFNet, RegNet, DeiT, Swin-T, CaiT demoenstrate state-of-the-art performance of the proposed XCiT.
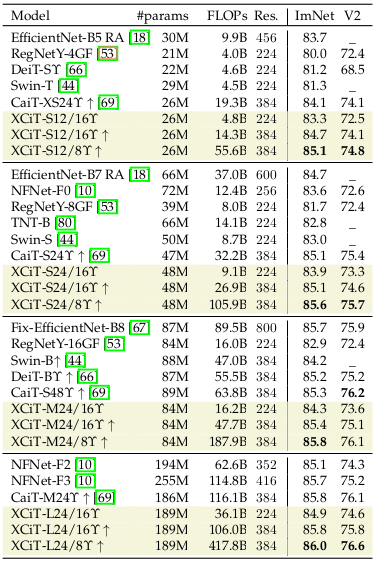 Top 1 accuracy results of XCiT on ImageNet
Top 1 accuracy results of XCiT on ImageNet
This excellent performance of XCiT also comes with computational efficiency and robustness to resolution changes.
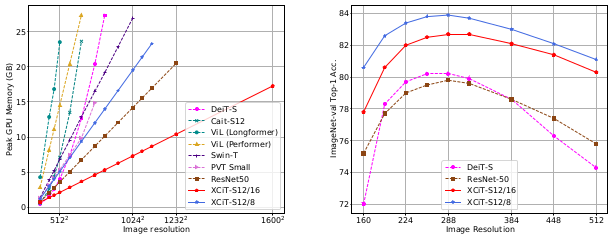 Computational efficiency (left) and robustness to image resolution (right) of XCiT
Computational efficiency (left) and robustness to image resolution (right) of XCiT
Visualization of the class attention show semantically coherent being attended by the XCiT.
 Visualization of the class attention
Visualization of the class attention
The XCiT even works well with the self-supervised learning methods, demonstrated by comparison with MoBY-SwinT and DINO.
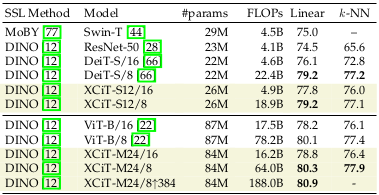 Performance of self-supervised learning with XCiT
Performance of self-supervised learning with XCiT
Ablation study results are referred to the original paper
Object detection
Computational efficiency of the XCiT makes it suitable for dense prediction tasks.
The results of object detection and instance segmentation on COCO dataset suggests the capability of XCiT for these tasks.
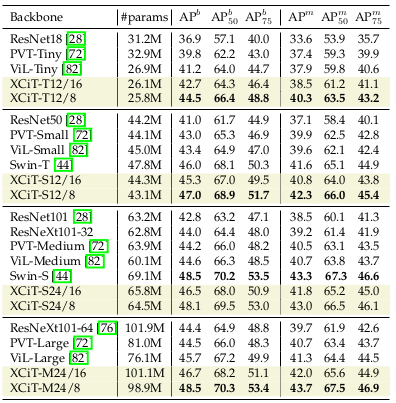 Object detection / instance segmentation results on COCO dataset
Object detection / instance segmentation results on COCO dataset
Semantic segmentation
The transferability of XCiT is further shown by semantic segmentation experiments on the ADE20k dataset.
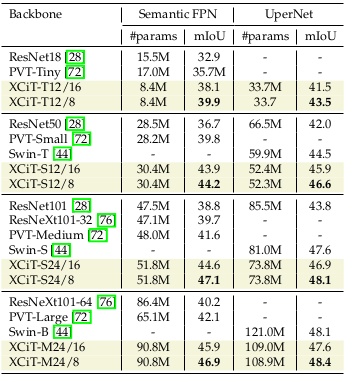 Semantic segmentation results on ADE20k dataset
Semantic segmentation results on ADE20k dataset
It can be said that the XCiT shows better, or at least comparable results with linear computational complexity on various computer vision task. However, it should also be noted that the architecture of the XCiT might be closer to a depth-wise convolution neural network with channel attention, rather than a self-attention ViT free from convolution layers.