Significance
Keypoints
- Show robustness of vision transformer in terms of input perturbations
- Show robustness of vision transformer in terms of model perturbations
Review
Background
Interest in Transformers for its application to computer vision problems has been explosive since the introduction of the Vision Transformer (ViT). Many attempts are being made to apply ViT-like models to solve various real-life problem. But are ViTs safe? This work addresses that the robustness of ViT has not been extensively studied by far, and experiments are in need to deploy this type of model safely. Robustness of ViT with respect to the ResNet in terms of input perturbations and model perturbations are confirmed by a wide range of experiments.
Keypoints
Show robustness of vision transformer in terms of input perturbations
The robustness of ViT to input perturbations is studied with the following model settings.
 Models used for the experiments
Models used for the experiments
The first result presents robustness of the ViT and ResNet models with datasets that include natural corruptions (ImageNet-C), real-world distribution shifts (ImageNet-R), and natural adversarial examples (ImageNet-A).
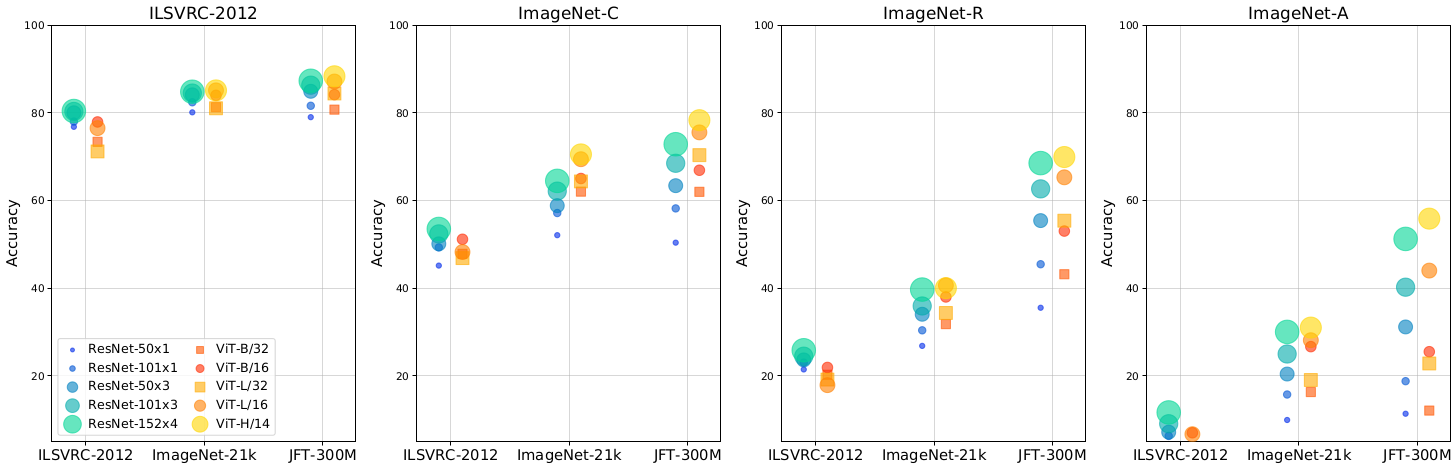 Input perturbation robustness
Results confirm the robustness of ViT for various input perturbations when compared to ResNet.
Input perturbation robustness
Results confirm the robustness of ViT for various input perturbations when compared to ResNet.
Study on adversarial perturbations including two standard approaches to compute the perturbation (FGSM, PGD) and the spatial transformation (rotation, translation) also confirmed the robustness of the ViT
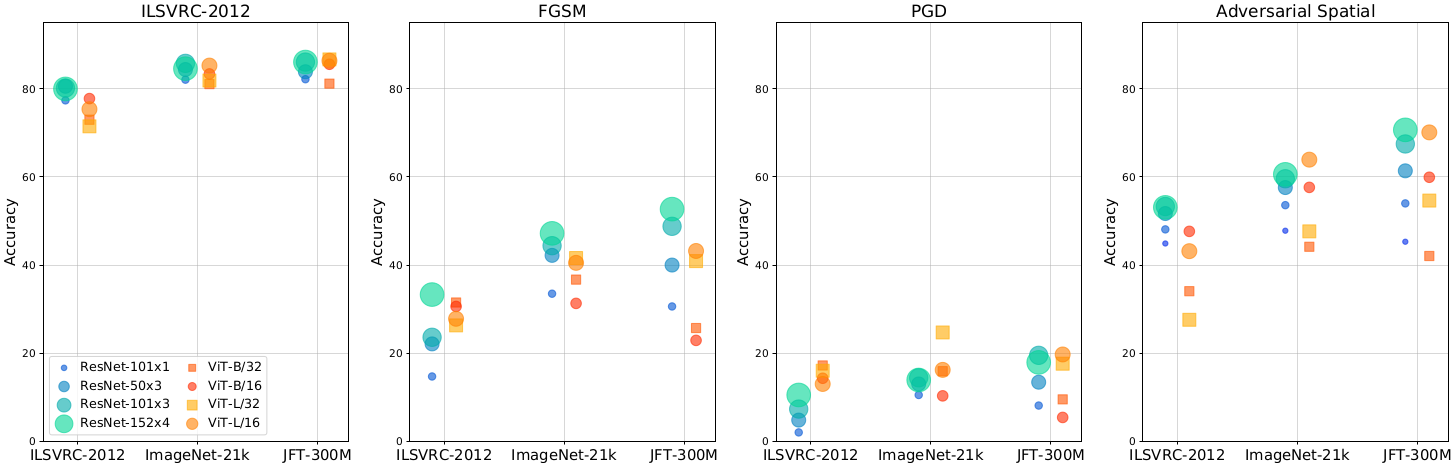 Adversarial perturbation robustness
Adversarial perturbation robustness
It is additionally demonstrated that scaling up the ViT results in a faster trend of error rate decrement when compared to the ResNet, irrespective of the type of input perturbation.
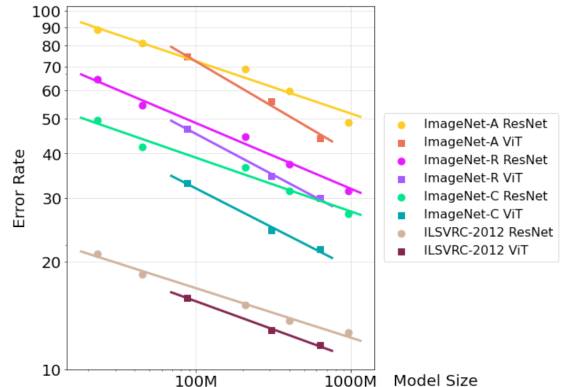 Scaling up and model performance
This might suggest the rich potential of the ViT when trained on large datasets, but also can mean that the ViT should be used with caution when the number of data is limited.
Scaling up and model performance
This might suggest the rich potential of the ViT when trained on large datasets, but also can mean that the ViT should be used with caution when the number of data is limited.
Show robustness of vision transformer in terms of model perturbations
Robustness of the ViT is studied with respect to model perturbations.
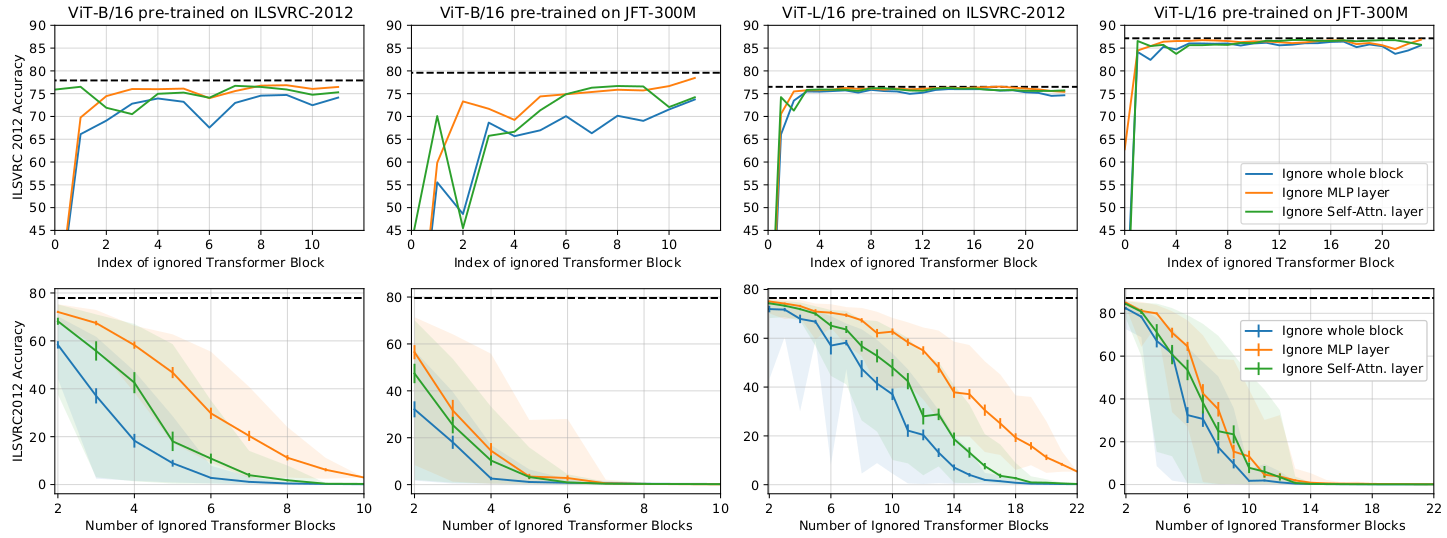 Model perturbation robustness
When a whole block, or one of its components (MLP, self-attention layer) is removed from the pre-trained ViT model, classification accuracy was still comparable to that of the full model (except for the first block of the ViT).
Further removing several blocks while keeping the first block showed gradual decrement of the classification performance.
The results indicate the existence of redundancy within the ViT, especially for larger models.
The model redundancy is also studied by the authors as the layer correlation, which is not discussed in this post.
Model perturbation robustness
When a whole block, or one of its components (MLP, self-attention layer) is removed from the pre-trained ViT model, classification accuracy was still comparable to that of the full model (except for the first block of the ViT).
Further removing several blocks while keeping the first block showed gradual decrement of the classification performance.
The results indicate the existence of redundancy within the ViT, especially for larger models.
The model redundancy is also studied by the authors as the layer correlation, which is not discussed in this post.
The last experiment is done by restricting the attention between the patches that lie within a certain distance.
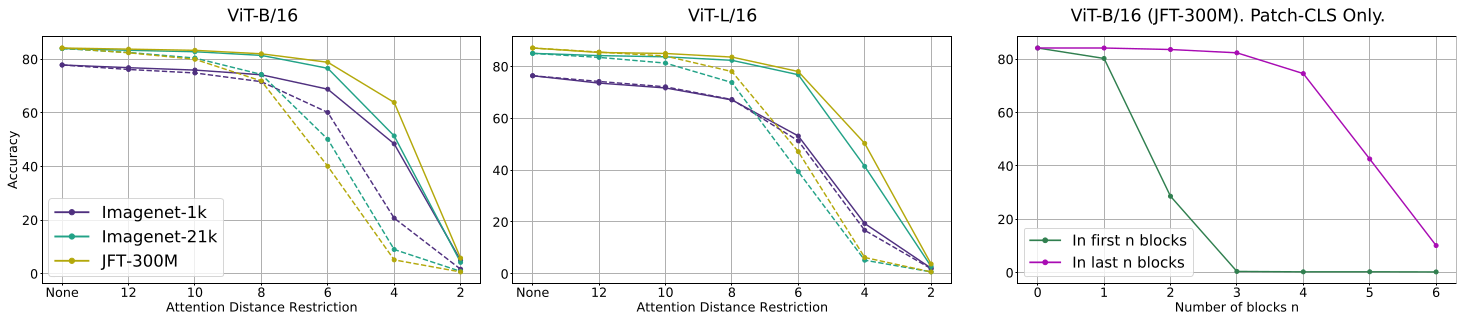 Attention restriction robustness
The degradation of performance is not apparent until the restriction becomes tight enough to a certain level.
This phenomenon might be related to the (non-)locality inductive bias of the ViT models discussed in my previous post.
Attention restriction robustness
The degradation of performance is not apparent until the restriction becomes tight enough to a certain level.
This phenomenon might be related to the (non-)locality inductive bias of the ViT models discussed in my previous post.