Significance
Keypoints
- Propose a self-attention layer which can compensate locality
- Show sample-efficiency of the model
- Investigate importance and tendency of locality in vision-transformers
Review
Background
Replacing the convolution layer with the self-attention layer (a.k.a. Transformer encoder) for solving computer vision tasks has been an active topic of research since the introduction of the Transformer. The Vision Transformer (ViT) makes use of the self-attention layer without any convolution operation, and achieves a performance comparable to the SOTA for the image classification task. Attempts are being made to further improve the ViT-based models, and this work claims that sample-efficiency is achieved by soft injecting of the locality inductive bias (as in the convolution layers) to the self-attention layer, which is inherently non-local.
Keypoints
Propose a self-attention layer which can compensate locality
The Positional Self-Attention (PSA) layer is defined as following: \begin{equation*} \boldsymbol{A}^{h} _ {ij} := \texttt{softmax} (\boldsymbol{Q}^{h} _ {i} \boldsymbol{K}^{h\top} _ {j} + \boldsymbol{v}^{h\top} _ {pos}\boldsymbol{r} _ {ij}) \end{equation*}
The authors note that summation of the two terms on the right-hand-side of the equation can lead to simply ignoring the smaller of the two because of the softmax function.
The two terms respectively represent the content and position of the image (or patch of the image), and it is better not to ignore either one.
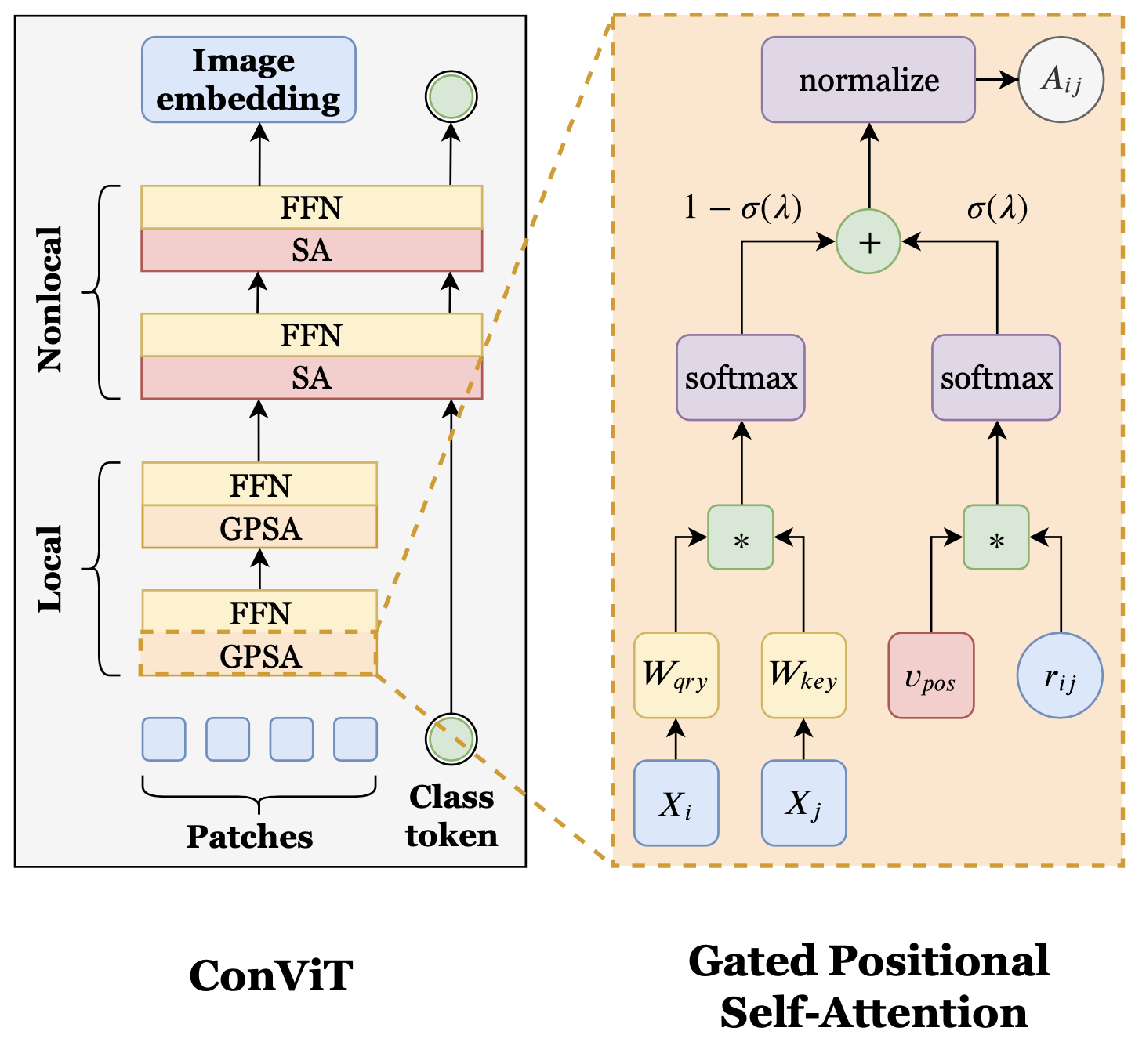 Proposed ConViT and GPSA
Gated Positional Self-Attention (GPSA) layer is proposed as a linear interpolation of the content and the position after the softmax function to address this issue.
To inject locality inductive bias at the beginning of the training, the GPSA layer is initialized to mimic convolution layer based on a previous finding.
Finally, the proposed ConViT consists of 10 blocks of GPSA layer followed by 2 blocks of conventional self-attention layer, and progressively gains non-locality throughout the training.
Proposed ConViT and GPSA
Gated Positional Self-Attention (GPSA) layer is proposed as a linear interpolation of the content and the position after the softmax function to address this issue.
To inject locality inductive bias at the beginning of the training, the GPSA layer is initialized to mimic convolution layer based on a previous finding.
Finally, the proposed ConViT consists of 10 blocks of GPSA layer followed by 2 blocks of conventional self-attention layer, and progressively gains non-locality throughout the training.
Show sample-efficiency of the model
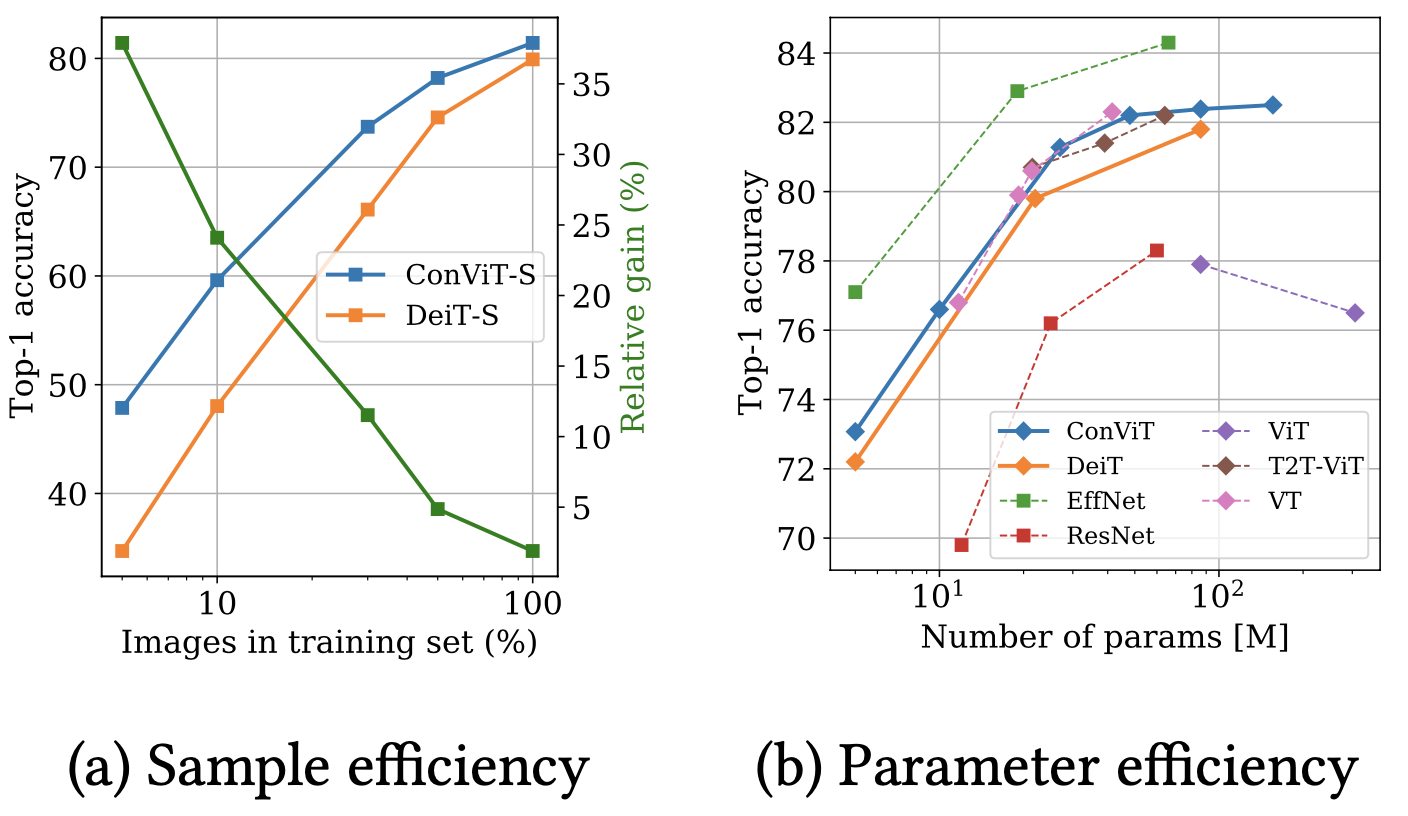 Sample and parameter efficiency of ConViT
The authors show that the proposed ConViT has advantage over DeiT in both sample and parameter efficiency.
It is mentioned in the paper that the efficiency might come from the convolutional initialization of the GPSA layers.
Sample and parameter efficiency of ConViT
The authors show that the proposed ConViT has advantage over DeiT in both sample and parameter efficiency.
It is mentioned in the paper that the efficiency might come from the convolutional initialization of the GPSA layers.
Investigate importance and tendency of locality in vision-transformers
The tendency of (non-)locality in ConViT throughout the training,
and its importance regarding the classification performance
are presented as experiment results.
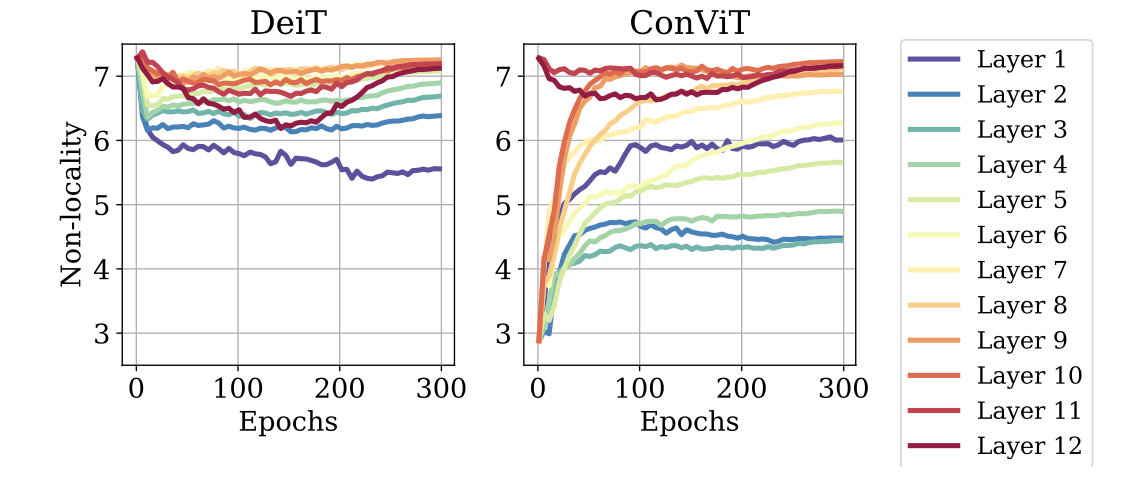 Tendency of non-locality in ConViT
Tendency of non-locality in ConViT
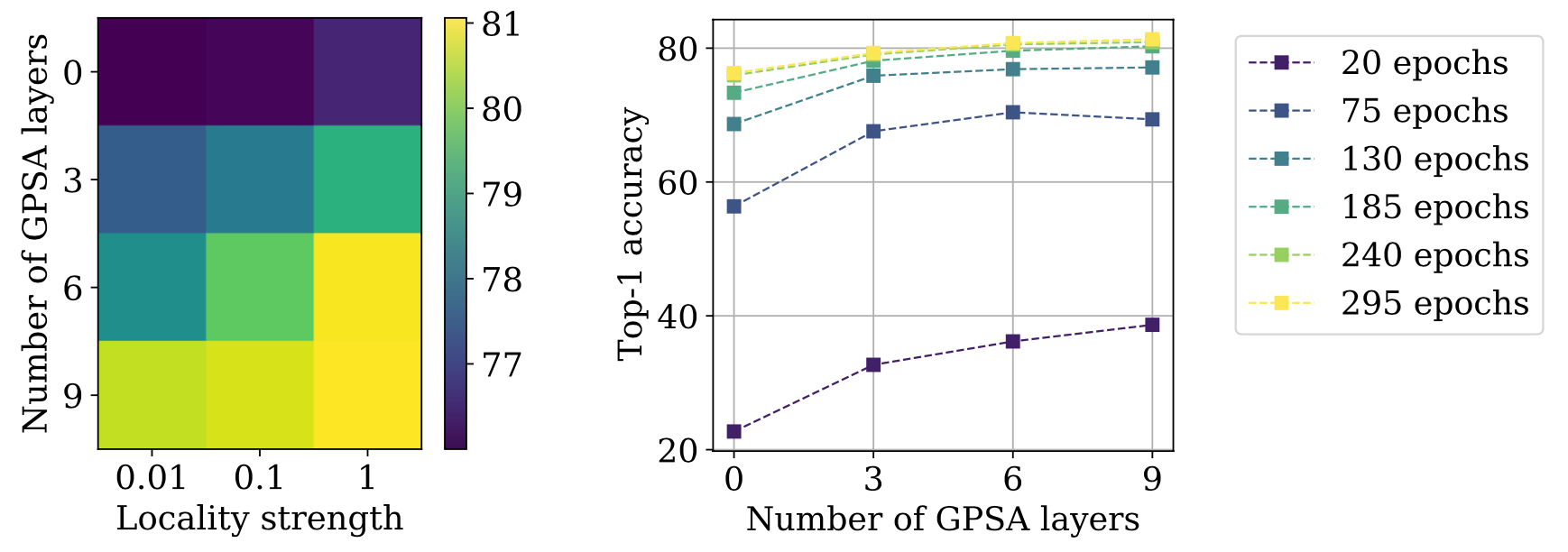 Relationship between locality and performance
Relationship between locality and performance