Significance
Keypoints
- Propose a self-supervised method for enhancing pre-trained video super-resolution algorithms
- Extensive experiments confirm the performance of the proposed method
Review
Background
Self-supervised learning has a powerful advantage in that it does not require ground truth data during training. Furthermore, accumulating evidences suggest its potential practical powers. This work is in line with this trend, applying self-supervised learning to the video super-resolution problem.
Keypoints
Propose a self-supervised method for enhancing pre-trained video super-resolution algorithms
An important point to be considered when applying self-supervised learning is how to define the training target from the dataset without ground-truth.
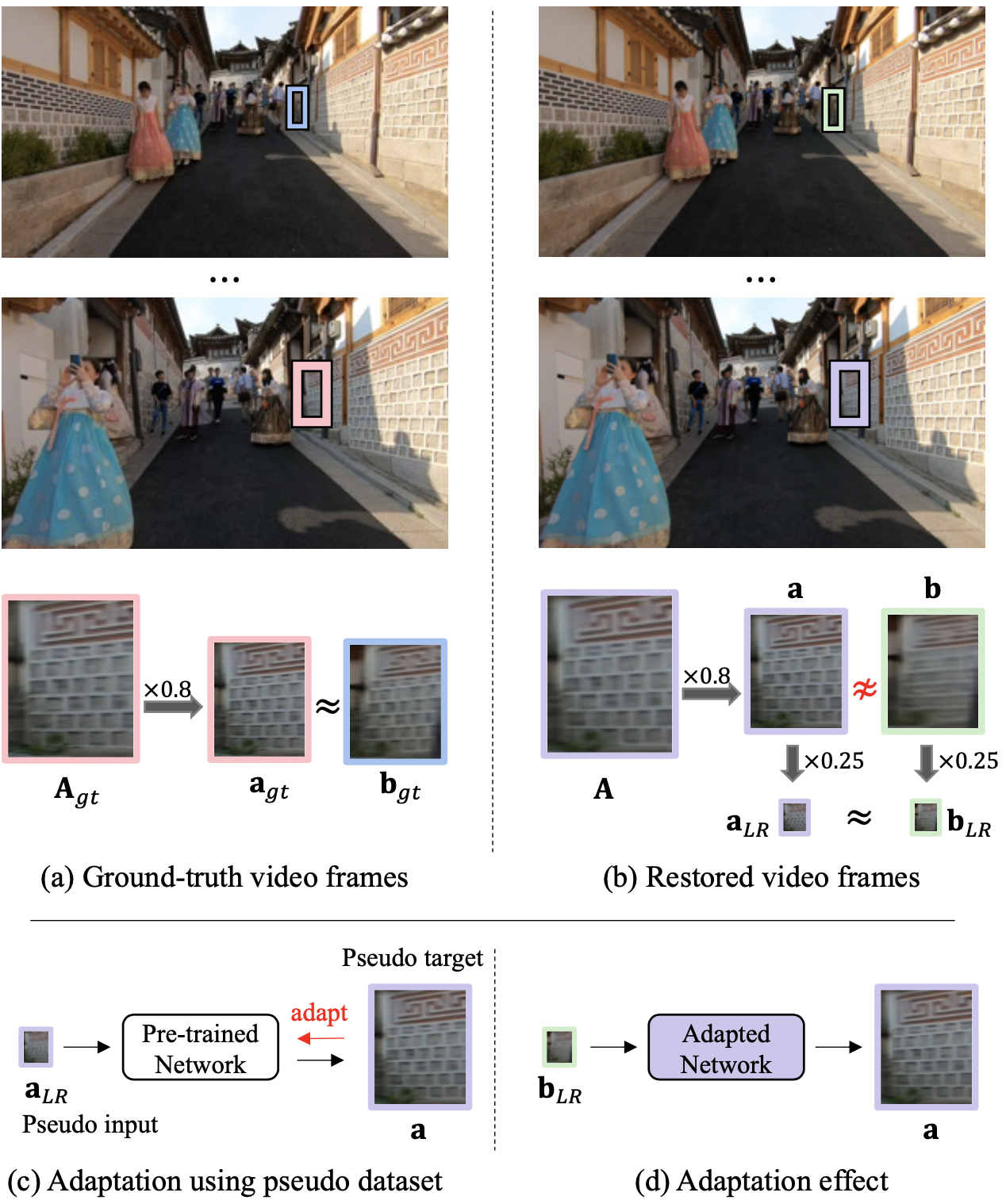 Key observation
The key observation of this work is that there usually exists similar patches within the full video between the downscaled version of a large patch $\mathbf{a}_{gt}$ and a patch from its nearby frame $\mathbf{b}_{gt}$.
However, this property does not hold for the frames resolved with the conventional neural networks, where quality of the downscaled version of a large patch $\mathbf{a}$ is much better than that of its corresponding small patch $\mathbf{b}$.
The authors mention that these two patches $\mathbf{a}$ and $\mathbf{b}$ become similar when downscaled to $\mathbf{a}_{LR}$ and $\mathbf{b}_{LR}$.
Based on the observation, $\mathbf{a}_{LR}$ and $\mathbf{a}$ serve as the input and target of the self-supervised training.
Key observation
The key observation of this work is that there usually exists similar patches within the full video between the downscaled version of a large patch $\mathbf{a}_{gt}$ and a patch from its nearby frame $\mathbf{b}_{gt}$.
However, this property does not hold for the frames resolved with the conventional neural networks, where quality of the downscaled version of a large patch $\mathbf{a}$ is much better than that of its corresponding small patch $\mathbf{b}$.
The authors mention that these two patches $\mathbf{a}$ and $\mathbf{b}$ become similar when downscaled to $\mathbf{a}_{LR}$ and $\mathbf{b}_{LR}$.
Based on the observation, $\mathbf{a}_{LR}$ and $\mathbf{a}$ serve as the input and target of the self-supervised training.
 Pseudocode of proposed self-supervised training
Knowledge-distillation can also be applied to this self-supervised method to reduce training time.
Pseudocode of proposed self-supervised training
Knowledge-distillation can also be applied to this self-supervised method to reduce training time.
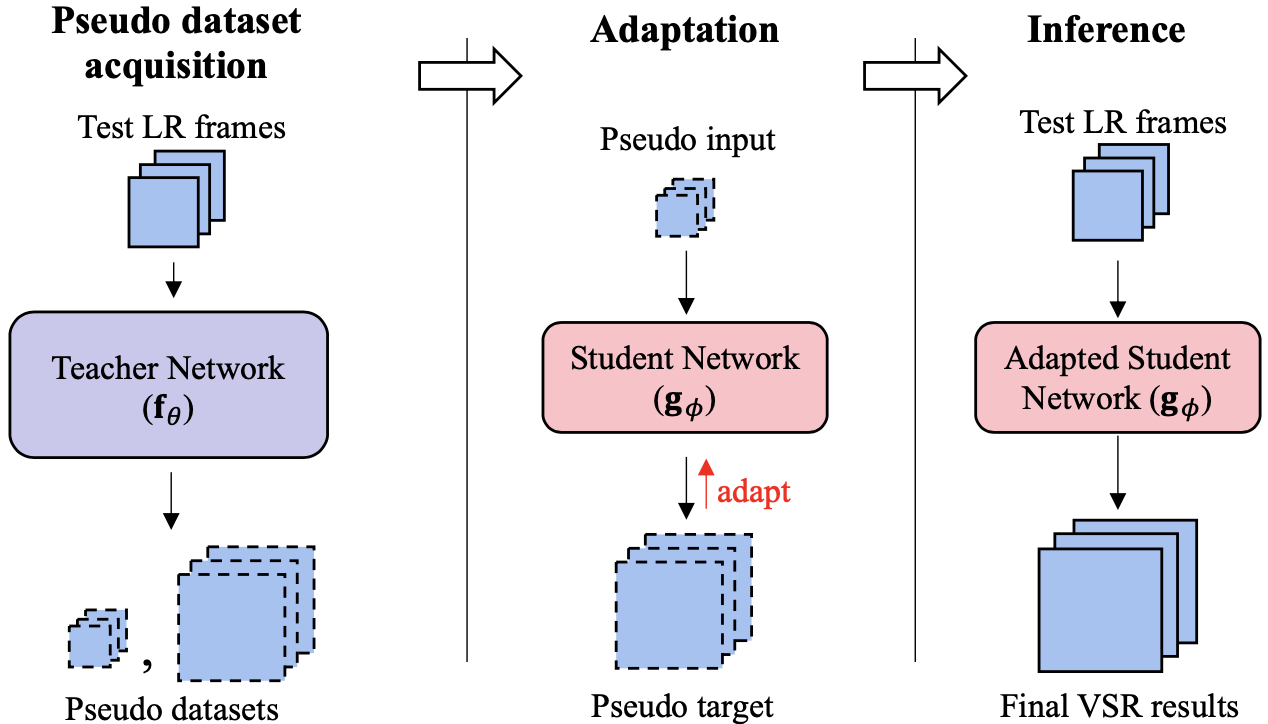 Knowledge distillation from large (teacher) network to small (student) network
Knowledge distillation from large (teacher) network to small (student) network
Extensive experiments confirm the performance of the proposed method
Experiments include quantitative and qualitative improvement of spatial resolution (PSNR/SSIM) and temporal consistency (tOF), using models TOFlow, RBPN, EDVR.
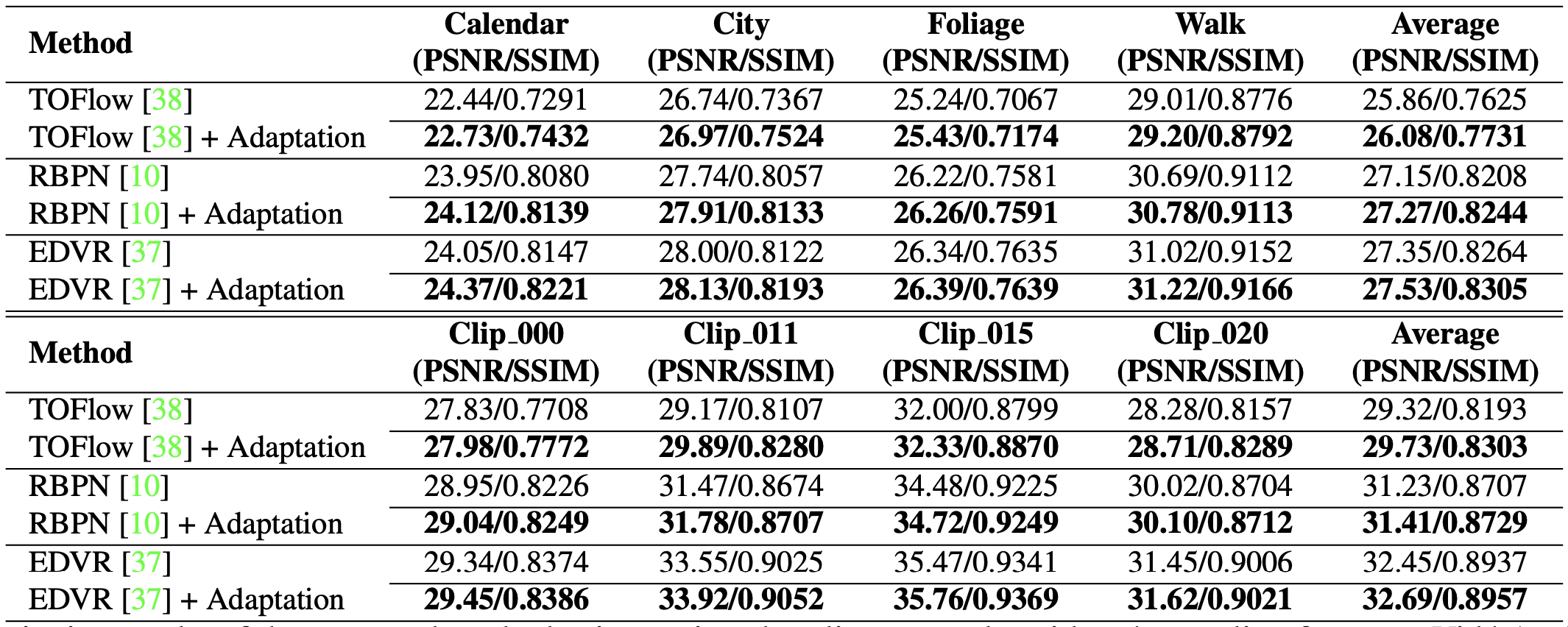 Spatial resolution of models with and without proposed method (quantitative)
Spatial resolution of models with and without proposed method (quantitative)
 Spatial resolution of models with and without proposed method (qualitative)
Spatial resolution of models with and without proposed method (qualitative)
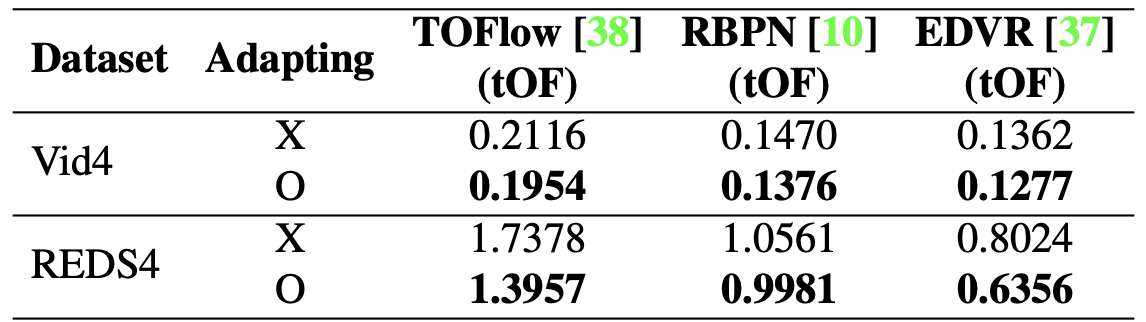 Temporal consistency of models with and without proposed method (quantitative)
Temporal consistency of models with and without proposed method (quantitative)
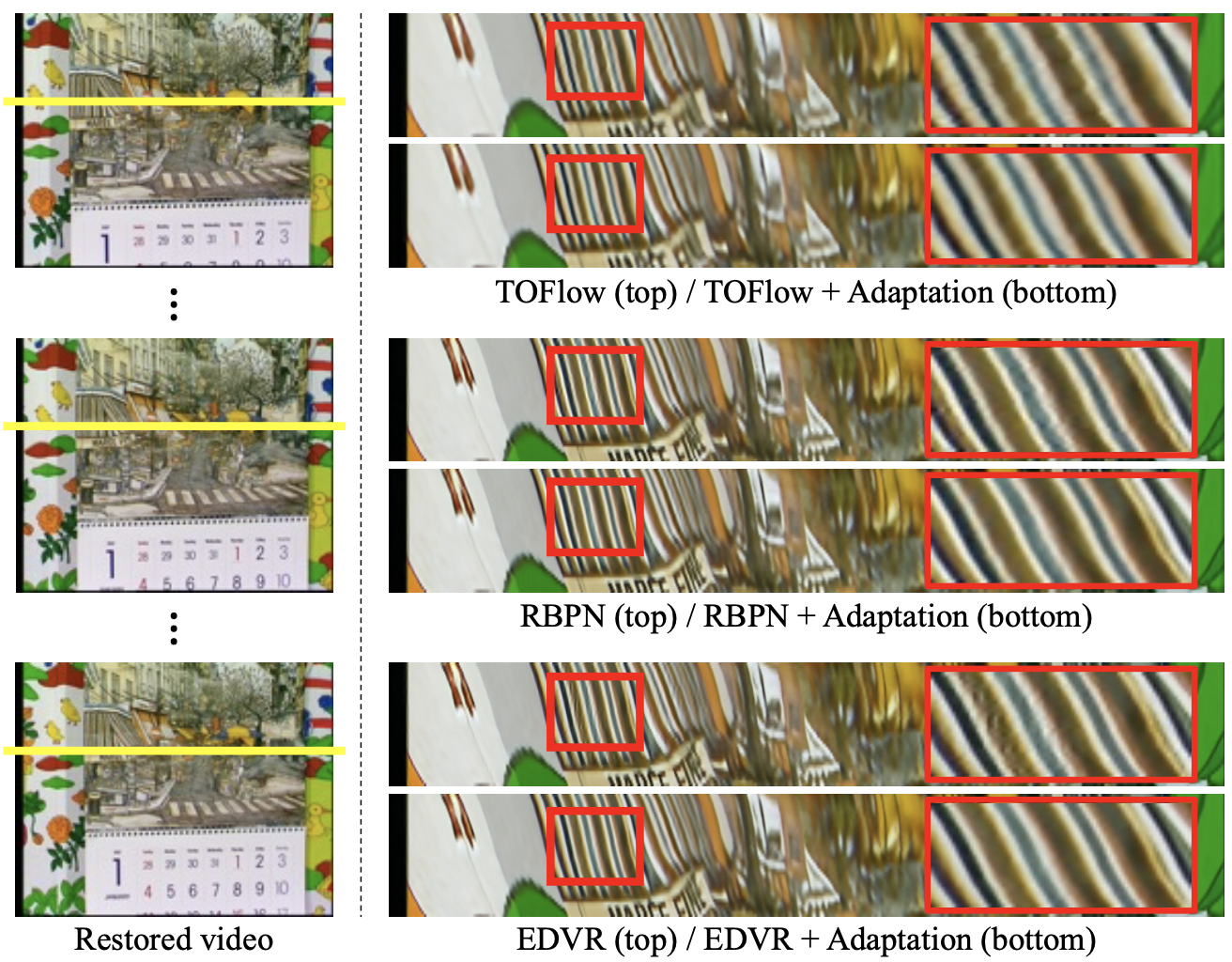 Temporal consistency of models with and without proposed method (qualitative)
Further experiments on single-image super-resolution also show improved performance when applied to RCAN.
Temporal consistency of models with and without proposed method (qualitative)
Further experiments on single-image super-resolution also show improved performance when applied to RCAN.
Related
- Masked Autoencoders Are Scalable Vision Learners
- InfoGCL: Information-Aware Graph Contrastive Learning
- Hierarchical Conditional Flow: A Unified Framework for Image Super-Resolution and Image Rescaling
- Hybrid Generative-Contrastive Representation Learning
- MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training