Significance
Keypoints
- Propose a framework for comparing various types of graph contrastive learning methods
- Provide graph contrastive learning principle based on experiments using the proposed framework
Review
Background
Self-supervised learning of graph neural networks (GNNs) to learn the representation of graph structured data has gathered large interest following the success of self-supervised learning in computer vision and natural language processing tasks. Among the self-supervised methods, contrastive learning refers to the method that creates two augmented views of the input and maximizing the consistency between the two views. For graph contrastive learning, there are various works that propose methods to augment graph views, encode the augmented views, and compute the consistency between the views. This work notes that any graph contrastive learning framework can be decoupled into these three steps (i) view augmentation, (ii) view encoding, and (iii) representation contrasting, and suggest optimal condition of each steps based on information theory.
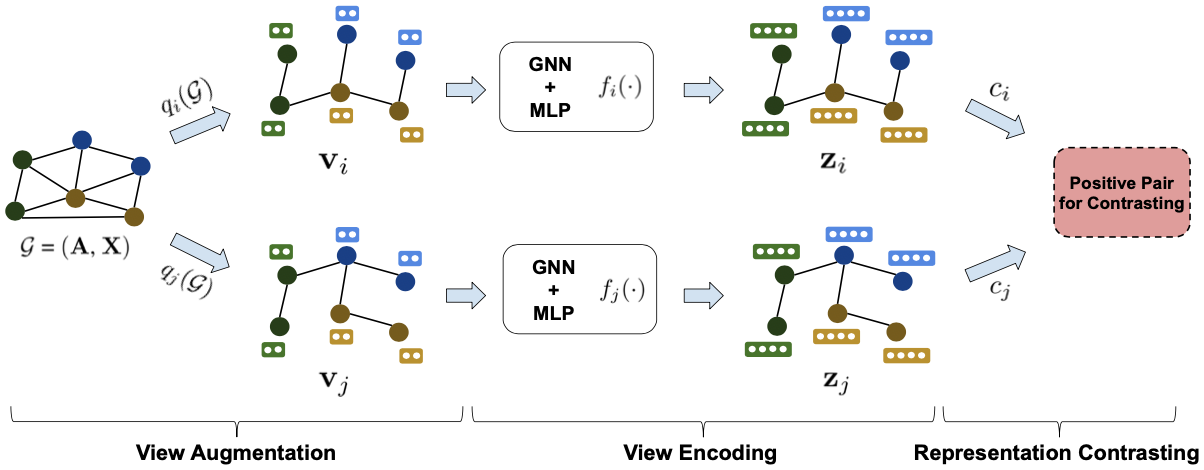 Three steps of graph contrastive learning
Three steps of graph contrastive learning
Keypoints
Propose a framework for comparing various types of graph contrastive learning methods
The authors try to theoretically derive an optimal condition of each steps in graph contrastive learning by information theory, or more specifically, mutual information between features.
Optimality of view augmentation
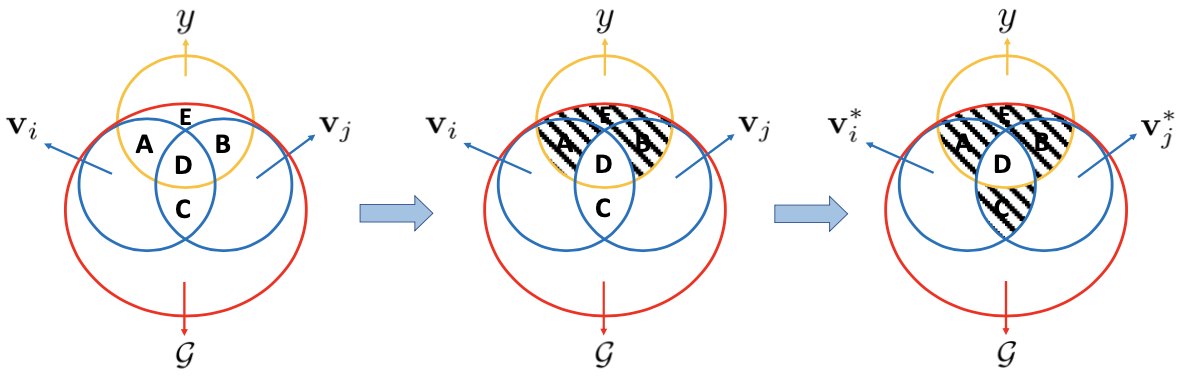 Venn diagram of optimal view augmentation. Stripes indicates null (empty) area
Venn diagram of optimal view augmentation. Stripes indicates null (empty) area
For view augmentation, the authors claim that the information contained in the two views $\mathbf{v}_{i}$, $\mathbf{v}_{j}$ should maximally be relevant to the target task $y$ (middle of the above figure). Furthermore, the information shared between the views should only be task-relevant (right of the above figure).
Optimality of view encoding
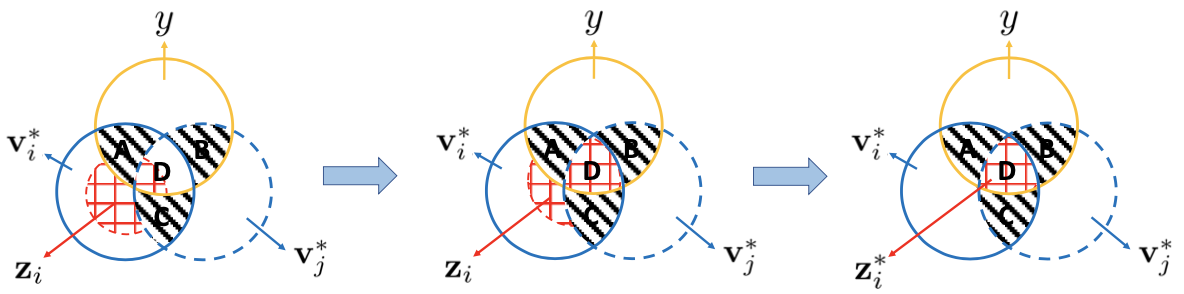
For view encoding, optimality can be achieved by an encoder that keeps all the shared information by the two views (middle of the above figure) and the kept information being solely task-relevant (right of the above figure).
Optimality of representation contrasting
For representation contrasting, the method that keeps maximal task-relevant information after representation aggregation can achieve optimality.
It is not easy to find a practical method that sticks to the optimal condition of each steps. However, comparing each graph contrastive learning method with the proposed principle can provide better understanding.
Provide graph contrastive learning principle based on experiments using the proposed framework
The proposed three principles are referred to the InfoGCL principle in the paper. Based on experiments (which is not described very much in detail), the authors provide a few benchmark results of graph contrastive learning methods.
- Composing a graph and its augmentation benefits downstream performance. Compared to composing a graph and the graph itself, augmentation leads to smaller mutual information between the two views.
- Composing different augmentations benefits more. Compared to composing a graph and its augmentations, two augmentations further decrease mutual information between the two views.
- Node dropping and subgraph sampling are generally beneficial across datasets. When compared to attribute masking and edge perturbation, they change the semantic meaning of the graph relatively slightly, which leads to higher mutual information between the two contrastive view and the target task.
- Edge perturbation benefits social networks but hurts some biochemical molecules. The semantic meaning of social networks are robust to edge perturbation. However, the semantic meaning of some biochemical molecules are determined by local connection pattern, where edge perturbation decreases mutual information between the contrastive view and the target task.
- Contrasting node and graph representations consistently performs better than other contrastive modes across benchmarks. Compared to other contrastive modes, node-graph (i.e., local-global) mode generally extracts more graph structure information, which benefits predicting task label $y$.
The quantitative analysis which derived the above result was referred to the appendix, which was not present in the preprint so confidence of the above statements could not be estimated. However, the proposed principle does provide some guideline to understanding and improving various graph contrastive learning methods which can help researchers interested in developing new related methods.
Related
- Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs
- Masked Autoencoders Are Scalable Vision Learners
- HDMapGen: A Hierarchical Graph Generative Model of High Definition Maps
- Hybrid Generative-Contrastive Representation Learning
- MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training