Significance
Keypoints
- Propose a instruction based finetuning method for improving zero-shot task performance
- Demonstrate zero-shot performance of the instruction tuned language model
Review
Background
Language models with large number of parameters, such as GPT-3, have been shown to perform well in few-shot learning.
These models are pre-trained on a large language corpus and finetuned on a specific task to improve its performance on the task.
The authors propose an intuitive finetuning method called instruction tuning by leveraging the fact that pre-trained language models are already capable of extracting the representation of the natural language.
Specifically, instruction tuning is to finetune a language model by describing the NLP tasks in natural language instructions.
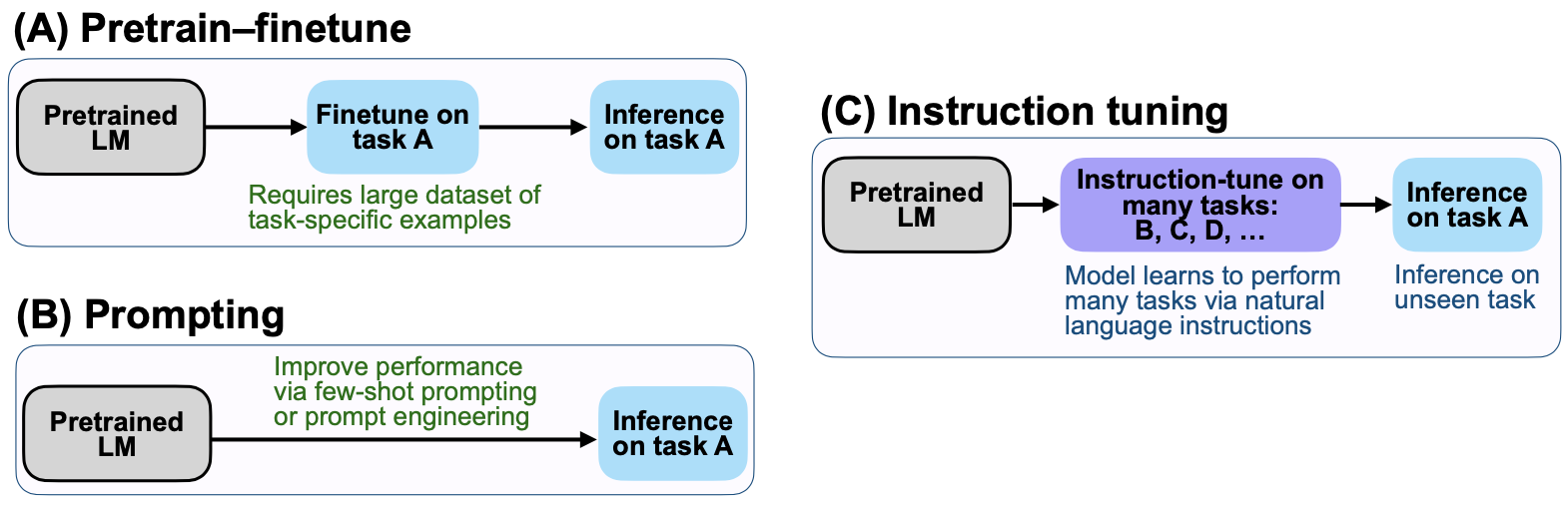 Finetuning, prompting, and proposed instruction tuning of the pre-trained language model
Finetuning, prompting, and proposed instruction tuning of the pre-trained language model
Teaching a language model in nautral language to do better in language tasks sounds strange, but interesting.
Keypoints
Propose a instruction based finetuning method for improving zero-shot task performance
To instruct the language model in natural language, the authors reformulated available natural language datasets into twelve clusters.
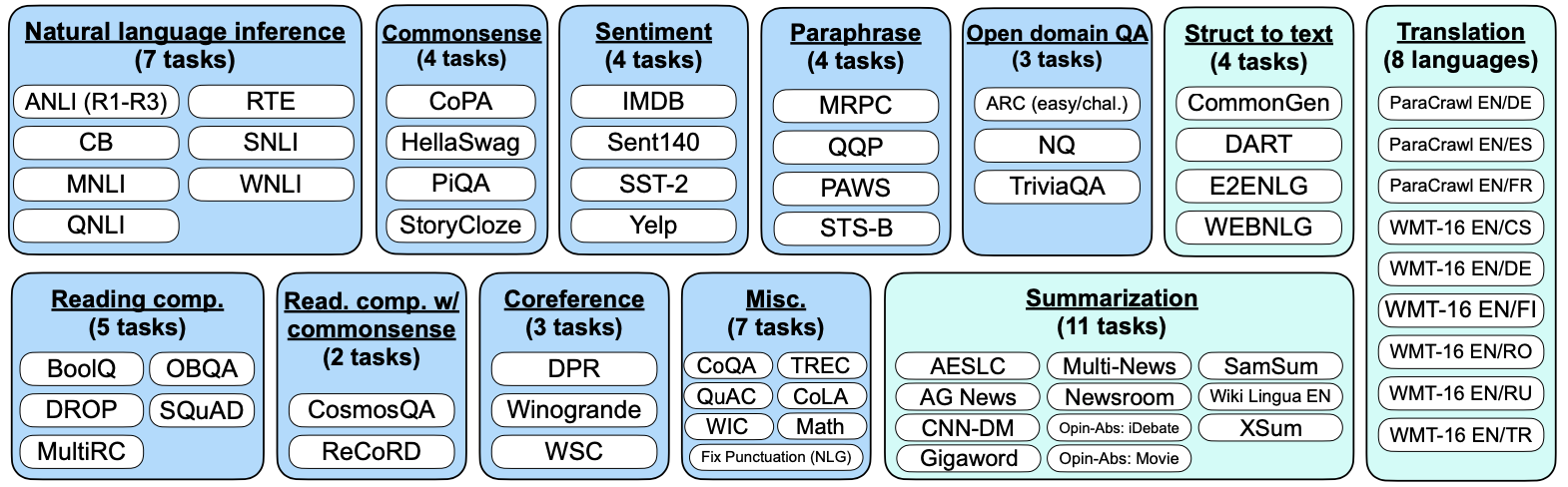 Sixty tasks in twelve clusters for instruction learning
Sixty tasks are included in the twelve clusters, where a task is defined as a particular set of input-output pair given by a dataset.
Tasks from the same clusters are not used during training as the inference task are left out during training.
To describe the original tasks with more diversity, each tasks are further composed to ten templates
Sixty tasks in twelve clusters for instruction learning
Sixty tasks are included in the twelve clusters, where a task is defined as a particular set of input-output pair given by a dataset.
Tasks from the same clusters are not used during training as the inference task are left out during training.
To describe the original tasks with more diversity, each tasks are further composed to ten templates
 Example of template composition from a natural language inference task
Each templates are designed to fit the objectives of the corresponding task by the authors.
Example of template composition from a natural language inference task
Each templates are designed to fit the objectives of the corresponding task by the authors.
The model used for the instruction tuning experiment is named Base LM, which is a dense left-to-right decoder-only transformer with 137B parameters. The model is pre-trained with a collection of web documents similar to GPT-3, but the training data is not as clean as the training data of the GPT-3. The pre-trained Base LM is then instruction tuned to derive FLAN (Finetuned LAnguage Net).
Demonstrate zero-shot performance of the instruction tuned language model
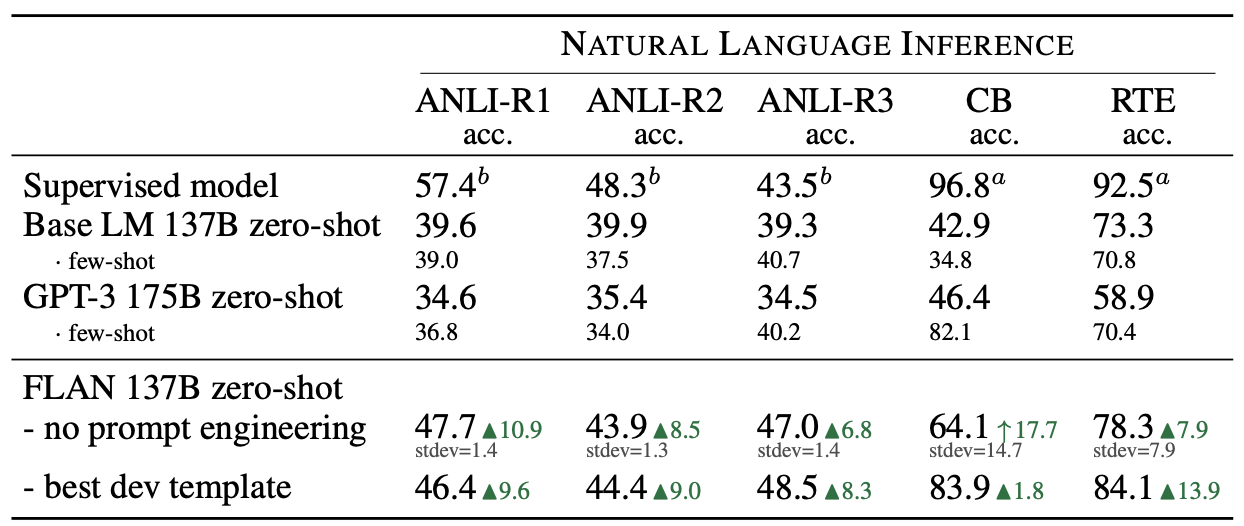
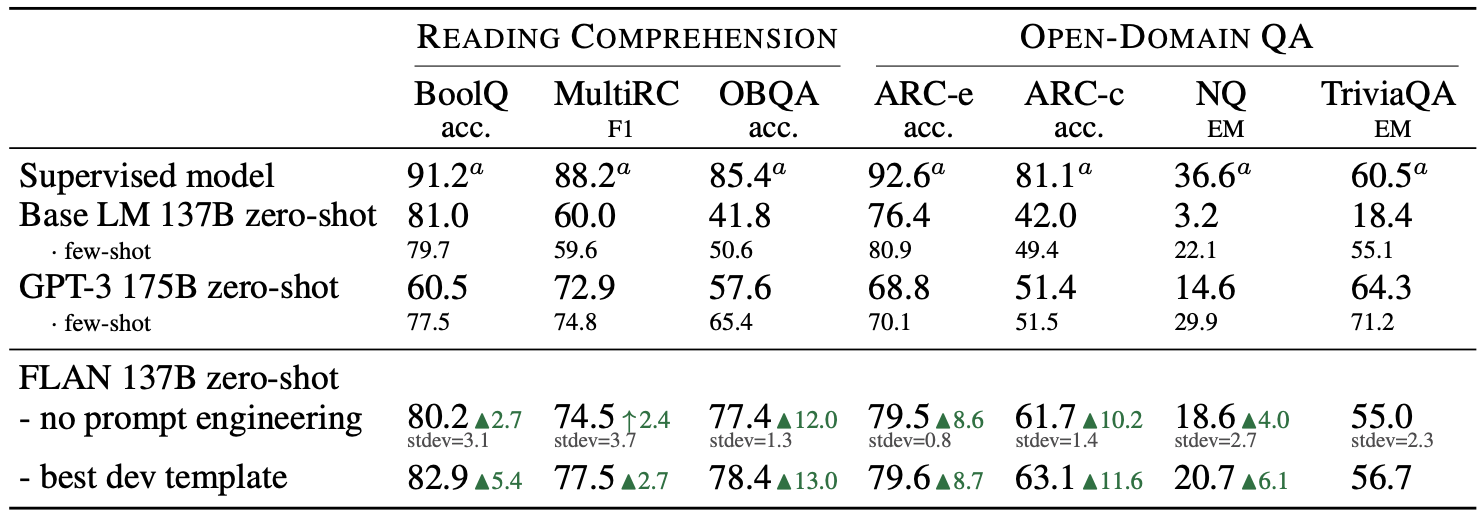
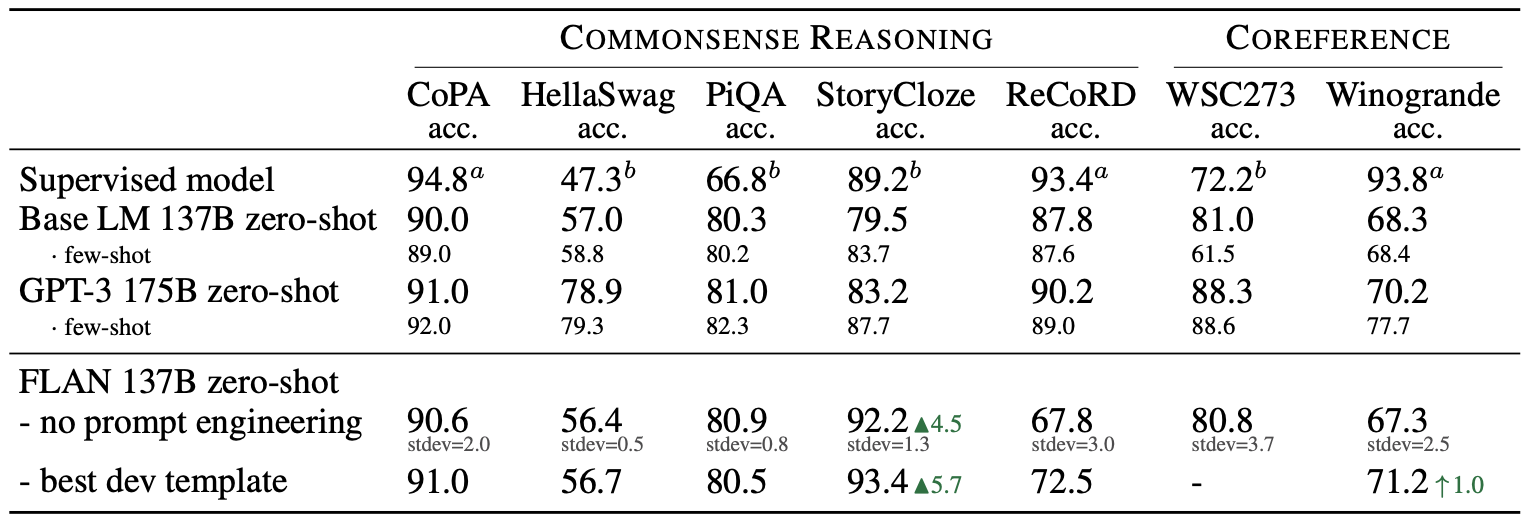
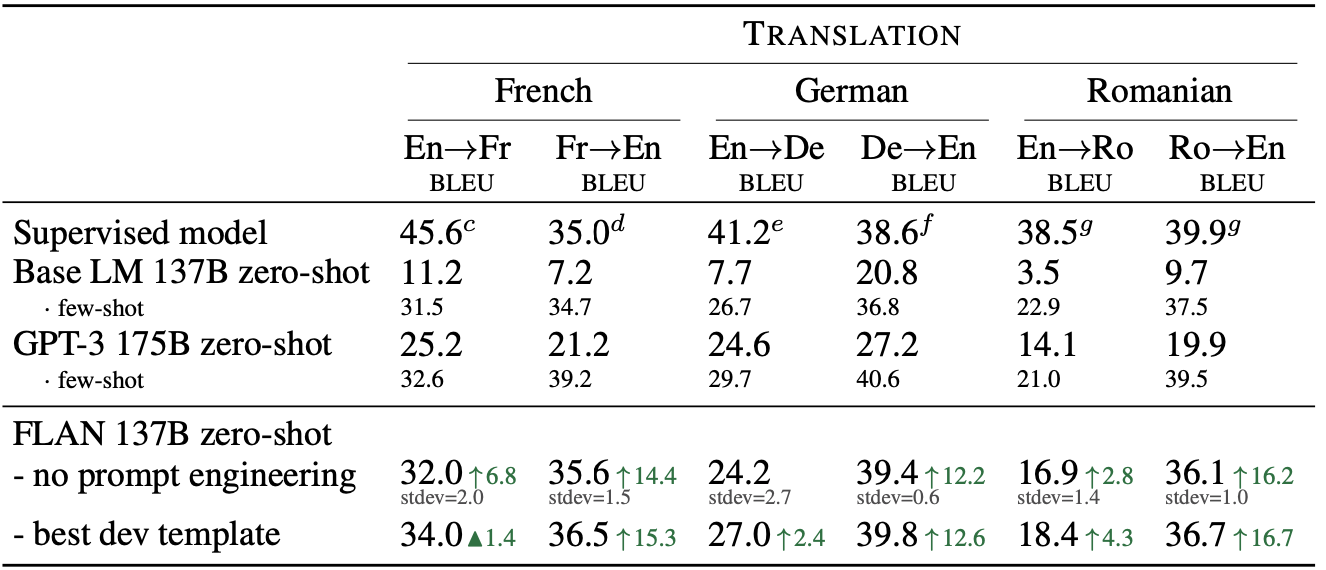
FLAN (137B) is compared mostly with the GPT-3 (175B) in zero-shot performance of various tasks. Following tables demonstrate that instruction tuned FLAN significantly outperforms GPT-3 in zero-shot performance of NLI, QA, reasoning, and translation.
Natural language inference
Question-answering
Reasoning
Translation
Further ablation studies and training details are referred to the original paper.