Significance
Keypoints
- Propose use of LLMs for interpreting text-attributed graphs (TAGs) as enhancers and predictors
- Derive observational findings of LLMs for node classification on TAGs
Review
Background
Large language models (LLMs) refer to a collection of neural network models (usually Transformers) that have large number of parameters, and are pre-trained on a large text corpus. There are evidences that LLMs are not only capable of handling tasks that are related to natural language, but also of performing well on tasks not directly related to natural language or texts. Based on these recent evidences, this study tries to explore the potential usage of LLMs in graph-domain tasks, specifically with node classification on text-attributed graphs (TAGs).
Keypoints
Propose use of LLMs for interpreting text-attributed graphs (TAGs) as enhancers and predictors
The authors propose two ways of utilizing LLMs to perform node classification on TAGs.
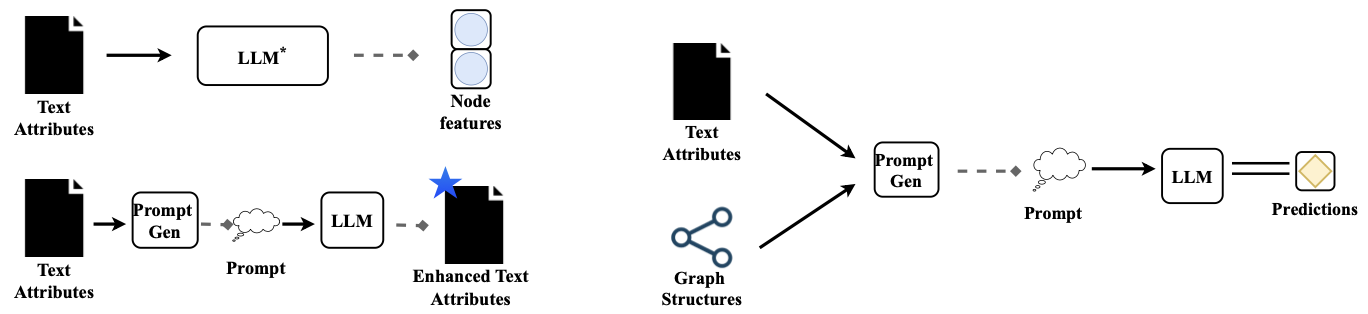 Incorporating LLM to graph related tasks as an enhancer (left) or a predictor (right)
Incorporating LLM to graph related tasks as an enhancer (left) or a predictor (right)
One is LLMs-as-Enhancers, and the other is LLMs-as-Predictors.
LLMs-as-Enhancers
The first approach is to utilize the LLMs as feature extractors of each nodes within the graph, which are text-attributes, and feed them into the a graph neural network (GNN), which is the de facto choice for learning on graphs. The authors propose three different strategies for this LLMs-as-Enhancers approach.
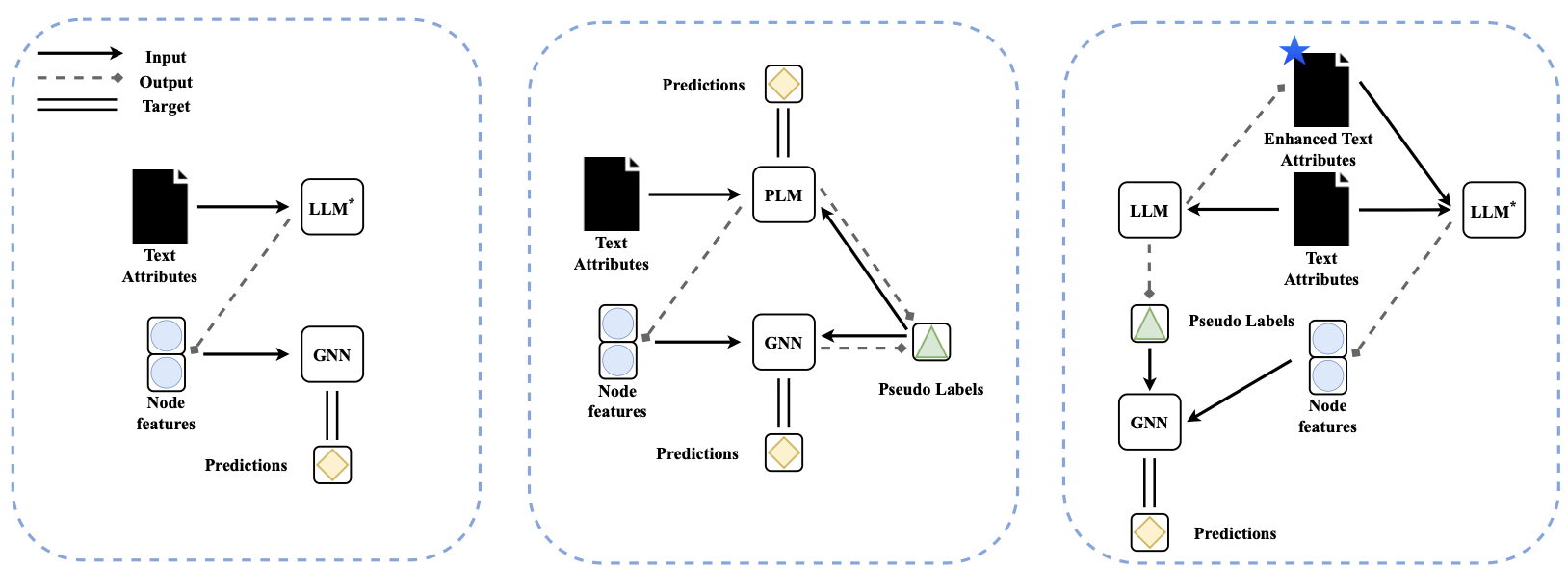 Three strategies for LLMs-as-Enhancers. Cascading (left), Iterative (middle), and Text-level enhancement (right).
Three strategies for LLMs-as-Enhancers. Cascading (left), Iterative (middle), and Text-level enhancement (right).
Additionally, two different augmentation strategies are used for leveraging the pre-trained knowledge of the LLMs, the TAPE and Knowledge Enhanced Augmentation (KEA).
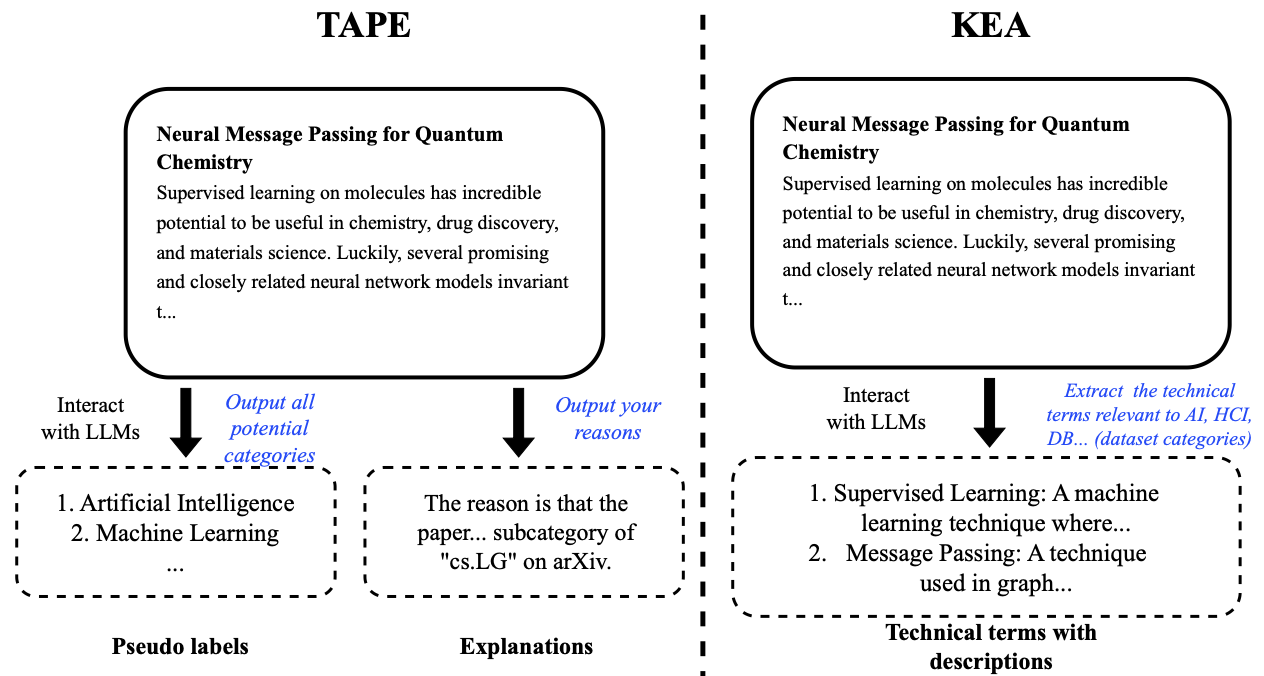 Two strategies for augmentation. TAPE (left), and KEA (right).
Two strategies for augmentation. TAPE (left), and KEA (right).
LLMs-as-Predictors
The second approach is to utilize only the LLM for the classification of each node. A prompt corresponding to the target TAG is generated both with and without structure (edge) information.
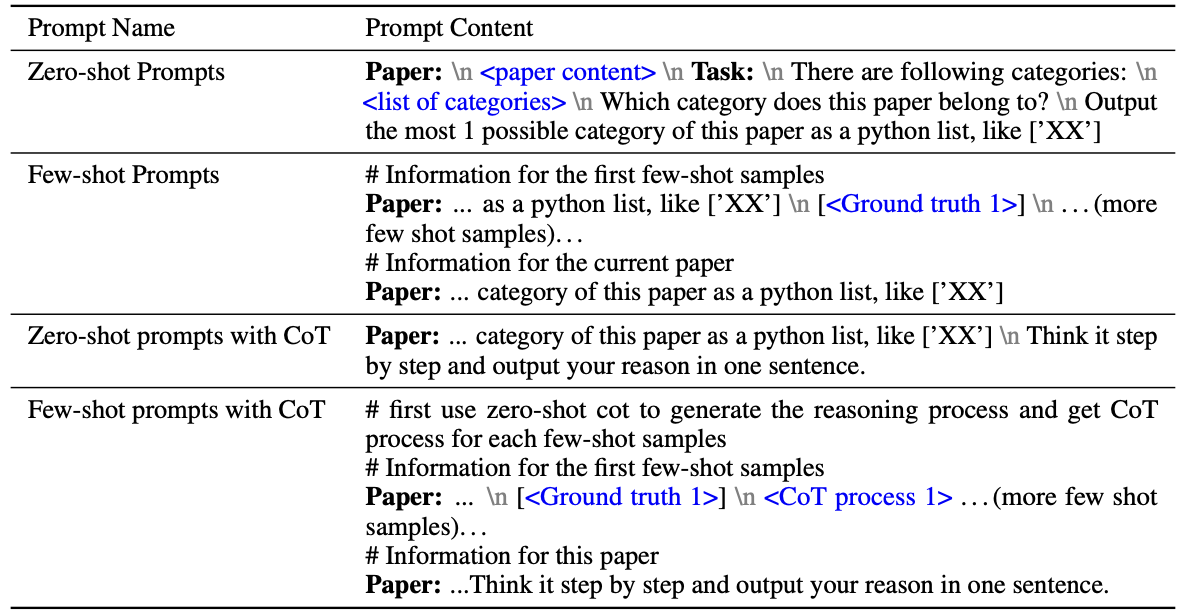 Example of prompt generation without structure information
Example of prompt generation without structure information
 Example of prompt generation with additional structure information
Example of prompt generation with additional structure information
The generated prompt is input to the LLM and classification of each node is performed.
Derive observational findings of LLMs for node classification on TAGs
The authors derive 10 main findings from their experiments. Experiments are performed on
- Datasets: CORA, Pubmed, OGBN-Arxiv, OGBN-Products
- GNNs: GCN, GAT, RevGAT, GraphSAGE, SAGN, (and MLP)
- LLMs: Deberta, LLaMA, Sentence-BERT, e5-large, text-ada-embedding-002 (OpenAI), and Palm-Cortex-001 (Google),
and following observations are obtained.
LLMs-as-Enhancers
- Observation 1. Combined with different types of text embeddings, GNNs demonstrate distinct effectiveness.
- Observation 2. Fine-tune-based LLMs may fail at low labeling rate settings.
- Observation 3. With a simple cascading structure, the combination of deep sentence embedding with GNNs makes a strong baseline.
- Observation 4. Simply enlarging the model size of LLMs may not help with the node classification performance.
- Observation 5. For integrating structures, iterative structure introduces massive computation overhead in the training stage.
- Observation 6. In terms of different LLM types, deep sentence embedding models present better efficiency in the training stage.
- Observation 7. The effectiveness of TAPE is mainly from the explanations E generated by LLMs.
- Observation 8. Replacing fine-tuned Pre-trained Language Models (PLMs) with deep sentence embedding models can further improve the overall performance of TAPE.
- Observation 9. The proposed knowledge enhancement attributes KEA can enhance the performance of the original attribute TA.
- Observation 10. For different datasets, the most effective enhancement methods may vary.
Here, the ‘low/high labeling rate setting’ refers to the way of splitting the dataset, representing the rate of labeled training data within the whole dataset.
LLMs-as-Predictors
- Observation 11. LLMs present preliminary effectiveness on some datasets.
- Observation 12. Wrong predictions made by LLMs are sometimes also reasonable.
- Observation 13. Chain-of-thoughts do not bring in performance gain.
- Observation 14. There is potential test data leakage in evaluation.
- Observation 15. Neighborhood summarization is likely to achieve performance gain.
- Observation 16. LLMs with a structure-aware prompt may also suffer from heterophilous neighboring nodes.
- Observation 17. The quality of pseudo labels is key to downstream performance.
- Observation 18. Getting the confidence by simply prompting the LLMs may not work since they are too “confident”.
Conclusion
Experimental results that support the observation can be found from the [original work]https://arxiv.org/abs/2307.03393. It should be mentioned that the findings are observational, not definite, so there is a possibility that it may not be a general fact in other experimental conditions. At the end, the authors summarize the three key findings as follows:
- Finding 1. For LLMs-as-Enhancers, deep sentence embedding models present effectiveness in terms of performance and efficiency.
- Finding 2. For LLMs-as-Enhancers, the combination of LLMs’ augmentations and ensembling demonstrates its effectiveness.
- Finding 3. For LLMs-as-Predictors, LLMs present preliminary effectiveness but also indicate potential evaluation problem.