Significance
Keypoints
- Report technical details for implementing, training, evaluating, and sharing pre-trained language models
Review
Background
The dark side of the large scale language models is that they are pre-trained with a large corpus of text datasets which are prone to biased toxic language contents. Furthermore, the pre-trained models consists of over hundreds of billions of parameters, which cannot easily be shared with public in its full form. The authors raise the issue that this can be ethically harmful, and pre-train 8 Transformer based language models for opening them to public. This paper includes technical details for
Keypoints
Report technical details for implementing, training, evaluating, and sharing pre-trained language models
Models
The authors train 8 Transformer based models, named open pre-trained transformers (OPT), ranging from 125M to 175B parameters. The 175B parameter OPT model corresponds to the GPT-3 model.
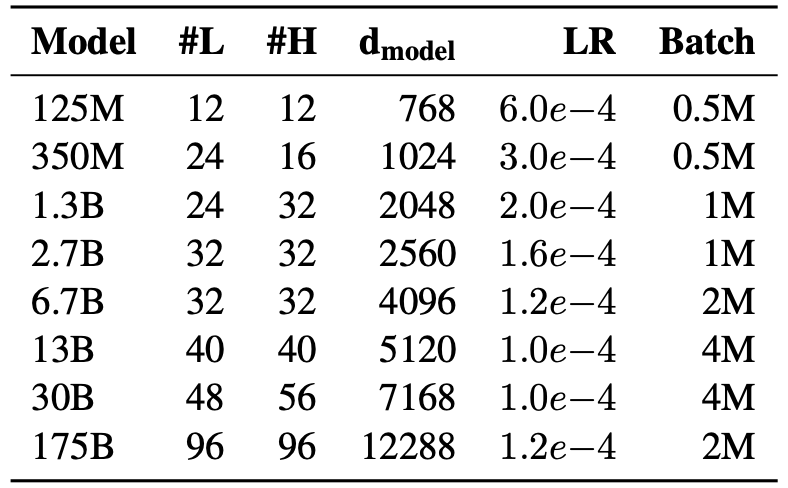 Specification of 8 Transformer models
Specification of 8 Transformer models
The number of layers (#L), heads (#H), embdding size (d_model), and the peak learning rate (LR) are reported in the Table above.
Pre-training corpus
The pre-training corpus includes roughly 180B tokens, filtered after concatenating the datasets used in previous works (RoBERTa, the Pile, PushShift.io Reddit)
Training process
Training was performed on 992 80GB A100 GPUs for the OPT-175B model for two months. Training was restarted from checkpoints when the loss diverged or hardware failure was found.
Evaluation
Evaluating the pre-trained OPT models included performing 16 standardized NLP tasks for prompting and zero/few-shot: HellaSwag, StoryCloze, PIQA, ARC Easy and Challenge, OpenBookQA, WinoGrad, Wino- Grande, and SuperGLUE. Performance of OPT for zero/few-shot prompting showed comparable performance to the GPT-3 model.
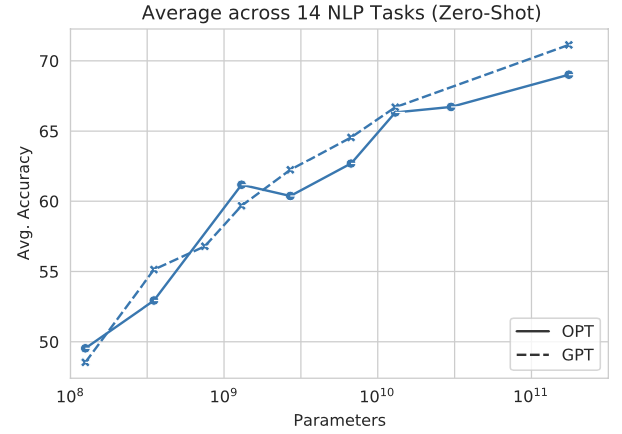 Zero-shot performance results
Zero-shot performance results
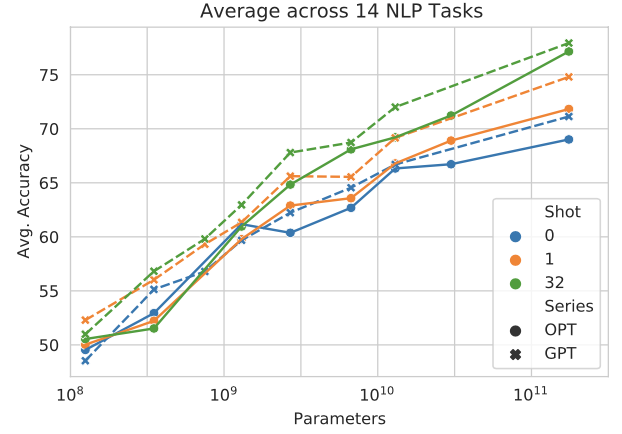 Few-shot performance results
Few-shot performance results
Perplexity and Unigram F1 are also evaluated on multiple open source dialogue datasets with other benchmark models and show competitive performance to supervised models.
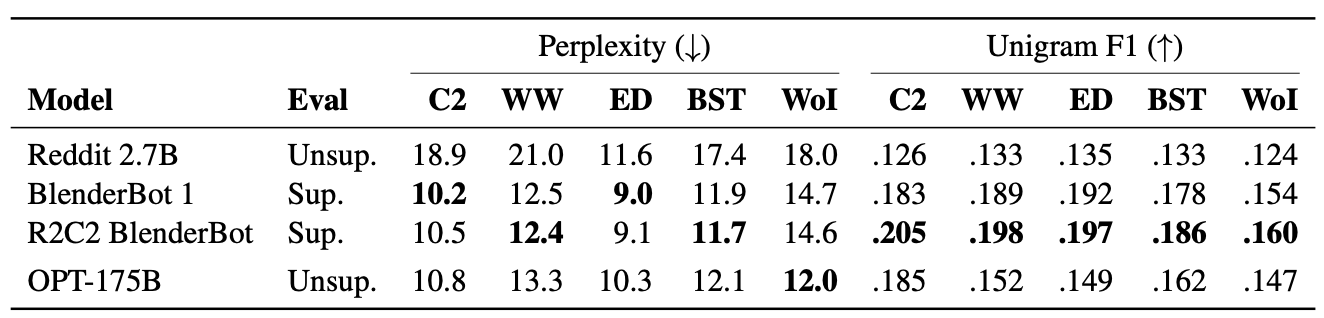 Dialogue evaluation results
Dialogue evaluation results
Bias & Toxicity
Potential harm of the OPT-175B was studied with benchmark datasets. Hate speech detection (ETHOS), bias measure (CrowS-Pairs, StereoSet), tendency to respond to toxic language (RealToxicityPrompts), and dialogue safety evaluations (SaferDialogues, Safety Bench Unit Tests) were performed.
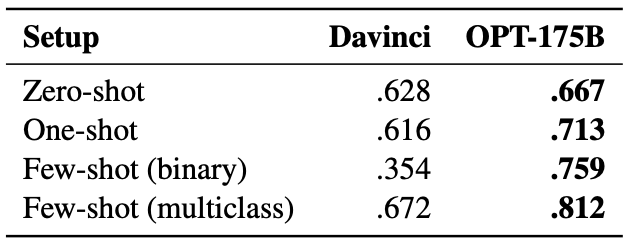 Hate speech detection results. F1 scores are reported.
Hate speech detection results. F1 scores are reported.
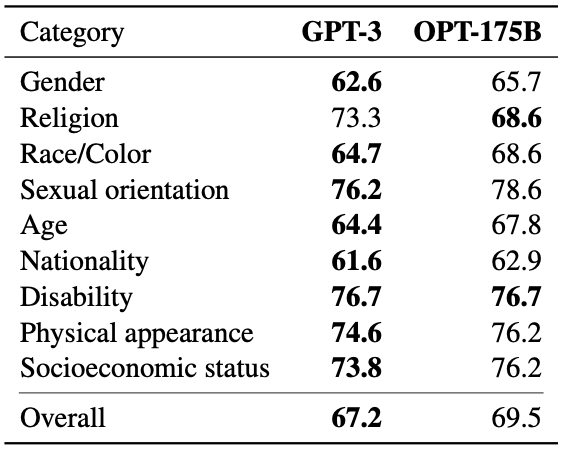 CrowS-Pairs bias measure results. Lower is better.
CrowS-Pairs bias measure results. Lower is better.
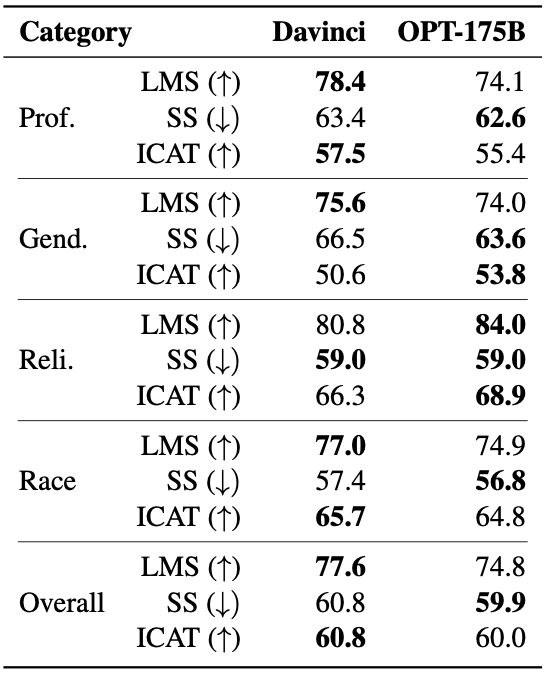 StereoSet bias measure results.
StereoSet bias measure results.
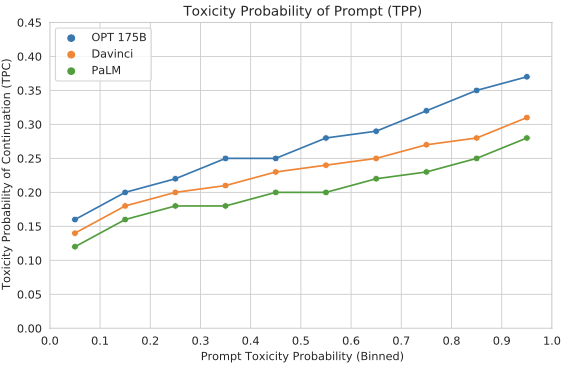 RealToxicityPrompts results. OPT-175B is more likely to generate toxic responses.
RealToxicityPrompts results. OPT-175B is more likely to generate toxic responses.
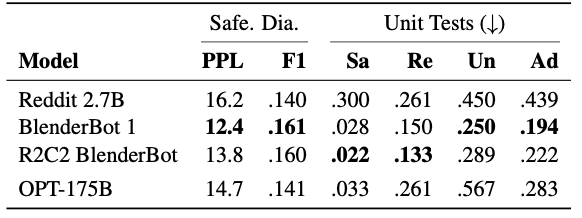 Dialogue safety evaluation results. OPT-175B performs worse in the ‘Unsafe’ setting
Dialogue safety evaluation results. OPT-175B performs worse in the ‘Unsafe’ setting
The authors conclude that the large language model is still premature for commercial deployment and comment that sharing the full pre-trained model parameters can promote people from various fields to improve this model for responsible application.