Significance
Keypoints
- Propose a private prediction protocol that preserves privacy for large-scale language models
- Demonstrate performance and privacy safety of the proposed method by experiments
Review
Background
Large scale language models are usually pretrained with a large corpus of public data, and then fine-tuned with smaller data for specific tasks. The fine-tuning data for real-world application often contains private information (addresses, personal ID numbers, etc), and recent language models with large number of parameters are easily tempted to memorize them during training.
Chatbot Luda controversy leave questions over AI ethics, data collection
While techniques such as DP-SGD have been applied during training for preserving privacy of language models, they often show unsatisfactory privacy-utility trade-off and requires modification of the training procedure which is not fully practical. The authors propose SubMix, a privacy-preserving technique for fine-tuning large-scale language models with private data which (i) does not require modification of the training algorithm, (ii) leverages the probabilistic nature of next-token sampling, and (iii) does not require noise addition for privatizing the model’s predictions.
Keypoints
Propose a private prediction protocol that preserves privacy for large-scale language models
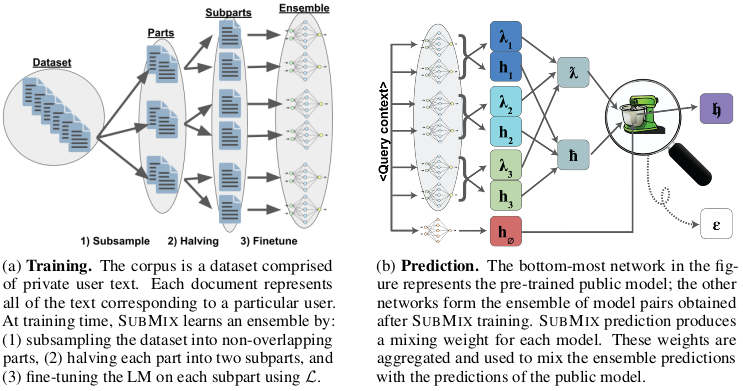 Schematic illustration of the proposed SubMix
Schematic illustration of the proposed SubMix
The proposed SubMix assumes the scenario of fine-tuning a pretrained language model with private dataset $\mathcal{D}_{p}$. Here, $\mathcal{D}_{p}$ may contain private data that should not be directly revealed as the model output. SubMix follows the subsample-and-aggregate scheme, which is to form a random partition $\Pi$ of the private dataset $\mathcal{D}_{p}$. Each user’s data is assigned to a single $i$-th partition $\Pi_{i}$ of total $k$ partitions, so that the data from one user is only contained in one part. The partition $\Pi_{i}$ is further split into two subparts $\pi_{i}$ and $\pi_{i}^{\prime}$, and these subparts are used for fine-tuning the language model separately. This procedure ends-up in $k \times 2$ language models, fine-tuned with different subset of private data. For the next-token generation problem, It is assumed that if the predicted token contains private information that is memorized by one model, then the generated token cannot be replicated from other models (which was trained with different subset of private data). The probability mass function of next-token distribution predicted from $i$-th partition fine-tuned models given input context $\mathbf{x}$ is defined as an average of two subpart fine-tuned models, $\bar{h}_{i}(\mathbf{x}) = (h_{\pi_i} + h_{\pi_i^\prime}) / 2$. Final prediction of $i$-th model is based on a linear interpolation between the fine-tuned model output $\bar{h}_{i}(\mathbf{x})$ and the non fine-tuned model output $\bar{h}_{\phi}(\mathbf{x})$ with coefficient $\lambda^\ast$: \begin{equation} h_{i}(\mathbf{x}) = \lambda^\ast \bar{h}_{i}(\mathbf{x}) + (1 - \lambda^\ast) \bar{h}_{\phi}(\mathbf{x}). \end{equation} Here, the coefficient $\lambda^\ast$ is determined based on whether the fine-tuned output $\bar{h}_{i}(\mathbf{x})$ carries high probability of containing private information (if it has high probability, then the coefficient gets low value so that the prediction from the original model gets more importance.). As noted earlier, this probability of revealing (i.e. predicting) private information is defined by the divergence between the two subpart model outputs to confirm that the predictions share similar information that can be learned from non-private data. So, the SubMix combines partitioning private data into ‘Sub’sets for training, and ‘Mix’ them during inference to promote privacy preservation.
 Pseudocode for SubMix training
Pseudocode for SubMix training
 Pseudocode for SubMix inference
Pseudocode for SubMix inference
We refer to the original paper for the formal definition of $\kappa$-eidic memorization and Renyi operational privacy (ROP) for private prediction. The authors theoretically show that the SubMix procedure is an $(\alpha, \epsilon)$-ROP prediction mechanism.
Demonstrate performance and privacy safety of the proposed method by experiments
The SubMix procedure is experimented on a large-scale pretrained language model, GPT-2. Fine-tuning private datasets included the Wikitext-103 and the BigPatent-G. The privacy-utility trade-off is compared with baseline models DP-SGD, sub-sample and aggregate (S&A), and GNMax.
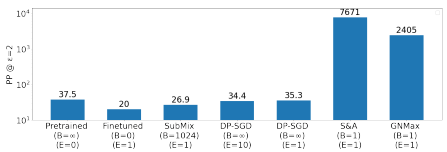 Privacy-utility trade-off of SubMix
Privacy-utility trade-off of SubMix
It can be seen that while other models (S&A, GNMax) sacrifice a large margin of performance when compared to pretrained and finetuned models even for single query ($B=0$) settings. The DP-SGD showed comparable performance to the pretrained model with ten epochs of training ($E=10$), while the proposed SubMix showed comparable performance to the finetuned model.
For privacy preservation against text extraction attacks, hit rate (number of generated codes that exactly match a secret code divided by number of generations) is evaluated with varying $\epsilon$ of SubMix.
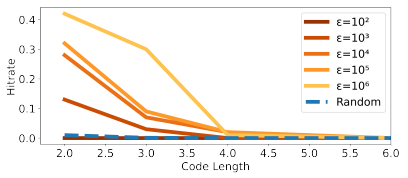 Hitrate with respect to code length for SubMix code generation
Hitrate with respect to code length for SubMix code generation
The results suggest that SubMix is capable of keeping secret data from being predicted at $\epsilon = 10^2$ for all code lengths.
Other results on varying hyperparameters of SubMix are referred to the original paper.