Significance
Keypoints
- Demonstrate performance of the large-scale language models with mixture-of-experiments by experiments
Review
Background
A week ago, I have reviewed a paper from Google which demonstrated compute efficient large scale language model by introducing Mixture-of-experts (MoE). This paper has a very similar motivation and idea, again introducing MoE to the language model for efficient computation while maintaining its performance. For a brief review on the importance of the efficiency in model scaling, please refer to my previous post.
Keypoints
Demonstrate performance of the large-scale language models with mixture-of-experiments by experiments
The dense model architecture is based on the GPT-3, with difference in (i) using only dense attention, and (ii) using sinusoidal positional embeddings. The sparse model counterpart is based on the GShard with 512 experts in each expert layer, and the top-2 expert selection was used.
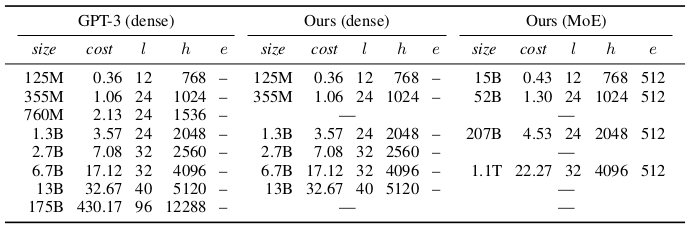 Specification of the experimented models
Specification of the experimented models
As the result can be expected, MoE models achieve comparable performance to its dense counterparts with around 4 times less compute.
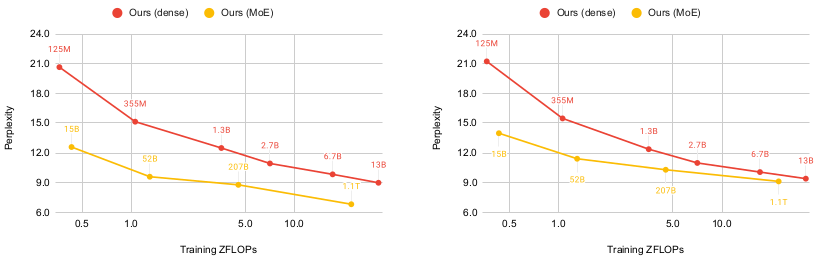 Perplexity as a function of ZFLOPs for in-domain (left) and out-of-domain (right) data.
Perplexity as a function of ZFLOPs for in-domain (left) and out-of-domain (right) data.
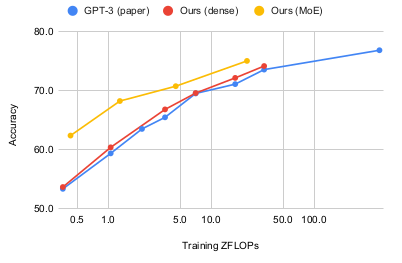 Average zero-shot priming accuracy as a function of ZFLOPs.
Average zero-shot priming accuracy as a function of ZFLOPs.
Other results are consistent with the GLaM results, suggesting the efficiency of MoE models.
Efficient language models are expected to reduce energy consumption and CO2 emission related to large-scale computing.
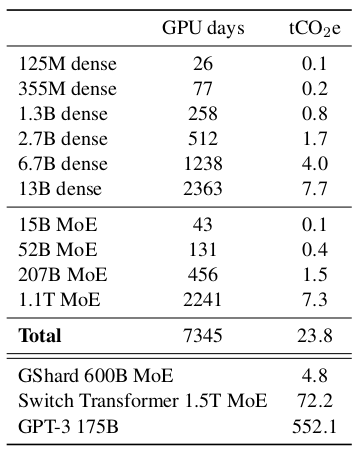 Estimated training time and CO2 emission of the experimented models
Estimated training time and CO2 emission of the experimented models
Can MoE become a standard option for further scaling of the language models?