Significance
Keypoints
- Build a large-scale symbolic music corpus
- Propose encoding and self-supervised pre-training practice for symbolic MIDI data
- Demonstrate performance on four downstream tasks for music understanding
Review
Background
Music shares certain similarity with natural language. While the pre-trained natural language models (e.g. BERT) have provided powerful representation learning from unlabelled text corpora, taking this idea directly to learning representation of music is a bit more complicated. For example, the music songs are more structural, requires pitch/instrument information, etc. Other practical difficulties include the lack of large-scale music corpora, and naively encoding the sequence of naive music notes too long to be processed at once. The authors address these issues and provide practical solutions by building a large-scale symbolic music corpus, proposing an efficient encoding of music notes, and pre-training the model with appropriate masking scheme that fits the musical structure.
Keypoints
Build a large-scale symbolic music corpus
The authors focus on symbolic music representation learning, which is musical songs written in a set of symbols that denote musical information such as pitch, velocity, duration of a note. Million-MIDI dataset (MMD) is a new large-scale symbolic MIDI dataset which contains over 1.5 million songs and 2 billion notes. The songs are deduplicated to make models possible to learn powerful representation from the dataset.
Propose encoding and self-supervised pre-training practice for symbolic MIDI data
OctupleMIDI encoding
To encode musical notes more efficiently, the authors propose OctupleMIDI encoding, which encodes 8 elements of a note including time signature, tempo, bar and position, instrument, pitch, duration, and velocity.
OctupleMIDI encoding significantly reduces number of tokens when compared to baseline encoding methods (CP, REMI).
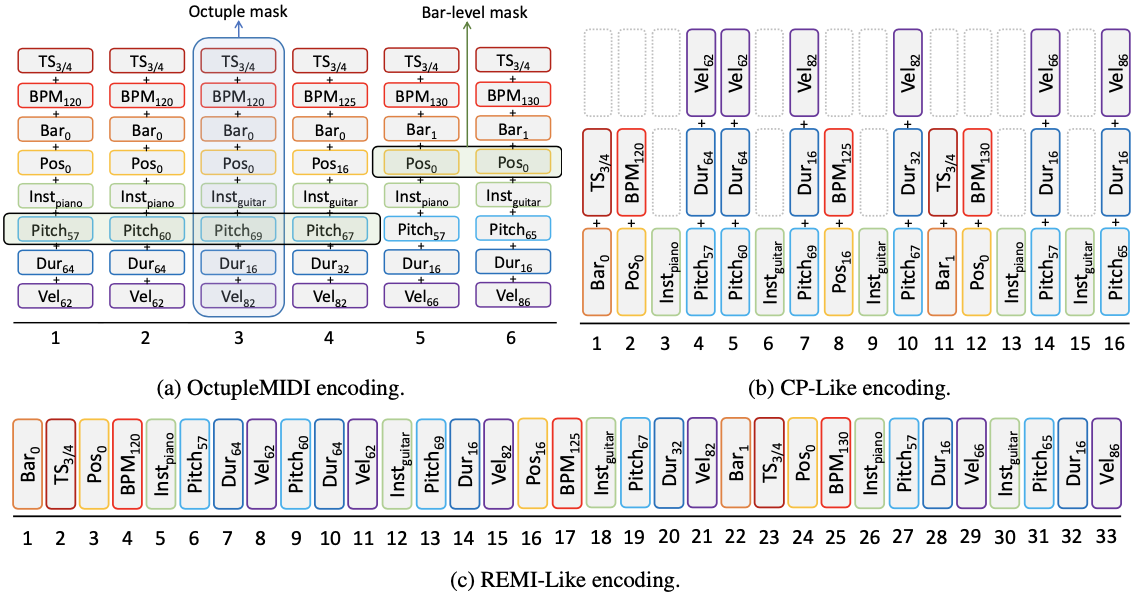 Scheme of OctupleMIDI and other baseline encodings
The OctupleMIDI encoding is concatenated and linearly mapped to output a single token per sequence before being input to the model.
Scheme of OctupleMIDI and other baseline encodings
The OctupleMIDI encoding is concatenated and linearly mapped to output a single token per sequence before being input to the model.
Bar-level masking strategy
To pre-train the Transformer encoder in a self-supervised way as in the case of BERT, the authors employ masking strategy.
However, randomly masking a sequence token is not as effective in the case of symbolic music data since adjacent notes within the same bar can carry too much information of the masked note.
The MusicBERT is the self-supervised pre-training of symbolic music data with OctupleMIDI encoding and bar-level masking scheme.
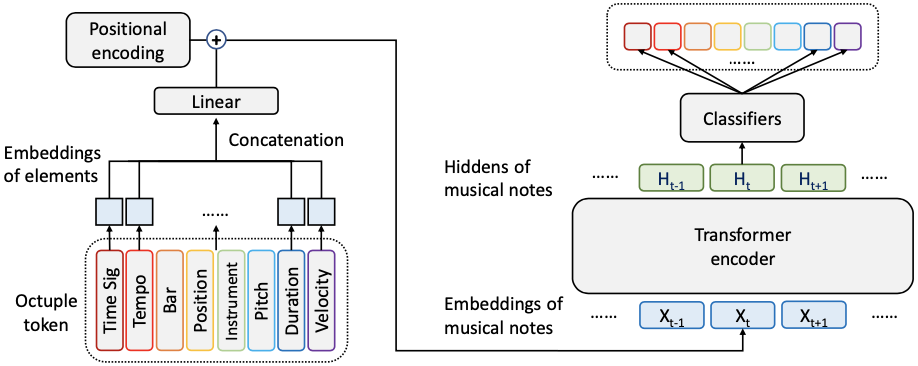 Scheme of the proposed MusicBERT
It is shown from experiments that the bar-level masking is essential for properly learning the symbolic music representation with the Transformer encoder.
Scheme of the proposed MusicBERT
It is shown from experiments that the bar-level masking is essential for properly learning the symbolic music representation with the Transformer encoder.
Demonstrate performance on four downstream tasks for music understanding
The performance of MusicBERT is evaluated on four downstream tasks including melody completion, accompaniment suggestion, genre classification and style classification.
It can be seen that the MusicBERT outperforms other baseline models in all four tasks
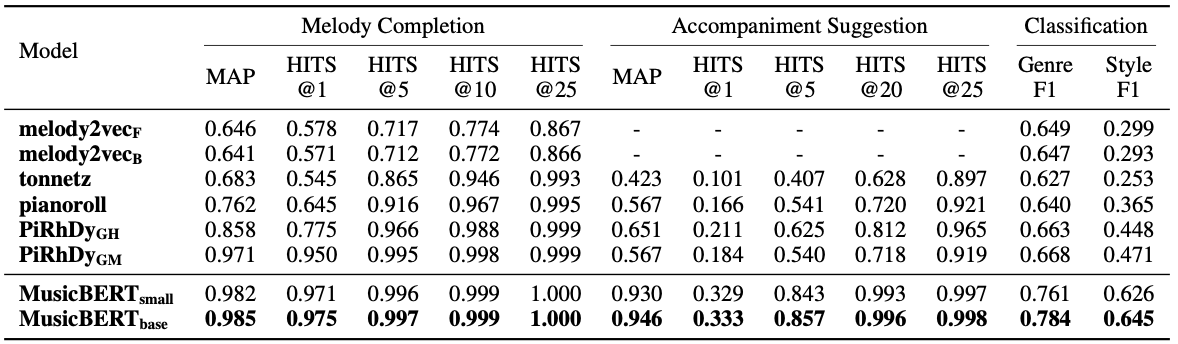 Performance of MusicBERT in four music understanding tasks
Performance of MusicBERT in four music understanding tasks
Ablation of encoding methods and bar-level masking result in significantly degraded performance.
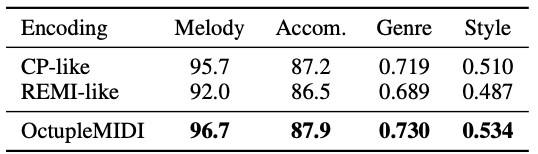 Ablation of OctupleMIDI encoding
Ablation of OctupleMIDI encoding
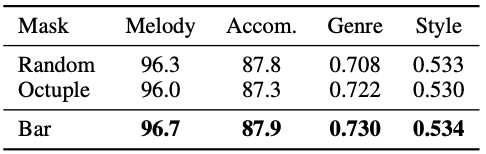 Ablation of bar-level masking
Ablation of bar-level masking
Training the model from scratch without pre-training also suggest the importance of self-supervised pre-training for better performance in the downstream tasks.
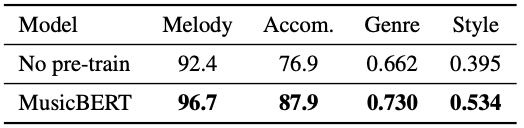 Effect of MusicBERT pre-training in music understanding tasks
Effect of MusicBERT pre-training in music understanding tasks