Significance
Keypoints
- Formulate knowledge distillation as a function matching to improve student performance
- Demonstrate performance and importance of consistent/patient knowledge distillation by experiments
Review
Background
Although scaling up models are pushing the limit of many computer vision tasks (for example in this previous post), these large models cannot be readily applied to practice due to high computational / hardware demands. Knowledge distillation, which refers to distilling the knowledge from a well-trained teacher model to another student model, can be a bridge between this gap of large scale models and the hardware limitation. Most previous knowledge distillation methods aim to match the student model’s prediction to that of the teacher model’s given an image from a same class. For example, input image augmentation, such as random cropping, are applied only to the student or independently to the teacher and the student model during training. The authors address that this practice restricts the knowledge distillation from the perspective of function matching between the teacher and the student.
Keypoints
Formulate knowledge distillation as a function matching to improve student performance
A good student should learn to correctly follow the teacher model’s mapping, and this can be assured by processing the same image augmentation to the teacher and the student during training.
The authors show that consistent teaching, which the teacher and the student receives consistent image augmentation, and function matching, which further employs mixup augmentation can significantly improve the student model’s performance.
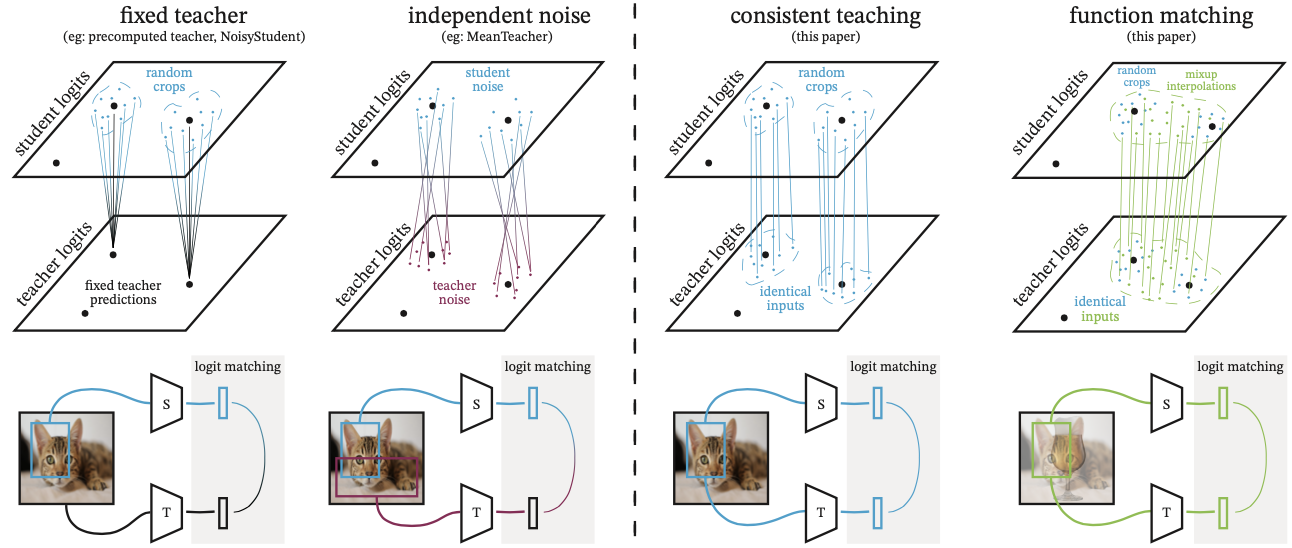 Examples of the knowledge distillation design choices
Examples of the knowledge distillation design choices
Viewing the knowledge distillation as a function matching, a more aggressive image augmentation can be applied during training because the teacher and student should output same logits even for a severely distorted input image. Thus, teaching with patience should follow the consistency because knowledge distillation as function matching has input manifold extending out of the original image domain support. From consistent and patient knowledge distillation, the authors show that the performance of the student model is significantly improved by experiments.
Demonstrate performance and importance of consistent/patient knowledge distillation by experiments
The authors experiment the consistent/patient knowledge distillation by distilling the knowledge from a ImageNet pre-trained BiT-ResNet-152x2 to a standard ResNet-50 architecture which has roughly 10x less parameters.
Evaluation of the consistency in knowledge distillation show that the proposed consistent teaching (skyblue in previous/next Figures) and function matching (green in previous/next Figures) leads to significantly better student performance on the Flowers102 dataset.
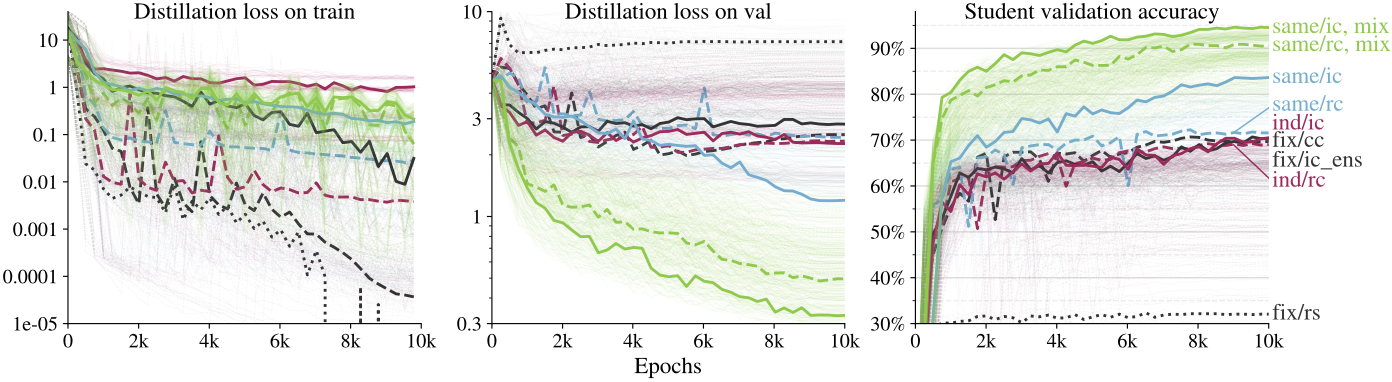 Importance of consistency in knowledge distillation. The line colors match the methods described in the previous figure.
Importance of consistency in knowledge distillation. The line colors match the methods described in the previous figure.
To evaluate the importance of patience, test accuracy during knowledge distillation with function matching is plotted with respect to the number of epochs.
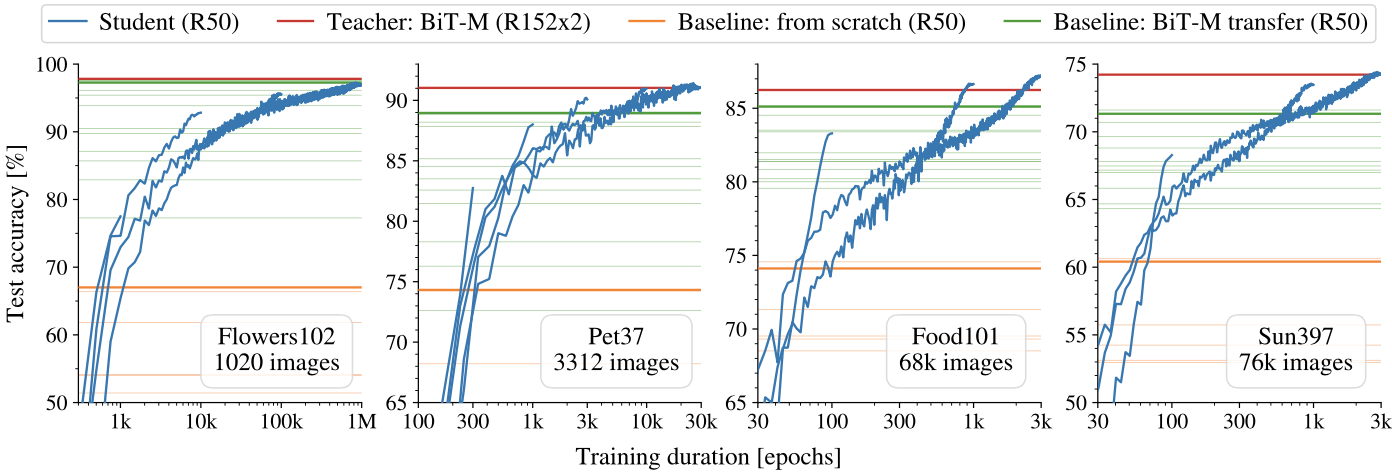 Importance of patience in knowledge distillation
Distilling the knowledge with function matching lets the student reach the performance of the teacher model (red line) if it is trained much longer than a standard supervised training setup.
It can also be seen that the student outperforms baseline models (i) ResNet-50 trained from scratch (orange line) and (ii) transferring ImageNet pre-trained ResNet-50 (green line).
Importance of patience in knowledge distillation
Distilling the knowledge with function matching lets the student reach the performance of the teacher model (red line) if it is trained much longer than a standard supervised training setup.
It can also be seen that the student outperforms baseline models (i) ResNet-50 trained from scratch (orange line) and (ii) transferring ImageNet pre-trained ResNet-50 (green line).
If the dataset is scaled up to the ImageNet, a vanilla ResNet-50 achieves 82.31\% top-1 accuracy when distilled from the BiT-ResNet-152x2, which is a state-of-the-art result for the vanilla ResNet model.
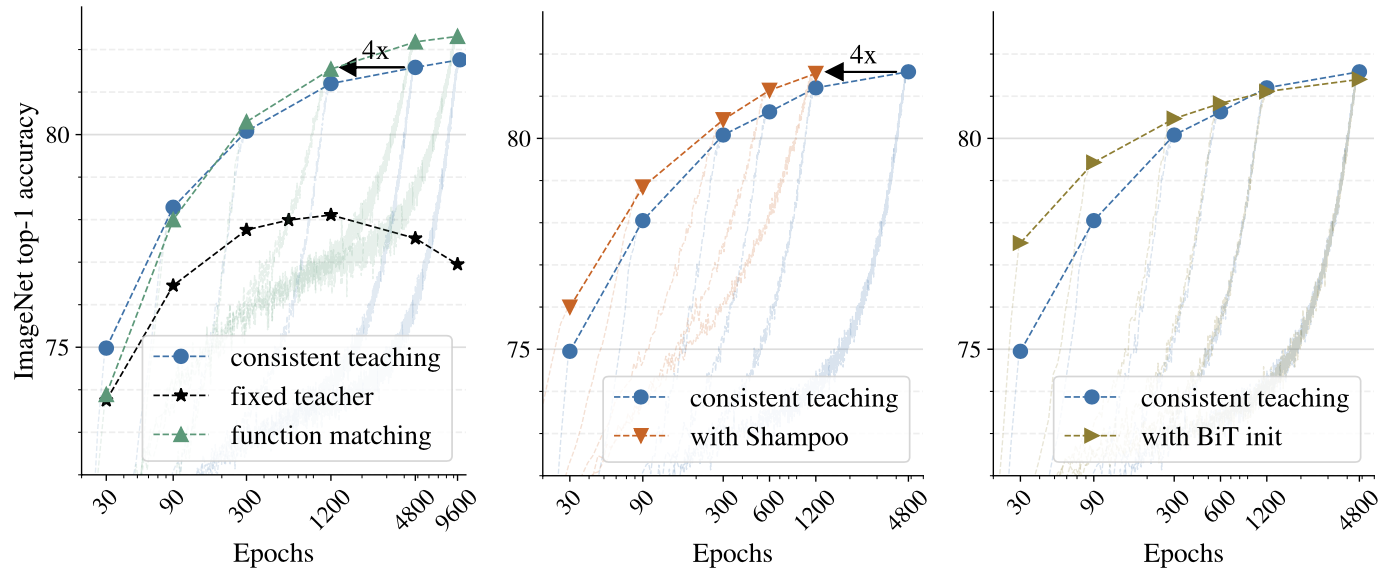 ImageNet distillation results
The authors further experiment two setups (i) changing the optimizer to Shampoo with the second order preconditioner, and (ii) initializing the student with pre-trained BiT-M-Resnet50 weights.
Shampoo optimizer and initializing with pre-trained weights tend to speedup the distillation process, but the final performance is not affected significantly.
ImageNet distillation results
The authors further experiment two setups (i) changing the optimizer to Shampoo with the second order preconditioner, and (ii) initializing the student with pre-trained BiT-M-Resnet50 weights.
Shampoo optimizer and initializing with pre-trained weights tend to speedup the distillation process, but the final performance is not affected significantly.
Interestingly, distilling on the out-of-domain data, such as distilling knowledge with Food101 dataset from a teacher model trained with Pets data, still works to some extent, which further justifies the importance of function matching in knowledge distillation.
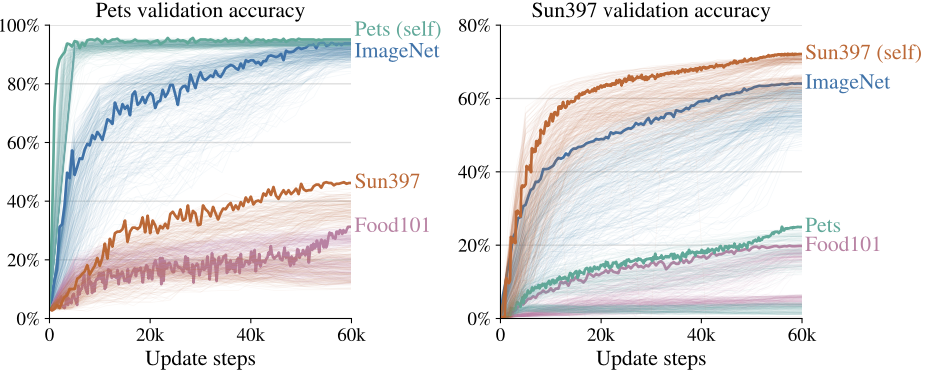 Distilling on the out-of-domain data
Distilling on the out-of-domain data
I would say that teaching the student model to follow the teacher model as a function (mapping) is like teaching someone how to fish, while teaching the student model with the teacher model’s prediction is like giving someone a fish. If the student learns how to fish, it probably can perform as good as its teacher.