Significance
Keypoints
- Propose a unified framework for image super-resolution and rescaling using normalizing flow
- Demonstrate performance of the proposed method by experiments
Review
Background
Normalizing flows are a class of generative models that aims to learn a bijective mapping between two different distributions with invertible neural networks. Recent studies have shown promising results in low-level computer vision tasks, such as image rescaling or image super-resolution, for applying normalizing flow (see my previous post for an example). This work proposes an unified approach for both image rescaling and super-resolution, which introduces better flexibility and usability for both tasks.
Keypoints
Propose a unified framework for image super-resolution and rescaling using normalizing flow
The process of image up/downscaling is based on the bijective transformation $\mathbf{x} \leftrightarrow [\mathbf{y}, \mathbf{a}]$ where $\mathbf{y}$ is the low-resolution (LR) image from the original image $\mathbf{x}$ and $\mathbf{a}$ is the corresponding high-frequency component.
Main idea of the proposed method is to again learn a bijective transformation between the high-frequency component $\mathbf{a}$ and a latent variable $\mathbf{z}$ with an invertible neural network.
Image downscaling can be explicitly performed with forward compuatation of wavelet transform while the upscaling without high-frequency prior, i.e. super-resolution, can be done with a randomly sampled latent variable $\mathbf{z}$ as a prior.
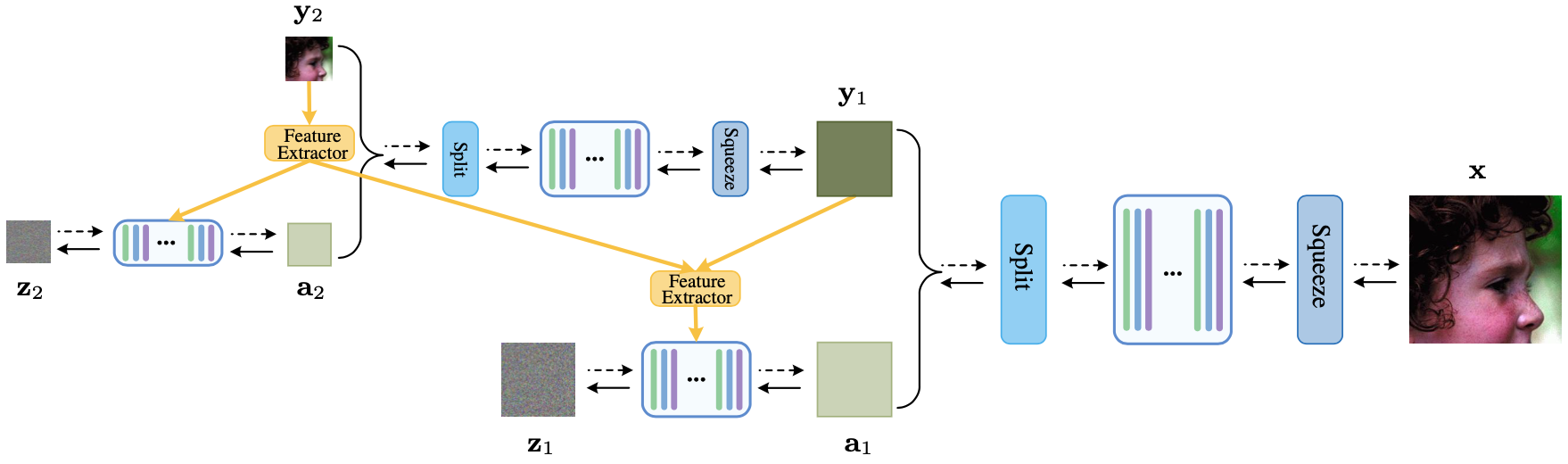 Schematic illustration of the proposed method
The feature extractor $\phi_{l}$ at level $l$ can be a convolution neural network (CNN).
Schematic illustration of the proposed method
The feature extractor $\phi_{l}$ at level $l$ can be a convolution neural network (CNN).
For training the model, negative log-likelihood can be basically minimized. Pixel-wise L1 loss and perceptual loss + GAN loss can further be employed, where the model trained with these adjunctive loss functions are referred to the HCFlow+ and HCFlow++, respectively.
Demonstrate performance of the proposed method by experiments
The performance of super-resolution is compared quantitatively and qualitatively on DIV2K dataset (4x) and the CelebA dataset (8x)
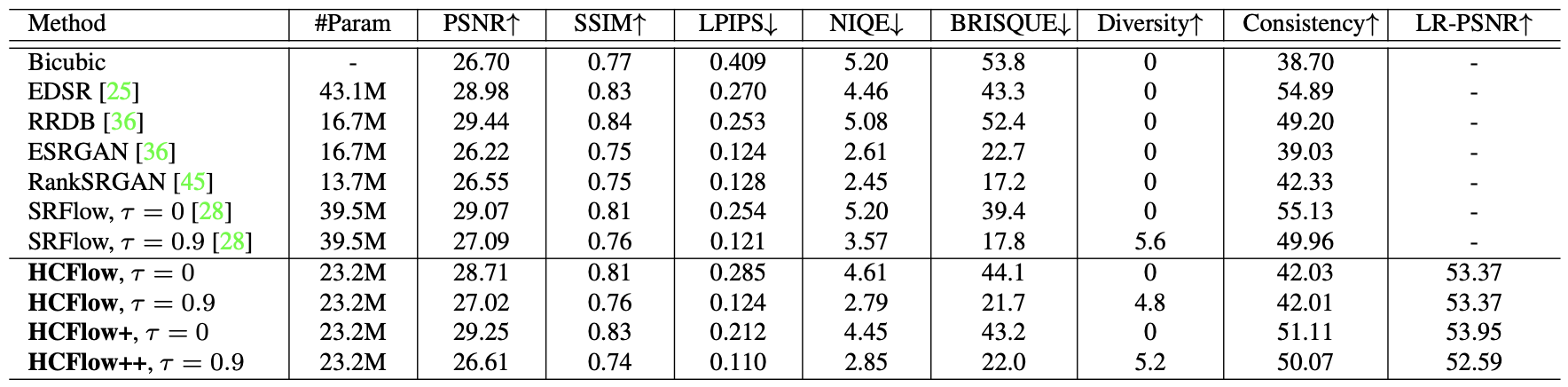 Quantitative performance on the DIV2K dataset (4x) super-resolution
Quantitative performance on the DIV2K dataset (4x) super-resolution
 Qualitative performance on the DIV2K dataset (4x) super-resolution
Qualitative performance on the DIV2K dataset (4x) super-resolution
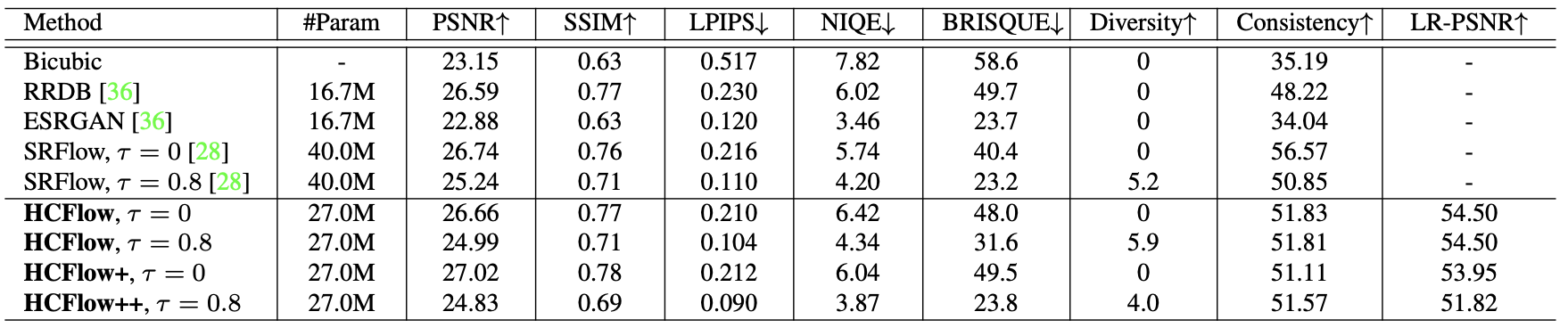 Quantitative performance on the CelebA dataset (8x) super-resolution
Quantitative performance on the CelebA dataset (8x) super-resolution
 Qualitative performance on the CelebA dataset (8x) super-resolution
Qualitative performance on the CelebA dataset (8x) super-resolution
The results demonstrate that the proposed method outperforms other baseline methods in terms of both PSNR/SSIM (HCFlow) and perceptual quality (LPIPS with HCFlow++) in super-resolution tasks.
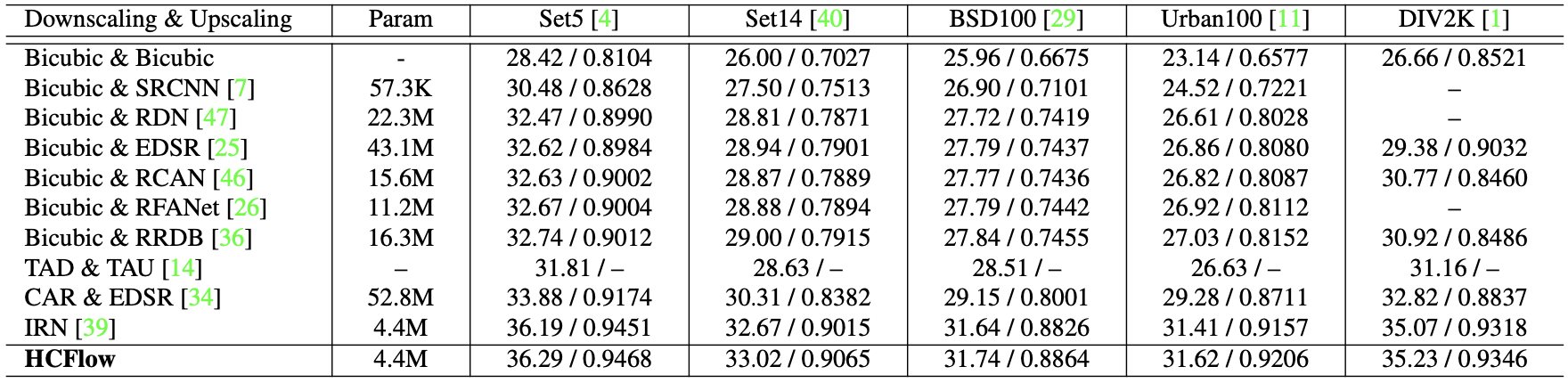 Quantitative performance on the DIV2K dataset (4x) image rescaling
Quantitative performance on the DIV2K dataset (4x) image rescaling
 Qualitative performance on the DIV2K dataset (4x) image rescaling
Qualitative performance on the DIV2K dataset (4x) image rescaling
Proposed HCFlow also outperforms previous flow-based image rescaling method IRN in the image rescaling task.