Significance
Keypoints
- Propose self-attention generator for high-resolution image generation with adversarial training
- Demonstrate performance of the HiT as a generator/decoder
Review
Background
Transformer models that rely on on self-attention is being widely adopted to computer vision tasks. However, applying the Transformer to image generation with adversarial training is still behind the trend. The main challenges of applying self-attention to GANs lies in (i) quadratic scaling problem of computational complexity, and (ii) a higher demand for spatial coherency. These issues are addressed by introducing efficient generator architecture with self-attention and self-modulation.
Keypoints
Propose self-attention generator for high-resolution image generation with adversarial training
The authors propose HiT, a GAN generator without any convolution operation.
To reduce computational cost, the HiT includes self-attention in only earlier layers which is responsible for low-resolution stages.
The efficiency of self-attention is further obtained by the multi-axis blocked self-attention architecture, which is similar to the AxialTransformer operation but with block splitting of the input features.
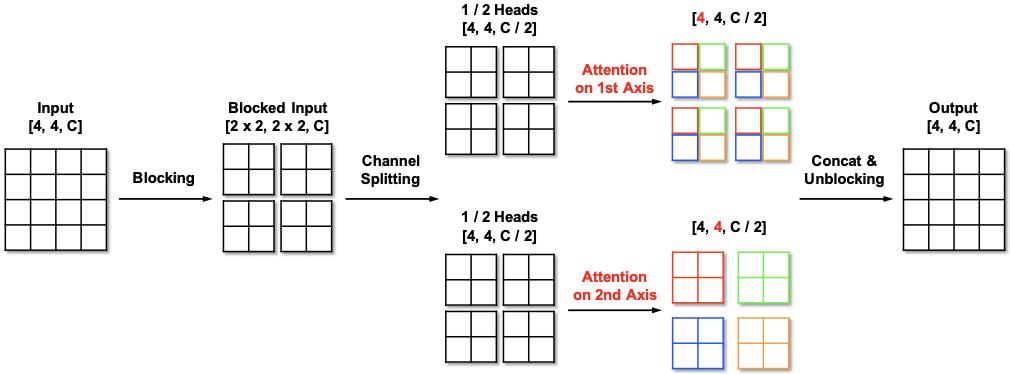 Multi-axis blocked self-attention
The attention of the multi-axis blocked self-attention is applied along the blocks and the pixels, which can be thought of regional and dilated attention, respectively.
Multi-axis blocked self-attention
The attention of the multi-axis blocked self-attention is applied along the blocks and the pixels, which can be thought of regional and dilated attention, respectively.
Later layers of HiT does not include self-attention but only the multi-layer perceptron (MLP) with linear complexity which further reduces the computational cost.
This is based on the assumption that the spatial dependency is already modeled in the earlier low-resolution stages of the generator.
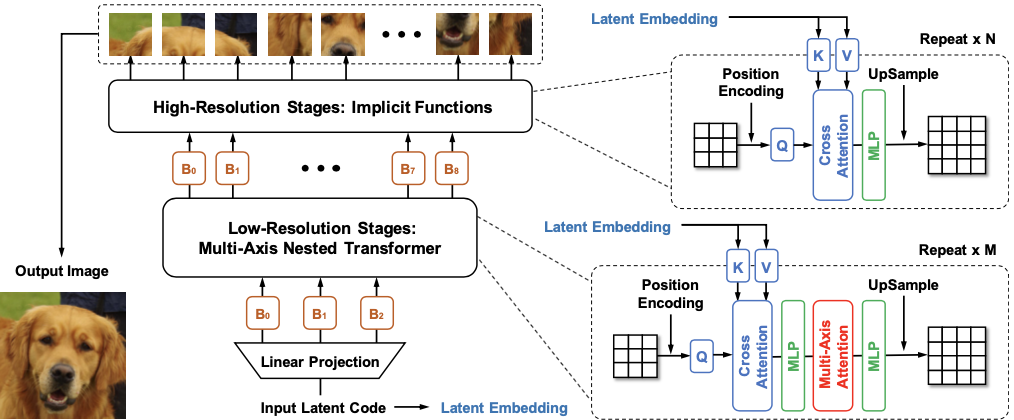 Schematic illustration of the proposed HiT
Schematic illustration of the proposed HiT
The last point of the HiT is the cross-attention for self-modulation. This is to improve the global information flow by letting the intermediate features to directly attend to the input latent.
Demonstrate performance of the HiT as a generator/decoder
The HiT can be used not only as a generator of the GAN, but also the decoder of the VAE too.
Performance of unconditional image generation with HiT as a generator of the GAN is first experimented with the ImageNet 128$\times$128 dataset.
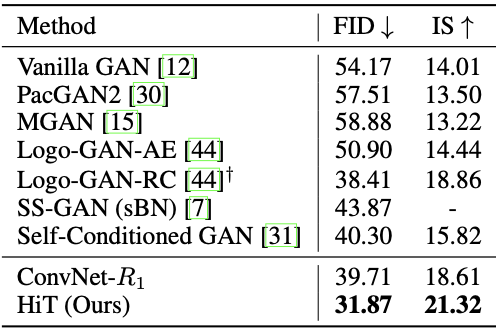 Performance of unconditional image generation on ImageNet 128$\times$128
Performance of unconditional image generation on ImageNet 128$\times$128
 Exemplar images of unconditional image generation from HiT
The reconstruction FID of HiT as a decoder of the VQ-VAE is also reported on the ImageNet 256$\times$256 dataset.
Exemplar images of unconditional image generation from HiT
The reconstruction FID of HiT as a decoder of the VQ-VAE is also reported on the ImageNet 256$\times$256 dataset.
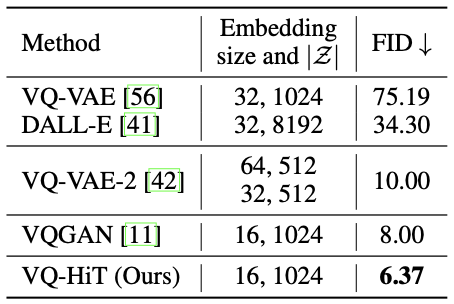 Performance of image reconstruction on ImageNet 256$\times$256
It can be seen that HiT achieves better FID score when compared to its CNN counterparts as a generator or a decoder.
Performance of image reconstruction on ImageNet 256$\times$256
It can be seen that HiT achieves better FID score when compared to its CNN counterparts as a generator or a decoder.
Higher resolution (256$\times$256 and 1024$\times$1024) image generation is experimented on the CelebA-HQ and the FFHQ datasets.
The results demonstrate that HiT obtains state-of-the-art FID scores at resolution of 256$\times$256.
However, HiT fell slightly behind the StyleGAN2 in terms of FID score at higher 1024$\times$1024 resolution.
 Quantitative results of the HiT on CelebA-HQ and FFHQ datasets
Quantitative results of the HiT on CelebA-HQ and FFHQ datasets
 Qualitative results of the HiT on CelebA-HQ dataset
Qualitative results of the HiT on CelebA-HQ dataset
Ablation studies, throughput comparison, and evaluation of regularization effects are referred to the original paper.