Significance
Keypoints
- Propose a token level mixup augmentation method for text classification
- Demonstrate improvement of text classification performance using the proposed augmentation
Review
Background
Mixup is a widely adopted data augmentation method for computer vision tasks. Application of mixup to natural language processing is more challenging due to discrete nature of text data and variable sequence lengths. Most previous attempts to bring mixup to natural language is performed on the hidden feature level due to these difficulties. The authors address the issue that mixup augmentation at the input token level, as in the case of mixup augmentation of image data, would result in better performance and propose a saliency guided span mixup method.
Keypoints
Propose a token level mixup augmentation method for text classification
The authors propose SSMix, an intuitive saliency based mixup method which operates on the input token level.
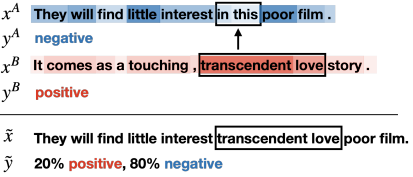 Illustration of the proposed SSMix
Given a pair of input data $(x^{A},x^{B})$ and corresponding labels $(y^{A},y^{B})$ the augmentation data $\tilde{x}$ is obtained by replacing the span from $x^{A}$ to a span from $x^{B}$ with the same length.
In this process, the span is selected by the gradient-based saliency $s=||\partial \mathcal{L} / \partial e||_{2}$ where the span with lowest saliency $s$ from $x^{A}$ is replaced by the span with highest $s$ from $x^{B}$.
The mixup ratio for computing the augmentation label $\tilde{y}$ follows the ratio of the replaced span length with respect to the total length of $\tilde{x}$.
Illustration of the proposed SSMix
Given a pair of input data $(x^{A},x^{B})$ and corresponding labels $(y^{A},y^{B})$ the augmentation data $\tilde{x}$ is obtained by replacing the span from $x^{A}$ to a span from $x^{B}$ with the same length.
In this process, the span is selected by the gradient-based saliency $s=||\partial \mathcal{L} / \partial e||_{2}$ where the span with lowest saliency $s$ from $x^{A}$ is replaced by the span with highest $s$ from $x^{B}$.
The mixup ratio for computing the augmentation label $\tilde{y}$ follows the ratio of the replaced span length with respect to the total length of $\tilde{x}$.
Theoretically, input token level mixup can be thought of a nonlinear combination of the input pairs $(x^{A},x^{B})$ covering a higher dimensional subspace of the input space, while previous hidden level linear interpolation mixup stays within the 1 dimensional subspace between the $x^{A}$ and the $x^{B}$.
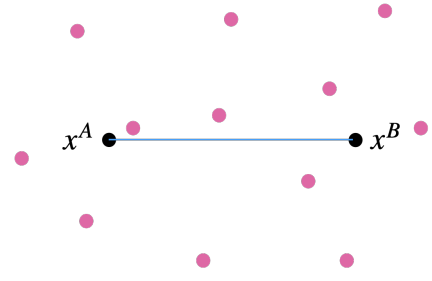 Subspace coverage of SSMix (pink) and hidden-level mixup (black)
Subspace coverage of SSMix (pink) and hidden-level mixup (black)
Demonstrate improvement of text classification performance using the proposed augmentation
Effectiveness of SSMix is evaluated on eight datasets including SST-2, MNLI, QNLI, RTE, MRPC, QQP (from the GLUE benchmark), TREC, and ANLI.
The datasets include both single sentence classification and sentence pair classification tasks.
Average accuracy with SSMix is significantly higher when compared to other baseline hidden-level mixup methods (EmbedMix, TMix).
Ablation study results also suggest that the saliency and span level augmentation of the SSMix is crucial for achieving its good performance.
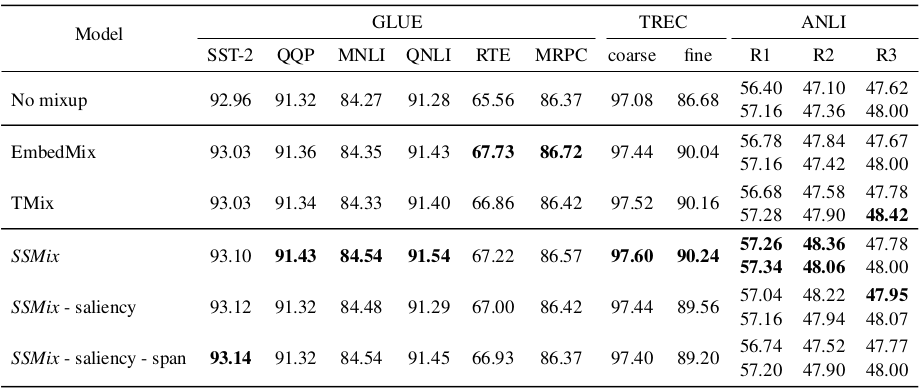 Comparative and ablation study results of the proposed SSMix
Comparative and ablation study results of the proposed SSMix
The experiment results suggest that this simple and intuitive method can improve the performance of text classification.