Significance
Keypoints
- Develop an email thread dataset with human-labeled summary annotation
- Compare summarization performance of benchmark models on the developed dataset
Review
Background
An email thread is a special type of dialogue between a sender and receivers with specific structure. Summarizing email threads have been less studied compared to summarizing dialogues or discussion threads. Lack of summary-annotated email thread dataset accounts for the difficulty in training an email thread summarization model. To address this issue, the authors developed an email thread dataset with human-labeled summary annotation.
Keypoints
Develop an email thread dataset with human-labeled summary annotation
To collect email thread summarization data, the authors used existing email datasets including Enron, W3C, and Avocado. Since previous datasets do not explicitly provide thread structure, the datasets are grouped by senders and receivers to formulate threads. Other preprocessing steps are further done which includes de-duplication, anonymization, filtering by length, etc.
The summary of the email threads are then human annotated on the Amazon Mechanical Turk. Short (<30 words) and long (<100 words) abstract summaries are obtained per thread, yielding 2,549 email threads with short and long summary.
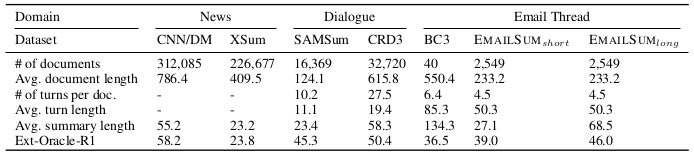 Statistics of the EmailSum dataset
Statistics of the EmailSum dataset
Compare summarization performance of benchmark models on the developed dataset
Summarization performance of various baseline models are evaluated on the EmailSum dataset.
Oracle, Lead, TextRank, and BertSumExt are tested for extractive summarization, while FastAbsRL, T5 are tested for abstractive summarization.
The authors further incorporate hierarchical summarization to the T5 model, proposing a new hierarchical T5 for better email thread summarization.
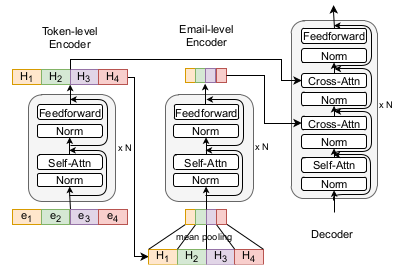 Schematic illustration of the hierarchical T5
Schematic illustration of the hierarchical T5
Transfer learning (CNNDM, XSum, SAMSum, CRD3) and semi-supervised learning settings are also experimented.
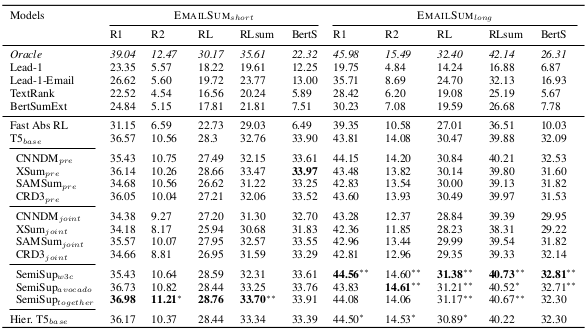 Summarization performance of benchmark models on the EmailSum dataset
It can be seen that the hierarchical T5 performs best on the long summarization EmailSum data, while the original T5 marginally performs better on the short summarization data.
The summary quality was evaluated in terms of automatic evaluation methods ROUGE and BERTScore.
Summarization performance of benchmark models on the EmailSum dataset
It can be seen that the hierarchical T5 performs best on the long summarization EmailSum data, while the original T5 marginally performs better on the short summarization data.
The summary quality was evaluated in terms of automatic evaluation methods ROUGE and BERTScore.
The authors further checked whether the automatic evaluation methods were reliable by comparing with human evaluation of the summarization text.
It was found that the correlation between the automatic metrics and human judgment was not sufficient, suggesting that better automatic text evaluation methods need to be developed in the future.
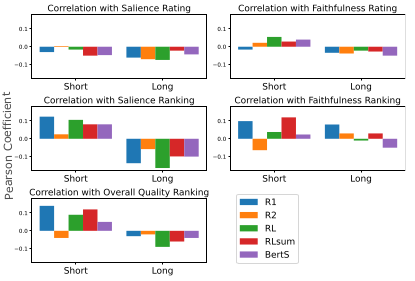 Correlation between the automatic evaluation methods and human evaluation
Correlation between the automatic evaluation methods and human evaluation