Significance
Keypoints
- Propose a multi-layer perceptron model with spatial gating
- Demonstrate comparable performance to self-attention models in both computer vision and NLP tasks
Review
Background
Multi-layer perceptrons (MLPs) are a stack of linear transformation with nonlinear units in each layer. Although the MLP is one of the earliest inventions in realizing machine intelligence, its practical role had been underestimated until recently. MLP-only models, such as MLP-Mixer and ResMLP are being introduced in a fast pace. A more surprising fact is that these models showed promising performance on computer vision tasks. This work is in line with this trend, and proposes gated MLP (gMLP) which performs on-par with self-attention models on computer vision and natural language processing (NLP) tasks.
Keypoints
Propose a multi-layer perceptron model with spatial gating
The gMLP block takes input embeddings identical to that of BERT embeddings.
The proposed gMLP block is described on the below figure and the pseudocode.
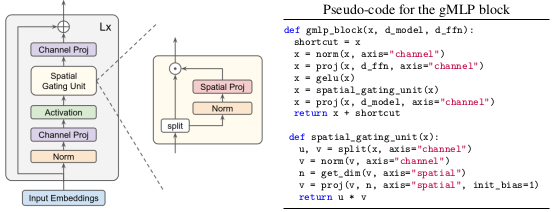 Scheme and pseudocode of gMLP
The model can be thought of performing a set of channel projections and a spatial interaction modeling function $s$:
\begin{align}
Z = \sigma(XU) \\ \tilde{Z} = s(Z) \\ Y = \tilde{Z}V
\end{align}
where $X$ is the input. $U$, $V$ are linear channel projection layers, $\sigma$ is the GELU activation.
The authors propose spatial gating unit (SGU) to serve as the function $s$:
\begin{align}
s(Z) = Z \odot (WZ+b)
\end{align}
where $W$ is a linear projection matrix and $b$ is the corresponding bias.
The authors find it effective to split the input $Z$ channel-wise to obtain $(Z_{1}, Z_{2})$ and compute
\begin{align}
s(Z) = Z_{1} \odot (WZ_{2}+b)
\end{align}
as the SGU.
Scheme and pseudocode of gMLP
The model can be thought of performing a set of channel projections and a spatial interaction modeling function $s$:
\begin{align}
Z = \sigma(XU) \\ \tilde{Z} = s(Z) \\ Y = \tilde{Z}V
\end{align}
where $X$ is the input. $U$, $V$ are linear channel projection layers, $\sigma$ is the GELU activation.
The authors propose spatial gating unit (SGU) to serve as the function $s$:
\begin{align}
s(Z) = Z \odot (WZ+b)
\end{align}
where $W$ is a linear projection matrix and $b$ is the corresponding bias.
The authors find it effective to split the input $Z$ channel-wise to obtain $(Z_{1}, Z_{2})$ and compute
\begin{align}
s(Z) = Z_{1} \odot (WZ_{2}+b)
\end{align}
as the SGU.
One additional architectural supplement is to add a tiny self-attention module to the gating unit for masked language models, namely the attention MLP (aMLP).
 Tiny attention of aMLP block
The aMLP with small self-attention embedding dimension was sufficient to achieve better fine-tuning performance on NLP tasks than the baseline gMLP model.
Tiny attention of aMLP block
The aMLP with small self-attention embedding dimension was sufficient to achieve better fine-tuning performance on NLP tasks than the baseline gMLP model.
Demonstrate comparable performance to self-attention models in both computer vision and NLP tasks
Image classification
The gMLP is compared with CNNs (ResNet, EfficientNet, NFNet), ViTs (ViT, DeiT), and MLPs (Mixer, ResMLP) for image classification performance on the ImageNet-1K dataset.
The results indicate that gMLP performs at least similar to most CNNs and ViTs.
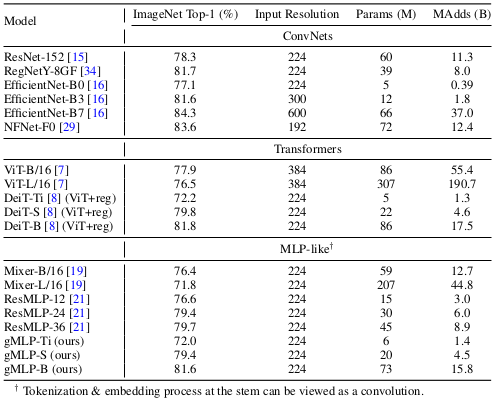 Quantitative comparative study results
Quantitative comparative study results
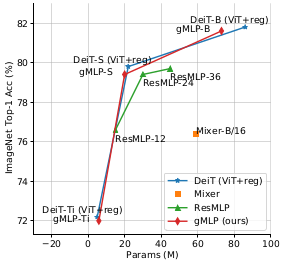 ImageNet accuracy with respect to the model capacity
ImageNet accuracy with respect to the model capacity
Masked language modeling (MLM)
The MLM of gMLP is compared with the BERT.
The gMLP does not need positional encodings or $\langle \texttt{pad} \rangle$ tokens unlike BERT.
Results indicate that the split SGU gMLP achieves comparable perplexity to BERT.
 MLM perplexity of gMLP and BERT
Scaling up the gMLP showed that a deep gMLP can be trained to match or even outperform Transformer in terms of perplexity.
MLM perplexity of gMLP and BERT
Scaling up the gMLP showed that a deep gMLP can be trained to match or even outperform Transformer in terms of perplexity.
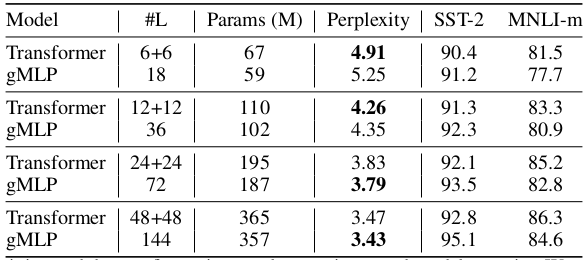 Scaling up gMLP and Transformer
The aMLP showed improved perplexity when compared to gMLP, and even outperforms BERT base models.
Furthermore, the aMLP outperformed other baselines on downstream fine-tuning tasks on SST-2, MNLI, and SQuAD.
Scaling up gMLP and Transformer
The aMLP showed improved perplexity when compared to gMLP, and even outperforms BERT base models.
Furthermore, the aMLP outperformed other baselines on downstream fine-tuning tasks on SST-2, MNLI, and SQuAD.
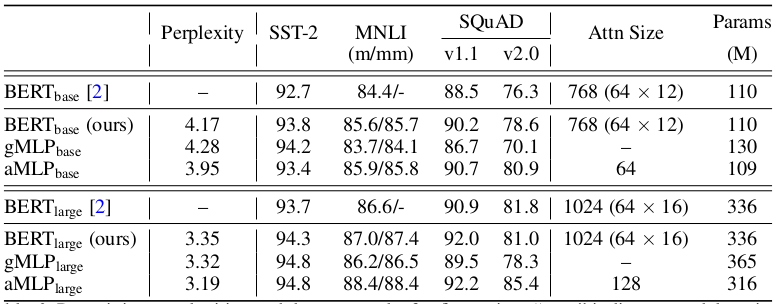 Performance of aMLP, gMLP and BERT. (ours) denotes training setup by the authors not the model
Performance of aMLP, gMLP and BERT. (ours) denotes training setup by the authors not the model
Other qualitative analysis of the gMLP, aMLP models are referred to the original paper. We have seen the potential power of the MLP models recently, and it did not take a month to find it outperform the self-attention models. The MLPs are really taking over the game now.