Significance
Keypoints
- Propose a method to evaluate generated text from various perspectives with pre-trained BART
- Demonstrate correlation of proposed method with human judgment
Review
Background
The gold standard for evaluating the quality of generated text is to perform costly human evaluation. Although many recent natural language processing (NLP) models have been studied for evaluating the quality of the text with respect to the reference as in BERTScore, these methods still cannot provide quantitative evaluation of the generation quality from diverse perspectives. The perspectives of evaluation can include informativeness (Info), relevance (Rel), fluency (Flu), coherence (Coh), factualty (Fac), semantic coverage (Cov), adequacy (Ade). The authors focus on auto-regressive seq2seq tasks, which can be thought of a conditional text generation: \begin{align} p(\mathbf{y}|\mathbf{x},\theta) = \Pi^{m}_{t=1} p(\mathbf{y}_{t}|\mathbf{y}_{<t},\mathbf{x},\theta) \end{align} where $\mathbf{x}$ is the given condition and $\mathbf{y}$ is the generated text, and $\theta$ is the pre-trained model.
Keypoints
Propose a method to evaluate generated text from various perspectives with pre-trained BART
BART is a pre-trained seq2seq model based on encoder and decoder of the Transformer. The authors propose BARTScore, which is simply the weighted log probability sum of $\mathbf{y}$ given $\mathbf{x}$: \begin{align} \mathrm{BARTScore} = \sum^{m}_{t=1}w_{t} \log p(\mathbf{y}_{t}|\mathbf{y}_{<t}, \mathbf{x}, \theta). \end{align} The weighting term $w_{t}$ can be defined from different previous methods like Inverse Document Frequency. BARTScore fully utilize the pre-trained parameters of BART, enabling evaluation of the generated text from different directions such as faithfulness (source $\rightarrow$ generated), precision (reference $\rightarrow$ generated), recall (generated $\rightarrow$ reference), and $\mathcal{F}$ score (reference $\leftrightarrow$ generated). Extension of BARTScore using prompting and fine-tuning is suggested to further improve the evaluation performance.
Demonstrate correlation of proposed method with human judgment
The proposed BARTScore is experimented on the quality evaluation of machine translation (WMT19), text summarization, and data-to-text datasets.
BARTScore enhanced by fine-tuning tasks (CNN+Para) outperforms other unsupervised methods, and the performance is further improved by adding the prompt.
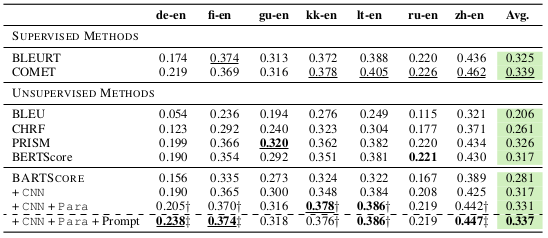 Performance by correlation with human judgment on WMT19 dataset (machine translation)
Performance by correlation with human judgment on WMT19 dataset (machine translation)
BARTScore also outperforms other methods on the summarization task.
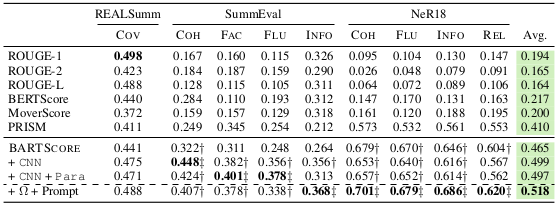 Performance of text summarization on REALSumm, SummEval-CNNDM, NeR18-newsroom datasets
Performance of text summarization on REALSumm, SummEval-CNNDM, NeR18-newsroom datasets
Experiment on data-to-text datasets also demonstrate excellent correlation score of the proposed BARTScore.
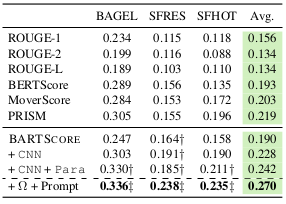 Performance of data-to-text on BAGEL, SFRES, SFHOT datasets
Performance of data-to-text on BAGEL, SFRES, SFHOT datasets
Results suggest that BARTScore can be utilized as an quantitative evaluation metric for text generation tasks. Further analysis of the experiments are referred to the original paper.