Significance
Keypoints
- Suggest better ViT training practices by extensive and well-controlled experiments
Review
Background
As ViTs are becoming one of the standards for many computer vision tasks, well controlled large-scale studies on their behavior such as robustness, scaling, are being studied.
This paper studies what the best practice is for training the ViT.
Extensive study results are provided with interpretations on better training practices in this paper, and the trained models are publicly available online too.
The authors study the effect of augmentation and regularization (AugReg), effect of pre-training and transfer, effect of dataset size, and effect of patch size on ViTs with different number of parameters (ViT-Ti < ViT-S < ViT-B < ViT-L).
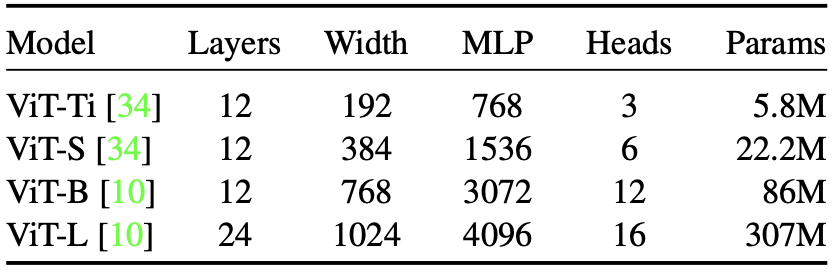 ViT models experimented in this paper
ViT models experimented in this paper
Keypoints
Suggest better ViT training practices by extensive and well-controlled experiments
Scaling datasets with AugReg and compute
A combination of 28 configurations with different dropout/stochastic depth, data augmentation setups, weight decay are used for comparing the effect of AugReg.
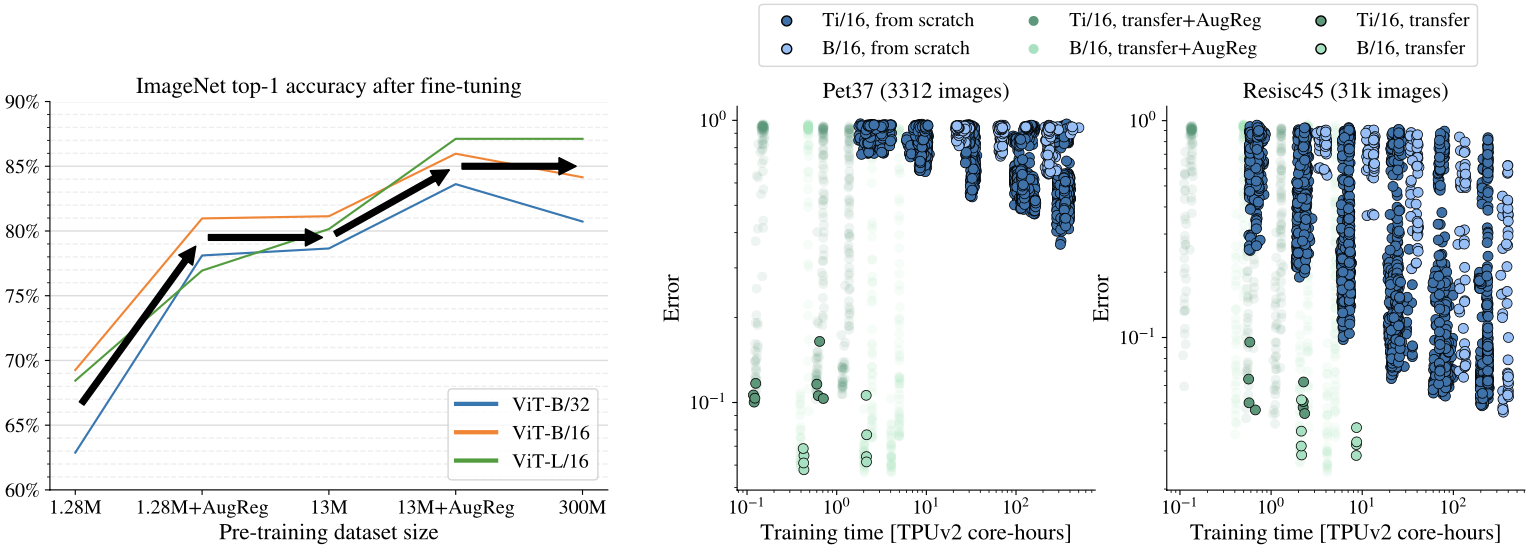 Effect of appropriate AugReg (left), effect of pre-training with transfer (right)
Effect of appropriate AugReg (left), effect of pre-training with transfer (right)
From the left of the above figure, it can be seen that adding appropriate AugReg can improve the test performance to a level that matches to increasing the dataset size.
Transfer is the better option
Comparing fine-tuning of pre-trained models vs training from scratch resulted in that transfer is the better option. From the right of the above figure, it can be seen that training from scratch with small- and mid-sized datasets can hardly achieve a test error that can be trivially attained by fine-tuning the pre-trained model.
More data yields more generic models
Effect of dataset size for pre-training the ViTs is experimented on the VTAB dataset with 19 diverse tasks.
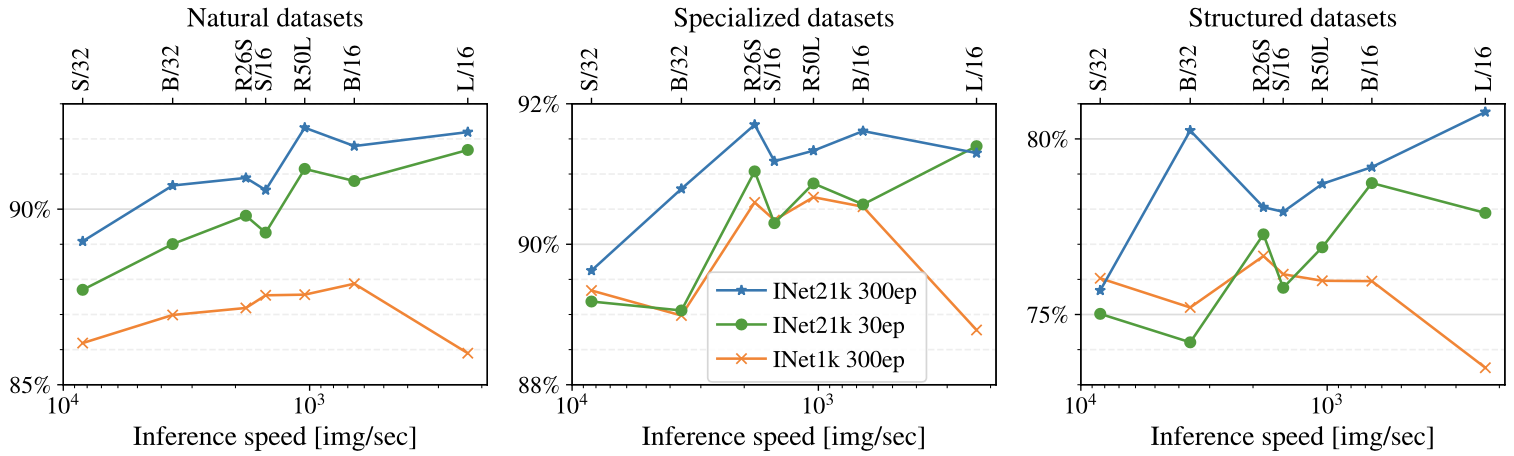 Dataset size effect for pre-training the ViTs
It can be seen that pre-training the model with larger dataset for sufficient training epochs (blue line) yields a more generic model that is better transferred to diverse tasks.
Dataset size effect for pre-training the ViTs
It can be seen that pre-training the model with larger dataset for sufficient training epochs (blue line) yields a more generic model that is better transferred to diverse tasks.
Prefer augmentation to regularization
Validation accuracy with respect to various amounts of augmentation and regularization are experimented.
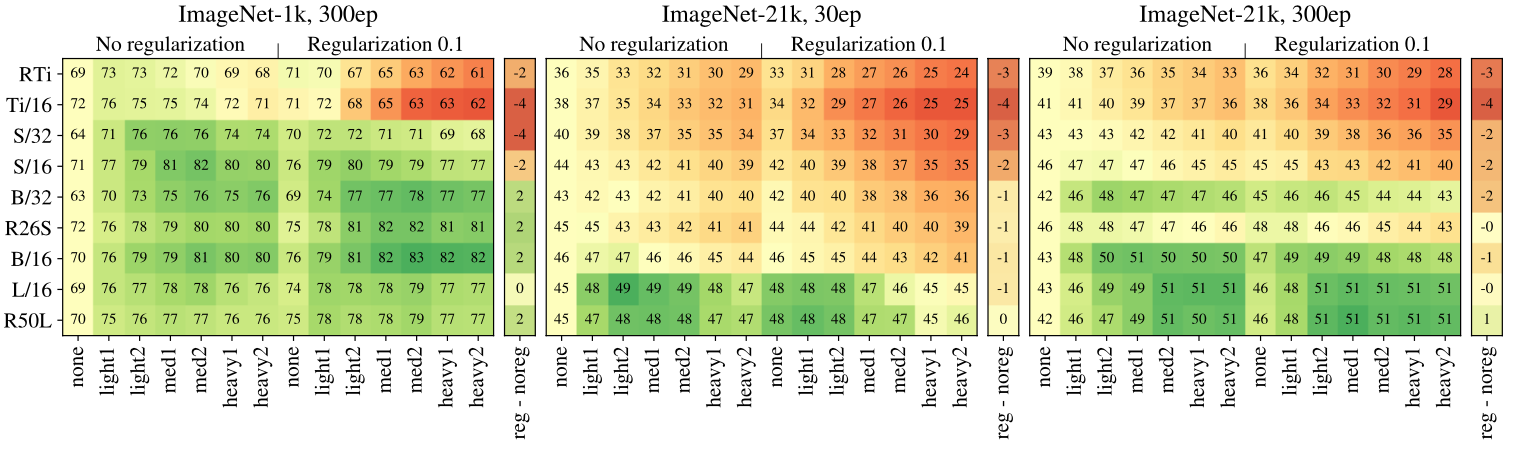 Comparing different amount of augmentation and regularization
It can be seen that almost every AugReg helps when training with small sized dataset (left of above figure), but almost every AugReg hurts when the dataset is larger (middle of above figure).
The AugReg can help for larger datasets if the compute is also increased to 300 epochs (right of above figure).
Generally, it can be said that augmentation usually helps better than regularization.
I wonder what the result would be like if the weight decay was applied only to the head of the ViT as suggested in this work.
Comparing different amount of augmentation and regularization
It can be seen that almost every AugReg helps when training with small sized dataset (left of above figure), but almost every AugReg hurts when the dataset is larger (middle of above figure).
The AugReg can help for larger datasets if the compute is also increased to 300 epochs (right of above figure).
Generally, it can be said that augmentation usually helps better than regularization.
I wonder what the result would be like if the weight decay was applied only to the head of the ViT as suggested in this work.
Choosing which pre-trained model to transfer
The authors compare two options for selecting the pre-trained models to transfer.
One is just choosing the best pre-trained model with the best performance during pre-training (which is cheaper), and the other is choosing the best model by testing each of their fine-tuning performance (which is more expensive).
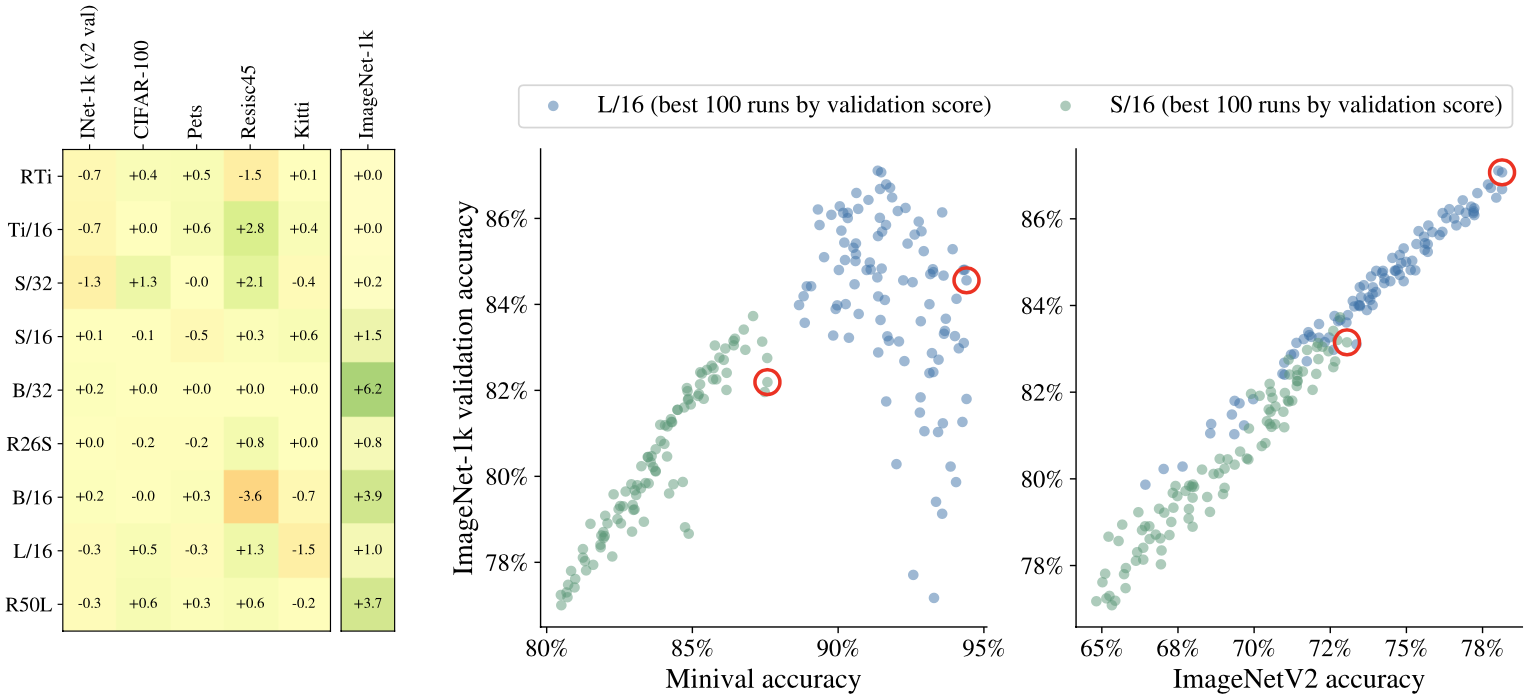 Gain/loss by choosing with cheaper strategy (left), validating with minval accuracy vs ImageNetV2 accuracy (right)
The authors suggest that using the cheaper strategy is generally cost-effective, but should be aware that there can be outliers.
Gain/loss by choosing with cheaper strategy (left), validating with minval accuracy vs ImageNetV2 accuracy (right)
The authors suggest that using the cheaper strategy is generally cost-effective, but should be aware that there can be outliers.
Prefer increasing patch-size to shrinking model-size
The last practical tip for training the ViT is to prefer increasing patch-size to shrinking model-size.
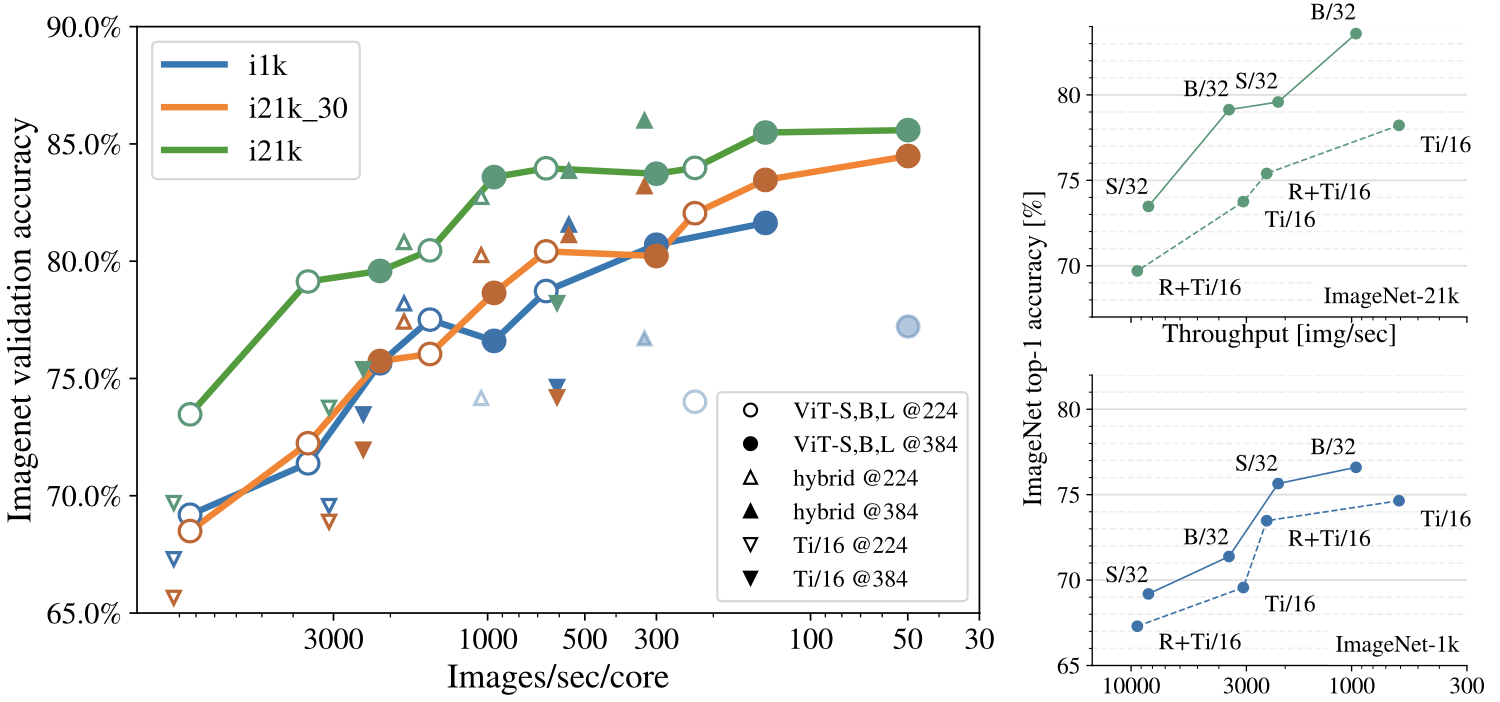 Plot of various ViT training settings for ImageNet-1k transfer (left) patch-size vs model-size (right)
Plot of various ViT training settings for ImageNet-1k transfer (left) patch-size vs model-size (right)
It is evident that using a larger patch size outperforms making the model thinner when focusing on training efficiency (right of above figure).
A plot of various ViT training setting results for ImageNet-1k is also provided on the left of the above figure.