Significance
Keypoints
- Propose a diffusion based image synthesis and editing method
- Demonstrate performance of the proposed method by experiments
Review
Background
Application of the diffusion models is one of the hottest topic in generative models (see previous posts for diffusion models on image synthesis 1, 2). Some of the key applications of the generative model include image synthesis, which is to synthesize a realistic image from a known random distribution (e.g. Gaussian noise), or semantic image manipulation, which is to edit an image in a semantically natural way. GANs have been studied widely as the state-of-the-art generative model for both image synthesis and image manipulation since the perceptual quality of GANs have been better than other methods. However, recent improvements of the diffusion models suggest that diffusion models are capable of generating better quality images when compared to GAN. This work further show that diffusion models are also easily applicable to image manipulation tasks, overcoming drawbacks of GAN based image manipulation methods including (i) need for latent space search optimization, (ii) difficulty of defining appropriate loss function, or (iii) need for ground-truth paired data.
Keypoints
Propose a diffusion based image synthesis and editing method
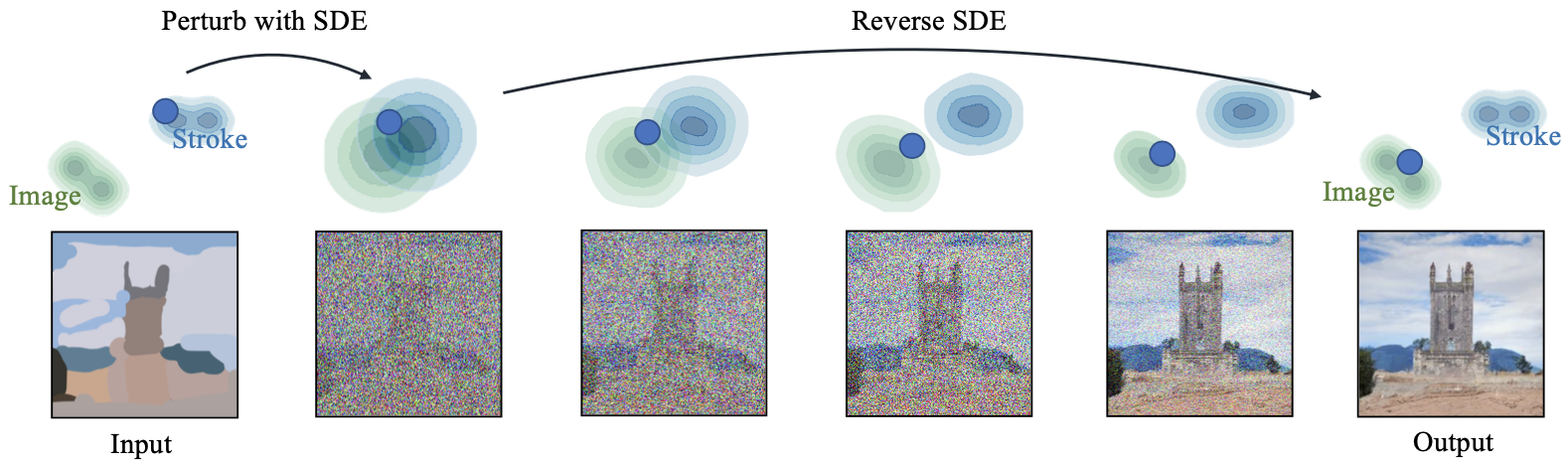 Schematic illustration of the proposed method
Schematic illustration of the proposed method
The proposed method is surprisingly simple. Given a diffusion model for image synthesis, the authors try to hijack the reverse process based on the fact that the images to be denoised are still of very low quality (prone to noise) on early steps of the reverse process. The authors adopt Stochastic Differential Equation (SDE) as the diffusion model and demonstrate good results.
 Pseudocode for image synthesis with SDEdit
Pseudocode for image synthesis with SDEdit
 Pseudocode for image manipulation with SDEdit
Pseudocode for image manipulation with SDEdit
As mentioned earlier, the proposed method (SDEdit) (i) does not require optimization of the latent space since the reverse process is performed directly on the corrupted (i.e. user marked with stroke) sample, (ii) does not require defining the loss between the stroke mask and the real counterpart, and (iii) does not require paired data since it exploits a diffusion model trained for image synthesis.
Demonstrate performance of the proposed method by experiments
The performance of the proposed method is mostly compared to GAN-based methods qualitatively. For quantitative results, Mechanical Turk human evaluation was performed to evaluate preference over the proposed method versus other baseline methods.
Stroke-based image synthesis
Stroke based image synthesis is compared to other methods on LSUN and CelebA dataset.
 Comparative result of stroke-based image synthesis on LSUN bedroom
Comparative result of stroke-based image synthesis on LSUN bedroom
 Qualitative result of proposed SDEdit on other datasets
Qualitative result of proposed SDEdit on other datasets
It can be seen that the proposed method generates images based on user strokes with better quality
 Faithfulness result of stroke-based image synthesis (human preference vs. SDEdit)
In the human evaluation, SDEdit is more often preferred over GAN baselines in stroke-based image synthesis.
Faithfulness result of stroke-based image synthesis (human preference vs. SDEdit)
In the human evaluation, SDEdit is more often preferred over GAN baselines in stroke-based image synthesis.
Stroke based image manipulation
For image manipulation task, SDEdit was compared on LSUN, CelebA, and FFHQ datasets.
 Comprative result of stroke-based image manipulation on LSUN, CelebA datasets
Comprative result of stroke-based image manipulation on LSUN, CelebA datasets
 Comparative result of stroke-based image manipulation on FFHQ dataset
Comparative result of stroke-based image manipulation on FFHQ dataset
It is also qualitatively suggested that the edited image is of better perceptual quality with the proposed SDEdit.
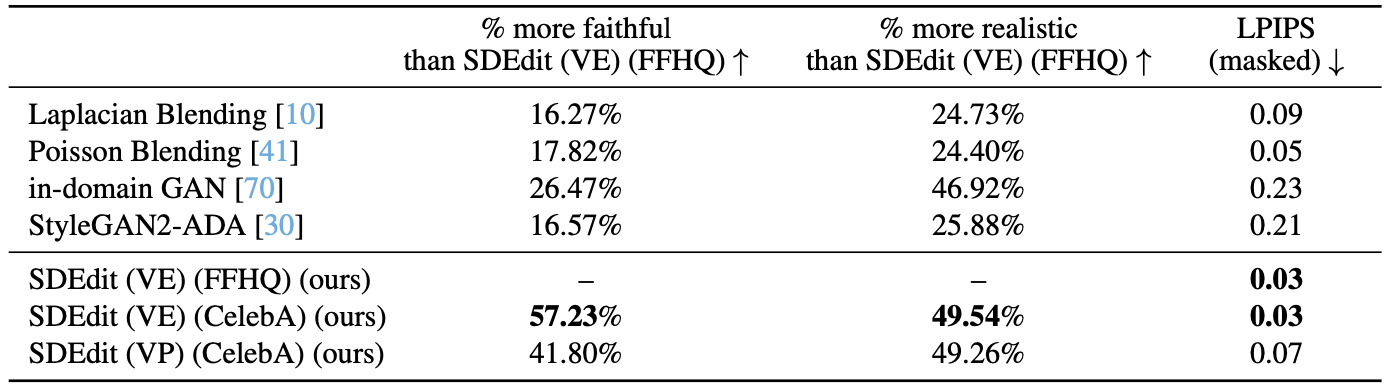 Faithfulness result of stroke-based image editing (human preference vs. SDEdit)
Human evaluation also suggests preference of SDEdit over GAN based image editing results.
Faithfulness result of stroke-based image editing (human preference vs. SDEdit)
Human evaluation also suggests preference of SDEdit over GAN based image editing results.
Related
- A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
- Collaborative Score Distillation for Consistent Visual Synthesis
- Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
- Palette: Image-to-Image Diffusion Models
- RewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image