Significance
Keypoints
- Propose a method for scene text editing from in the wild images
- Demonstrate performance of the proposed method over baseline image translation models
Review
Background
Scene text editing refers to the task of replacing text in a scene to a desired text while preserving the style. Previous methods usually perform scene text editing by removing the text from the scene, followed by generating the desired text into the scene. The authors address the issue that styles that lies within the text are hard to be incorporated to the final edited image for the previous methods, and propose a method that incorporates text representation to the scene text editing framework.
Keypoints
Propose a method for scene text editing from in the wild images
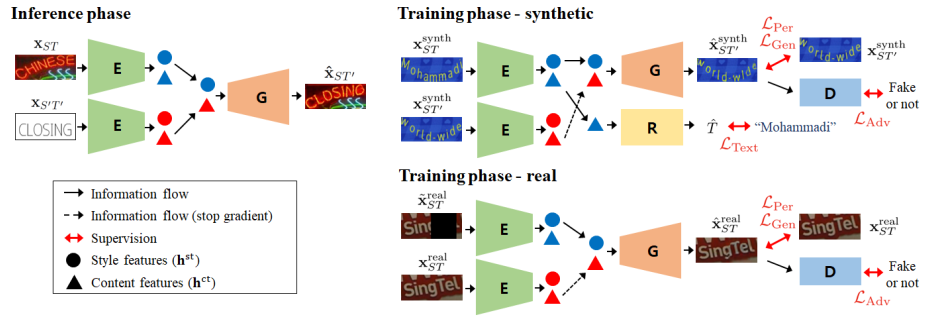 Schematic illustration of the proposed method
Above figure demonstrates the idea of the proposed method where $S$ and $T$ denotes style and text, respectively.
The encoder $E$ encodes style and content representation features of the scene text image, while the generator $G$ generates corresponding image from the style and content features.
Schematic illustration of the proposed method
Above figure demonstrates the idea of the proposed method where $S$ and $T$ denotes style and text, respectively.
The encoder $E$ encodes style and content representation features of the scene text image, while the generator $G$ generates corresponding image from the style and content features.
The training phase can be performed in two ways, based on whether the data is synthetic or real. For training with synthetic data, ground truth image and text are both available, making it possible to train both the generated image and the content output of the encoder in a fully-supervised way. In the other hand, training with real data is done in a self-supervised manner by corrupting the target image to serve as an input to the encoder. To make the generated images more realistic, adversarial training is applied to both the synthetic and the real data training.
Demonstrate performance of the proposed method over baseline image translation models
Performance of the proposed method is compared to baseline image translation and scene text editing methods including MUNIT, EGSC, and ETIW.
 Qualitative performance of the proposed method
Qualitative performance of the proposed method
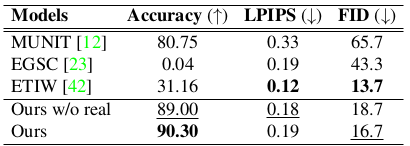 Quantitative performance of the proposed method
Quantitative performance of the proposed method
It can be seen that the proposed method outperforms baseline methods both qualitatively and quantitatively.
The proposed method is also robust to different text lengths
 Robustness to different text lengths
Robustness to different text lengths
Ablation study results demonstrate the importance of each parts applied for training the model.
 Ablation study results
Ablation study results
Related
- A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
- Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
- Image Synthesis and Editing with Stochastic Differential Equations
- Cascaded Diffusion Models for High Fidelity Image Generation
- Alias-Free Generative Adversarial Networks