Significance
Keypoints
- Combine MoCo and BYOL for self-supervised training of Swin Transformers
- Demonstrate comparable performance of MoBY trained Swin-T in a number of computer vision tasks
Review
Background
Self-supervised learning and the Transformer architecture are very close friends, considering the huge success of BERT in the representation learning of natural language. Transformers in the computer vision field have been gathering interest recently since the introduction of the Vision Transformer (ViT), and many efficient and powerful variants including DeiT and Swin Transformer are being proposed. This paper aims to experiment the capability of Swin Transformer with self-supervised training in the image classification, object detection, instance segmentation, and semantic segmentation tasks. More specifically, the authors combine two well-known self-supervised training framework, MoCo v2 and BYOL, and name the combined framework MoBY by taking the initial two letters from each methods (I personally think it would have been cooler to take the last two letters, naming it CoOL.). The tiny version of Swin Transformer (Swin-T) trained with MoBY demonstrates an encouraging result on downstream computer vision tasks.
Keypoints
Combine MoCo and BYOL for self-supervised training of Swin Transformers
The MoBY inherits the momentum design, the key queue, and the contrastive loss from MoCo v2, and inherits the asymmetric encoders, asymmetric data augmentations, and the momentum scheduler from BYOL.
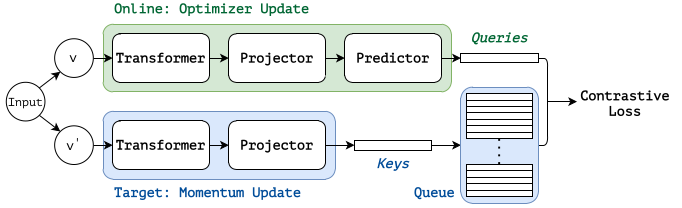 Scheme of the MoBY
The online encoder is has two projection heads, and is trained by the optimizer gradient update, while the target encoder is a moving average of the online encoder by momentum update. The contrastive loss $\mathcal{L}_{q}$ is defined between the queries from the online encoder and the queue of keys from the target encoder:
\begin{equation}
\mathcal{L}_{q} = -\log \frac{\exp(q \cdot k_{+}/\tau)}{\sum^{K}_{i=0}\exp(q\cdot k_{i}/\tau)},
\end{equation}
where $k_{+}$ is the target feature for the other view of the same image, $k_{i}$ is a target feature in the key queue, $\tau$ is a temperature hyperparameter, and $K$ is the size of the key queue.
The Swin-T is trained in a self-supervised way with MoBY and the performance on computer vision tasks are evaluated.
Scheme of the MoBY
The online encoder is has two projection heads, and is trained by the optimizer gradient update, while the target encoder is a moving average of the online encoder by momentum update. The contrastive loss $\mathcal{L}_{q}$ is defined between the queries from the online encoder and the queue of keys from the target encoder:
\begin{equation}
\mathcal{L}_{q} = -\log \frac{\exp(q \cdot k_{+}/\tau)}{\sum^{K}_{i=0}\exp(q\cdot k_{i}/\tau)},
\end{equation}
where $k_{+}$ is the target feature for the other view of the same image, $k_{i}$ is a target feature in the key queue, $\tau$ is a temperature hyperparameter, and $K$ is the size of the key queue.
The Swin-T is trained in a self-supervised way with MoBY and the performance on computer vision tasks are evaluated.
Demonstrate comparable performance of MoBY trained Swin-T in a number of computer vision tasks
The Swin-T trained with MoBY is compared with DeiT-S and other training schemes (Supervised, MoCo v3, DINO).
Linear mapping classification performance on ImageNet-1k to evaluate the learnt representation is first demonstrated.
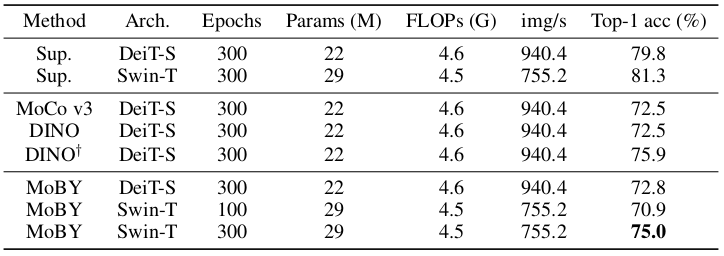 Comparative experiment of the MoBY trained Swin-T
The results suggest that MoBY achieves slightly better performance than MoCo v3 and DINO without multi-crop.
The authors also note that MoBY does not rely on heavy tricks, such as fixed patch embedding, batch norm before MLP, asymmetric/warmed-up temperature, fixing of last layer weights, etc.
Comparative experiment of the MoBY trained Swin-T
The results suggest that MoBY achieves slightly better performance than MoCo v3 and DINO without multi-crop.
The authors also note that MoBY does not rely on heavy tricks, such as fixed patch embedding, batch norm before MLP, asymmetric/warmed-up temperature, fixing of last layer weights, etc.
Transferring the learnt representation to downstream tasks are further experimented.
Downstream object detection and instance segmentation are tested with the COCO dataset.
The MoBY learnt representation are capable of performing similarly well on the object detection and instance segmentation tasks when compared to supervised training.
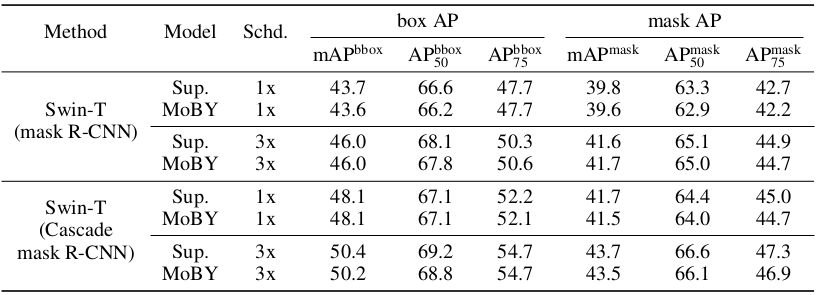 Object detection and instance segmentation results on COCO dataset
Semantic segmentation on the ADE20K dataset also indicate similar, but slightly worse performance of MoBY trained Swin-T when compared to supervised traning results.
Object detection and instance segmentation results on COCO dataset
Semantic segmentation on the ADE20K dataset also indicate similar, but slightly worse performance of MoBY trained Swin-T when compared to supervised traning results.
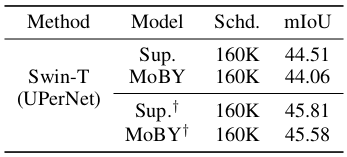 Semantic segmentation result on ADE20K dataset
Semantic segmentation result on ADE20K dataset
Ablation study results are referred to the original paper.