Significance
Keypoints
- Propose a method for video temporal grounding incorporating depth and optical flow information
- Demonstrate performance of the proposed method by experiments
Review
Background
Text-guided video temporal grounding refers to a task which aims to localize the segment of a video based on a given text query. Most previous methods consider only the RGB image frames from the video, which cannot efficiently capture action or complex scenes. This study tries to address this issue by additionally incorporating optical flow and depth information of the video.
Keypoints
Propose a method for video temporal grounding incorporating depth and optical flow information
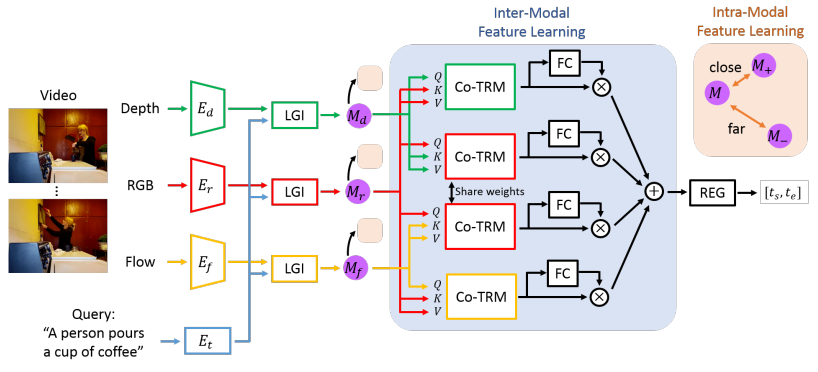 Schematic illustration of the proposed method
Schematic illustration of the proposed method
The idea is to first extract rgb, depth, and optical flow features with encoders $E_{r}$, $E_{d}$ and $E_{f}$. The local-global interaction modules (LGI) further incorporate the textual feature into each visual modality to derive multi-modal features $M_{r}$, $M_{d}$, and $M_{f}$. Interaction of these multi-modal features are modelled with co-attentional Transformer (Co-TRM) which the query and the key/value pairs are interleaved between the RGB feature and the other features. The final output $[t_{s}, t_{e}]$ are estimated by feeding each feature into a fully-connected (FC) layer, followed by a regression module (REG).
To further facilitate the multi-modal training, the authors add SimCLR based contrastive loss to the final objective where the positive and negative samples are defined as the actions from the same and different categories, respectively.
Demonstrate performance of the proposed method by experiments
The proposed method (DRFT) is compared with baseline methods including CTRL, RWM, MAN, TripNet, PfTML-GA, DRN, and LGI on the Charades-STA and ActivityNet Captions datasets.
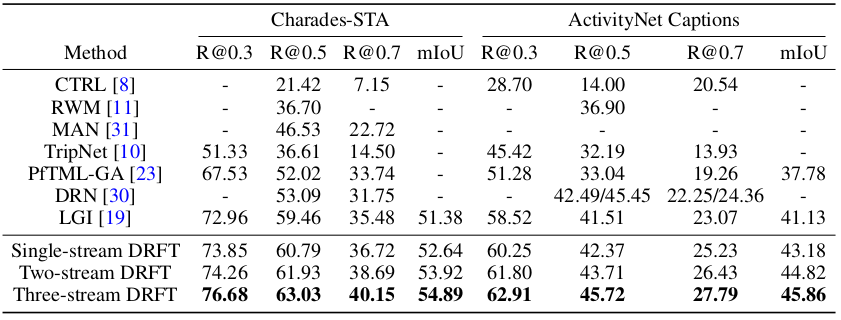 Comparative study of the proposed method
It can be seen that the performance of the proposed method outperforms baseline methods in terms of Recall at temporal Intersection over Union thresholds (R@IoU) and the mean temporal IoU.
Comparative study of the proposed method
It can be seen that the performance of the proposed method outperforms baseline methods in terms of Recall at temporal Intersection over Union thresholds (R@IoU) and the mean temporal IoU.
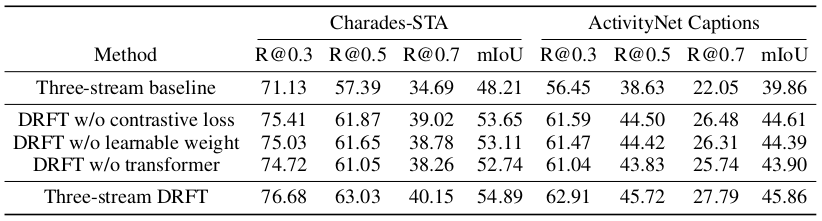 Ablation study results
From the ablation studies, it can be seen that the proposed method is especially degraded in performance when the transformer is not present.
Ablation study results
From the ablation studies, it can be seen that the proposed method is especially degraded in performance when the transformer is not present.
 Sample results from the Charades-STA dataset
Some sample results further demonstrate that fully incorporating the multi-modal video features can improve the performance when compared to single-stream RGB baseline video grounding model.
Sample results from the Charades-STA dataset
Some sample results further demonstrate that fully incorporating the multi-modal video features can improve the performance when compared to single-stream RGB baseline video grounding model.