Significance
Keypoints
- Propose a mask classification based semantic segmentation framework
- Demonstrate semantic segmentation performance of the proposed method
Review
Background
Semantic segmentation is a task that aims to partition an image into regions with different semantic categories.
Application of deep learning methods for semantic segmentation has largely improved the performance of the methods, and these models are usually trained by classifying each pixels into one of the $K$ semantic classes (dense prediction).
An alternative approach to the dense prediction is the mask classification, which is to generate a set of $N$ binary masks and classify each masks into one of the $K$ classes.
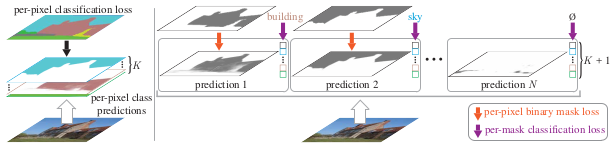 Per-pixel classification (left) and mask classification
While the mask classification approach is usually used for instance-level segmentation tasks, the authors show that it can also perform well on the semantic segmentation by proposing a new framework MaskFormer.
Per-pixel classification (left) and mask classification
While the mask classification approach is usually used for instance-level segmentation tasks, the authors show that it can also perform well on the semantic segmentation by proposing a new framework MaskFormer.
Keypoints
Propose a mask classification based semantic segmentation framework
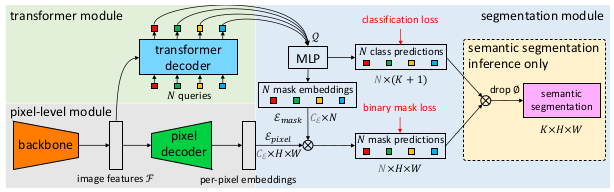 Schematic illustration of the proposed method
Schematic illustration of the proposed method
The proposed MaskFormer consists of pixel-level module, Transformer module, and segmentation module. The pixel-level module first takes an image to generate a low-resolution image feature map with a backbone model. This image feature map is upsampled with a pixel decoder model to generate per-pixel embeddings. Transformer module takes the image feature map from the pixel-level module, and computes $N$ per-segment embeddings. Finally, the segmentation module applies a linear classifier on top of the per-segment embeddings. The per-segment embeddings are used for both the mask predictions and the class predictions.
Demonstrate semantic segmentation performance of the proposed method
The performance of the proposed MaskFormer is compared with baseline models on the ADE2K, Cityscapes, and the COCO-Stuff datasets.
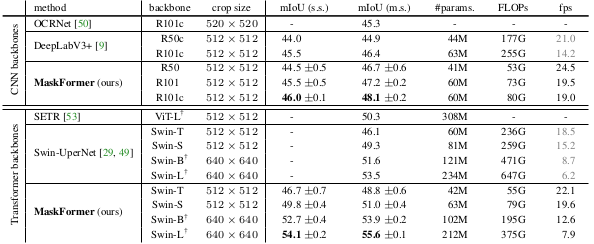 Comparative study on the ADE2K dataset
It can be seen that the proposed method outperforms other baseline methods with either CNN or Transformer backbones.
A notable finding is that the performance gain of the mask classification based method is more apparent when the number of classes is larger.
Comparative study on the ADE2K dataset
It can be seen that the proposed method outperforms other baseline methods with either CNN or Transformer backbones.
A notable finding is that the performance gain of the mask classification based method is more apparent when the number of classes is larger.
 Comparison of mask classification and per-pixel baselines on four datasets
Comparison of mask classification and per-pixel baselines on four datasets
Panoptic segmentation on COCO panoptic dataset also demonstrates excellent performance of the MaskFormer over baselines.
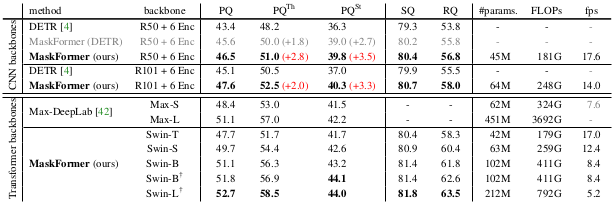 Panoptic segmentation results on COCO panoptic dataset
Panoptic segmentation results on COCO panoptic dataset
Further ablation study results are referred to the original paper