Significance
Keypoints
- Propose evaluating methods and datasets for code generation based on docstring
- Demonstrate performance of code generation with fine-tuned GPT model
Review
Background
Language models like BERT are capable of learning the representation of natural language. Extending this learned representation to programming languages have been studied in works like CodeBERT or PyMT5, but still is behind the performance for practical usage. GPT-3 is a large language model with hundreds of billions of parameters which is capable of generating realistic articles. This study aims to generate Python codes from a given docstring which is written in natural language with the GPT models. You can checkout the result of this paper from the GitHub copilot.
Keypoints
Propose evaluating metric and dataset for code generation based on docstring
Metric: pass@$k$
For evaluating the correctness of a generated function, pass@$k$ metric is to generate $k$ code samples and check whether any of the samples pass the unit test. The authors re-define the pass@$k$ metric as to generate $n \geq k$ samples per task and count the number of correct samples $c$ which pass unit tests to calculate: \begin{align} \text{pass@}k:= \mathcal{E}[ 1-\frac{\binom{n-c}{k}}{\binom{n}{k}} ]. \end{align}
Dataset: HumanEval
For training the model, a new dataset HumanEval is released to public by the authors. The HumanEval dataset includes function signature, docstring, body, and several unit tests.
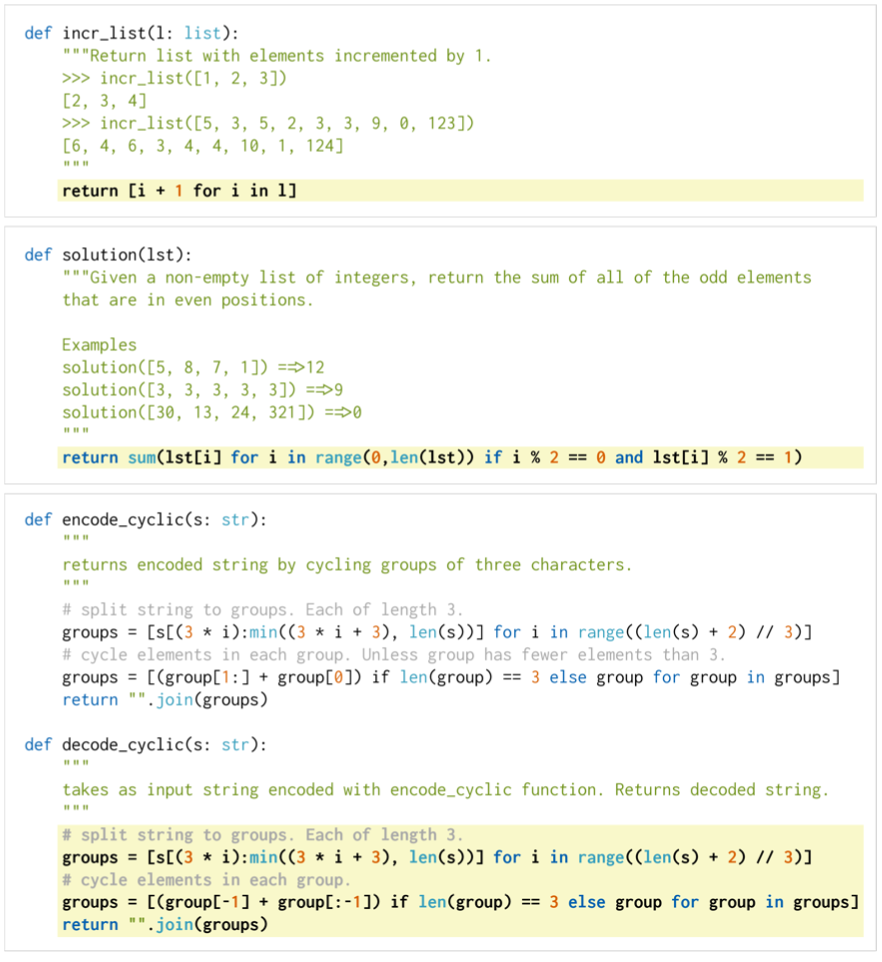 Example problems from the HumanEval dataset
Example problems from the HumanEval dataset
Demonstrate performance of code generation with fine-tuned GPT model
GPT models with up to 12 billion parameters are fine-tuned on a dataset collected from 54 million GitHub public repositories. The fine-tuned GPT model is named Codex, and is evaluated on HumanEval dataset with pass@$k$.
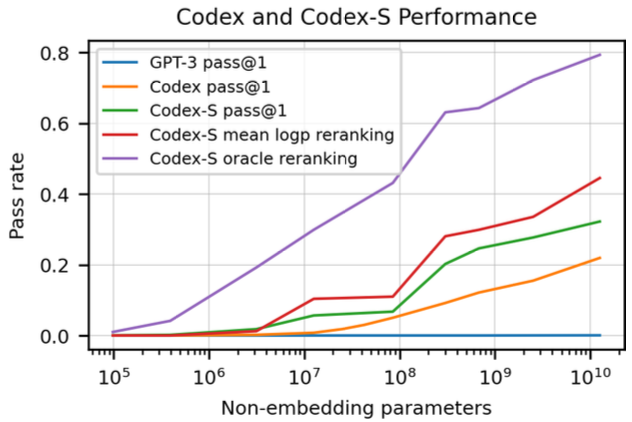 Pass@$k$ of the proposed method with respect to number of parameters
Pass@$k$ of the proposed method with respect to number of parameters
It can be seen that the proposed Codex and Codex-S outperforms GPT-3 in the pass rates. Here, Codex-S is a Codex model with further supervised fine-tuning on selected distribution of code samples, reducing the negative effect of docstring unrelated code blocks like configurations or data storing functions.
Code generation performance increases with the number of parameters in the Codex model.
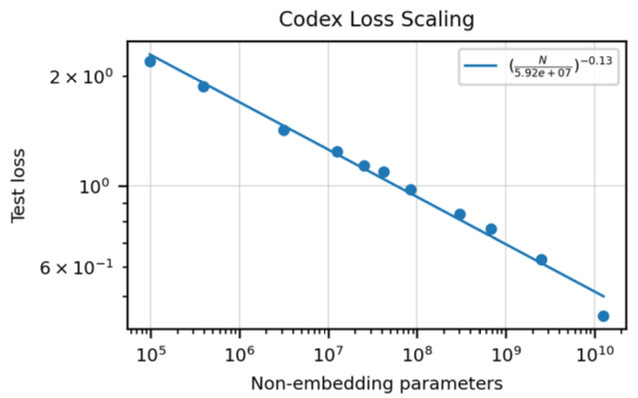 Test loss with respect to number of parameters
Test loss with respect to number of parameters
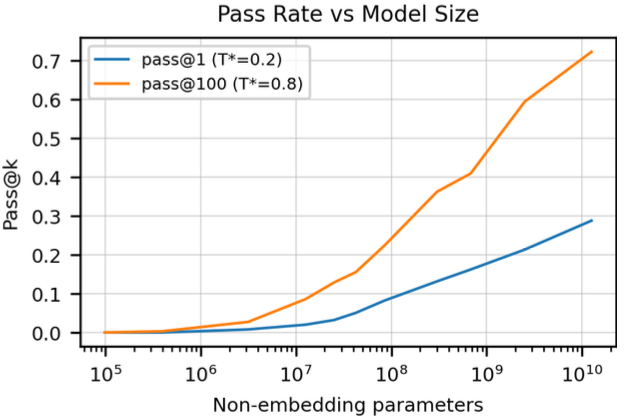 Pass@$k$ with respect to number of parameters
Pass@$k$ with respect to number of parameters
Also, higher accuracy can be achieved by generating larger number of samples and selecting the best sample based on the log probability of the generated samples.
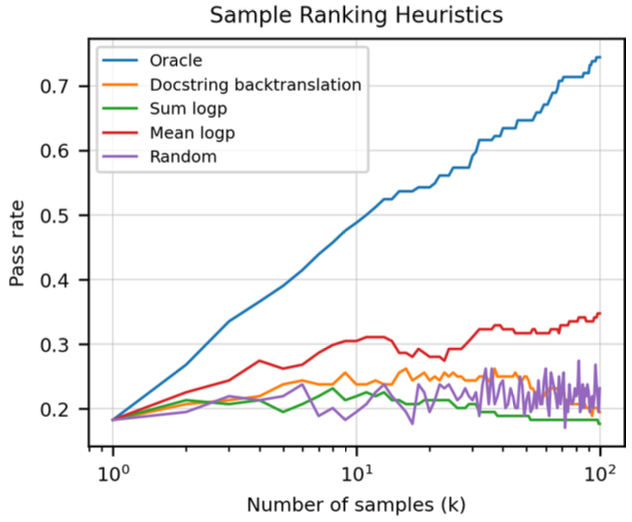 Pass rate with respect to number of generated samples and selection scheme
It can be seen that the logp (red line) performs better than selecting a random generated sample (purple line).
Codex-S exhibits similar behavior regarding the model size and the number of generated samples.
Pass rate with respect to number of generated samples and selection scheme
It can be seen that the logp (red line) performs better than selecting a random generated sample (purple line).
Codex-S exhibits similar behavior regarding the model size and the number of generated samples.
Comparing the proposed Codex to similar GPT based methods, the GPT-Neo and the GPT-J, it can be seen that the proposed method significantly outperforms previous methods when the number of parameters are similar.
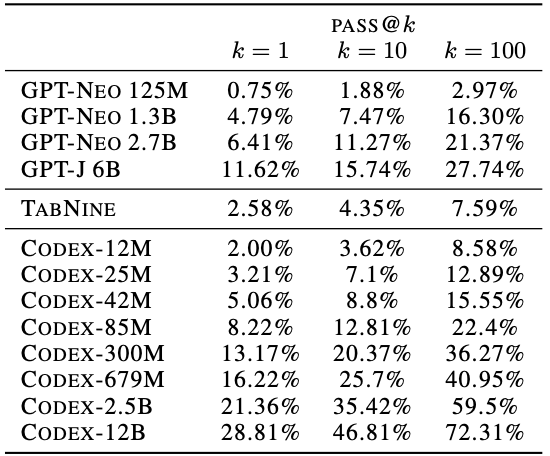 Comparison of Codex with GPT-Neo and GPT-J
Comparison of Codex with GPT-Neo and GPT-J
Further detailed discussion on the results, limitations, and societal impacts are referred to the original paper.