Significance
Keypoints
- Propose a framework for merging different pre-trained GANs
- Demonstrate quantitative and qualitative image generation/editing performance of the proposed method
Review
Background
Although Generative Adversarial Networks (GANs) have been successful in generating high quality images, many of them specialize on generating a image from specific domain, such as human faces, bedrooms, or landscapes. This paper focuses on a task called model merging, where two or more generative models are merged into a single conditional model. Model merging without access to the training dataset can bring benefits including decentralized workflows, reducing computational resource requirements, and semantic editing across domains (if the latent space is properly shared after merging). Given a set of $N$ pre-trained GANs $\{GAN_{i} = (G_{i},D_{i}) \}^{N}_{i=1}$, where $G$ is the generator and $D$ is the discriminator, The goal of model merging is to train a new conditional GAN which the condition of the generation should come from the $N$ domains. The authors set three baseline methods for model merging: (i) Training from scratch, (ii) TransferGAN, and (iii) Elastic weight consolidation (EWC).
Training from scratch refers to training a new GAN with the generated images from the pre-trained GANs $\{GAN_{i} = (G_{i},D_{i}) \}^{N}_{i=1}$. TransferGAN is to initialize the new GAN from the $i$-th pre-trained GAN and train the model with the images from the pre-trained GAN except the $i$-th one. EWC mitigates the issue from the TransferGAN that the $i$-th domain quality degrades over training due to catastrophic forgetting. Upon these three baseline ideas, the authors propose GAN Cocktail, which merges GANs by two-step process of model-rooting and model-merging.
Keypoints
Propose a framework for merging different pre-trained GANs
The GAN Cocktail aims to merge pre-trained GANs by averaging the model weights.
However, a naive averaging across different GANs trained with different dataset result in generating images which have no apparent semantic structures.
The authors hypothesize that this limitation comes from the fact that the models do not share common ancestor models, and propose to perform model rooting before merging.
Specifically, one of the pre-trained models is chosen to be a root model $GAN_{r}$, while outputs from other models $i \in [N] \setminus r$ are used for training the model.
The rooted model $i$ is denoted as $GAN_{r\rightarrow i}$, and averaging across the $i$-th models can now lead to semantically meaningful results.
 Averaging across non-rooted (left) and rooted (right) GAN models
Distance between the weights of the rooted models was also closer than the weights of the non-rooted models.
Averaging across non-rooted (left) and rooted (right) GAN models
Distance between the weights of the rooted models was also closer than the weights of the non-rooted models.
Demonstrate quantitative and qualitative image generation/editing performance of the proposed method
For quantitative evaluation of the proposed method, FID score computed against the original training dataset is compared with the baseline methods.
The FID score of the proposed method was lowest (best) for the model merge across GANs trained with different datasets.
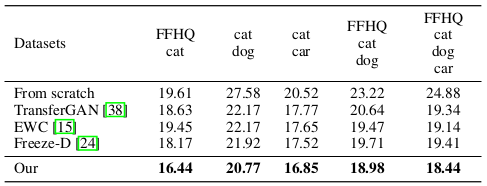 FID score comparison with respect to the union of several dataset combinations
Evaluation of the FID score on each class showed that EWC achieved better results on some cases where the classes were semantically distant (e.g. car - cat).
However, the proposed method showed quantitative strength over baseline methods in many cases.
FID score comparison with respect to the union of several dataset combinations
Evaluation of the FID score on each class showed that EWC achieved better results on some cases where the classes were semantically distant (e.g. car - cat).
However, the proposed method showed quantitative strength over baseline methods in many cases.
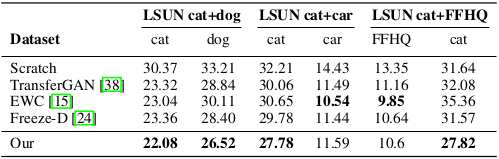 FID score comparison with in separate classes
FID score comparison with in separate classes
The merged model can be applied to other tasks given that the disentangled latent space is appropriately shared between the merged models, such as style mixing and semantic editing.
 Style mixing results
Style mixing results
 Semantic editing results
Semantic editing results