Significance
Keypoints
- Propose StyleGAN latent encoder incorporating spatial dimension information
- Show capability of the proposed method in real-time and local image editing
Review
Background
Note: Background of the StyleGAN latent space manipulation methods have been overviewed in my previous posts reviewing the StyleCLIP paper and the SurrogateGradientField paper.
It has been discussed in my previous posts that semantic image editing using the disentangled latent space of the StyleGAN/StyleGAN2 models is being studied. However, a practical limitation of the methods is that most methods require minutes of optimization process before semantic image manipulation to project an image to the latent space. Training an encoder which can correctly project an image to the latent space can solve this problem, but trained encoders usually fail to find the latent space that can recover fine details of the original image. This paper points out that the problem of losing detail comes from the structure of the encoder, which do not consider the spatial dimension of the latents.
Keypoints
Propose StyleGAN latent encoder incorporating spatial dimension information
To preserve spatial dimension from the encoded latent, the authors simply propose to reshape the latent $\mathbf{w}$ in the style space $\mathcal{W}$ to match the shape of the features of the StyleGAN synthesis network.
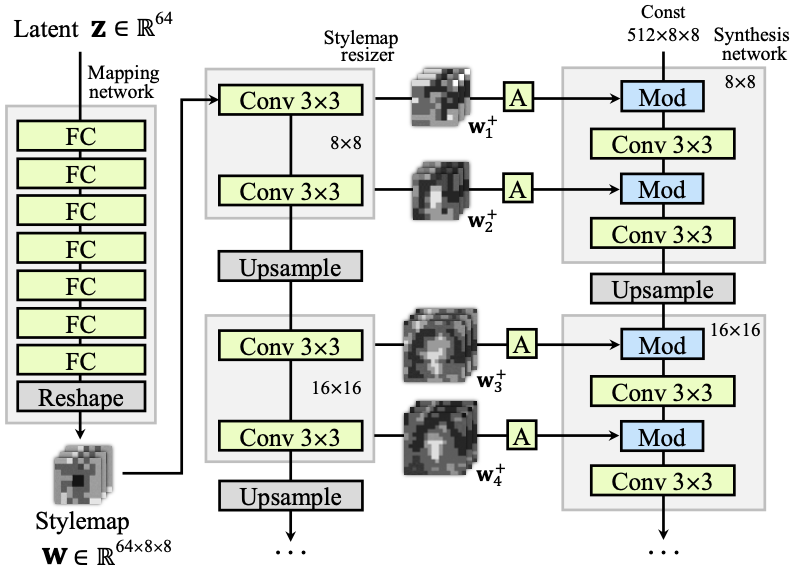 Latent $\mathbf{w}$ is reshaped and upscaled to match the spatial dimension
From the figure, it can be seen that the output of the mapping network is reshaped to map the latent $\mathbf{w}\in \mathbb{R}^{64\times 8 \times 8}$, where $8\times 8$ is the spatial dimension which is not present in other methods.
The spatial dimension of $\mathbf{w}$ is upscaled along the spatial dimension of the features from the synthesis network by convolution and upsampling layers.
Note that the original mapping network of StyleGAN outputs vectorized latent per features of the synthesis network which modulates style of the generated image via AdaIN.
The latent with spatial dimension, which authors coin the term stylemap, does not modulate the features of the synthesis network by AdaIN, but by elementwise multiplication and addition of the stylemap after learned affine transformation (A from the above figure).
Latent $\mathbf{w}$ is reshaped and upscaled to match the spatial dimension
From the figure, it can be seen that the output of the mapping network is reshaped to map the latent $\mathbf{w}\in \mathbb{R}^{64\times 8 \times 8}$, where $8\times 8$ is the spatial dimension which is not present in other methods.
The spatial dimension of $\mathbf{w}$ is upscaled along the spatial dimension of the features from the synthesis network by convolution and upsampling layers.
Note that the original mapping network of StyleGAN outputs vectorized latent per features of the synthesis network which modulates style of the generated image via AdaIN.
The latent with spatial dimension, which authors coin the term stylemap, does not modulate the features of the synthesis network by AdaIN, but by elementwise multiplication and addition of the stylemap after learned affine transformation (A from the above figure).
The basic idea is introduced, but not anything about the encoder yet.
Structure of the encoder $E$ is similar to the StyleGAN discriminator, and is trained in a cyclic way.
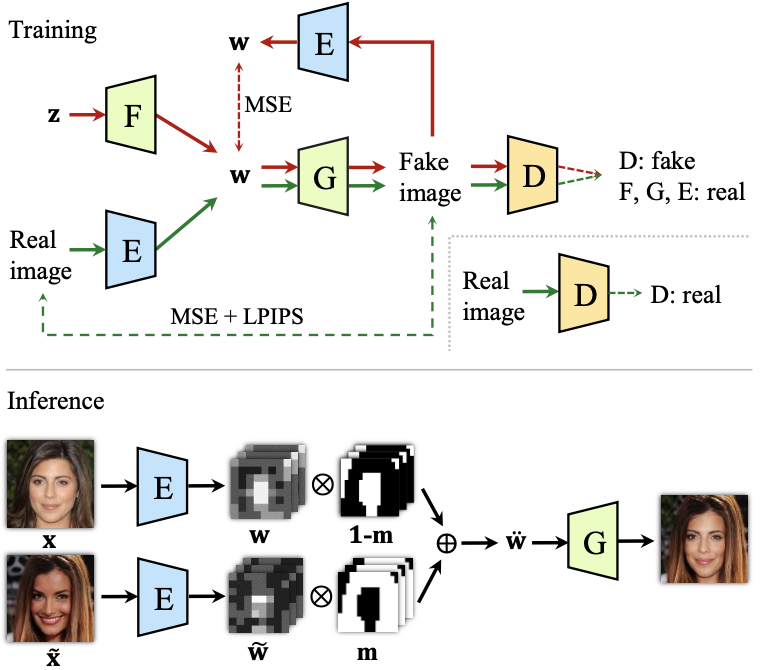 Training and inference of the proposed method
Here, the cyclic way means a training scheme similar to that of the CycleGAN, since given a real image $\mathbf{x}$ and its corresponding stylemap latent $\mathbf{w}$, the distance $||\mathbf{x} - G(E(\mathbf{x})) ||_{2, \text{LPIPS}}$ and $||\mathbf{w} - E(G(\mathbf{w}))||_{2}$ are minimized.
Other than the cyclic training of $E$, the training scheme follows that of the original StyleGAN.
Training and inference of the proposed method
Here, the cyclic way means a training scheme similar to that of the CycleGAN, since given a real image $\mathbf{x}$ and its corresponding stylemap latent $\mathbf{w}$, the distance $||\mathbf{x} - G(E(\mathbf{x})) ||_{2, \text{LPIPS}}$ and $||\mathbf{w} - E(G(\mathbf{w}))||_{2}$ are minimized.
Other than the cyclic training of $E$, the training scheme follows that of the original StyleGAN.
During inference, the proposed method is able to output images which are locally edited with respect to a reference image. Given stylemaps from the original image and the reference image $\mathbf{w}$ and $\tilde{\mathbf{w}}$, locally edited stylemap $\ddot{\mathbf{w}}$ is a linear interpolation between the two given a mask $\mathbf{m}$ indicating the location to be edited: \begin{equation} \ddot{\mathbf{w}} = \mathbf{m} \bigotimes \tilde{\mathbf{w}} \bigoplus (1-\mathbf{m}) \bigotimes \mathbf{w}. \end{equation} Now, semantic editing without optimization (real-time!) is possible, and local editing is a free gift from the model.
Show capability of the proposed method in real-time and local image editing
The authors first provide a self-comparison experiment to show that the spatial dimension is essential for training an accurate latent encoder.
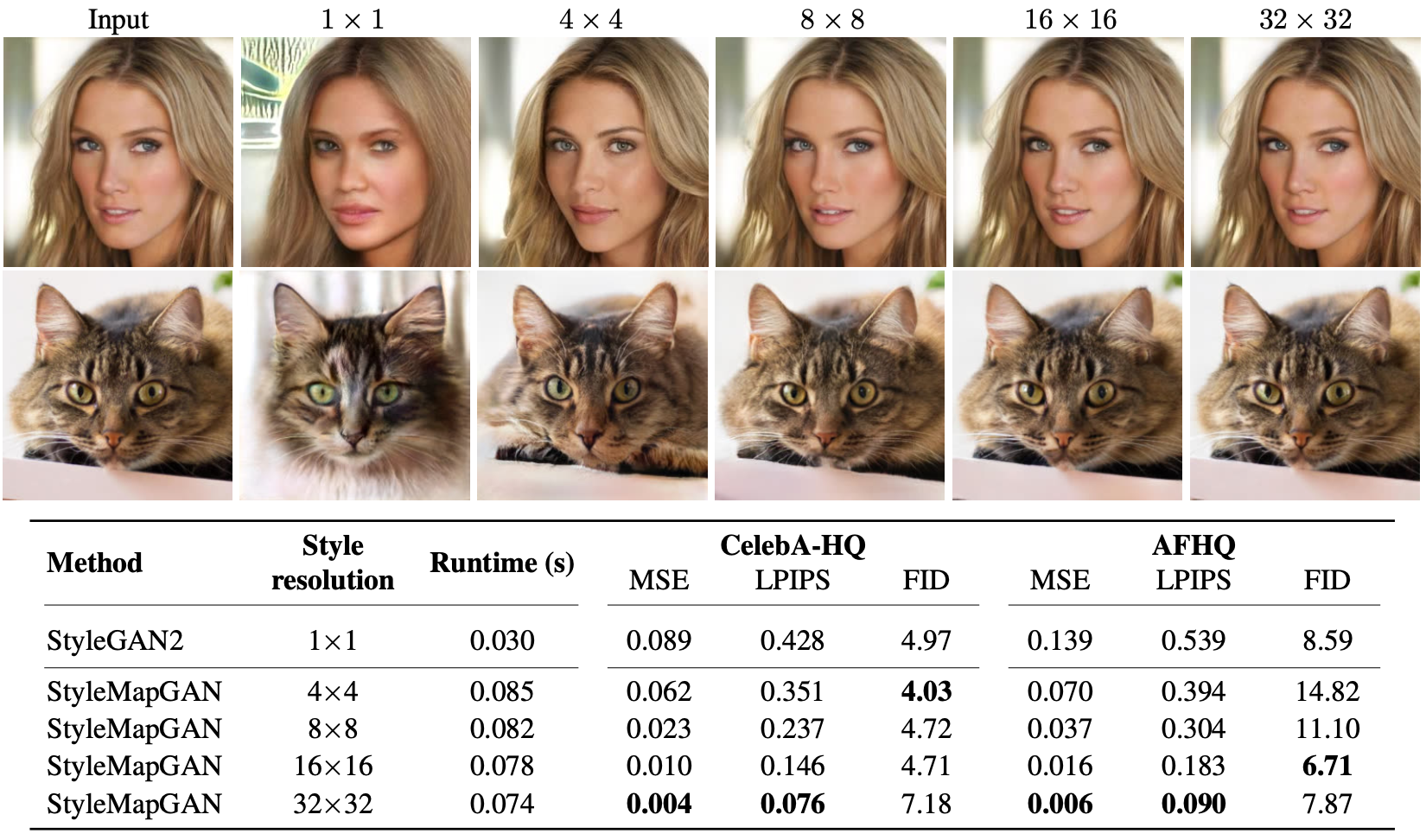 Spatial dimension is related to accurate encoding of the latent
It can be seen that the MSE loss and the reconstructed image is degraded as the spatial dimension is reduced.
Spatial dimension is related to accurate encoding of the latent
It can be seen that the MSE loss and the reconstructed image is degraded as the spatial dimension is reduced.
 Spatial dimension is related to local editing result
The local editing is also affected by the spatial dimension.
The spatial dimension of appropriate resolution (8$\times$8 in the above example) results in the edited images with best naturalness.
Spatial dimension is related to local editing result
The local editing is also affected by the spatial dimension.
The spatial dimension of appropriate resolution (8$\times$8 in the above example) results in the edited images with best naturalness.
Most importantly, the authors compare runtime and reconstruction quality of the proposed method to other baseline methods including Image2StyleGAN, Structured Noise, In-DomainGAN, and SEAN.
 Near real-time reconstruction with high accuracy is achieved by the proposed method
Local editing is also neatly done with the proposed StyleMapGAN while most other baseline methods fail to output realistic images.
Near real-time reconstruction with high accuracy is achieved by the proposed method
Local editing is also neatly done with the proposed StyleMapGAN while most other baseline methods fail to output realistic images.
 Local editing with StyleMapGAN compared to baselines
Lastly, the capability of unaligned transplantation is shown with the StyleMapGAN.
Local editing with StyleMapGAN compared to baselines
Lastly, the capability of unaligned transplantation is shown with the StyleMapGAN.
Further experimental results are referred to the original paper. I personally enjoyed reading this paper very much, because I have always been curious why my attempts on training a StyleGAN encoder fails, even with very similar cycle-loss training. This paper has given me some insight that the shape (which preserves spatial dimensions) of the latent was one of the key to the problem.