Significance
Keypoints
- Extend self-supervised methods for image data to videos
- Demonstrate performance of the extended methods
Review
Background
Self-supervised learning methods not only made breakthrough in the field of natural language processing, but also in computer vision. For example, SimCLR, MoCo, BYOL, and SwAV are some of the self-supervised, contrastive methods for learning representation from unlabelled set of image data. This work extends these four methods to learn representation of video data, which requires learning of spatiotemporal features.
Keypoints
Extend self-supervised methods for image data to videos
The key idea is very simple.
To deal with the time dimension which was not present in the image data, clips from the video are considered positive samples while clips from another video are considered negative ones (if the method requires negative samples).
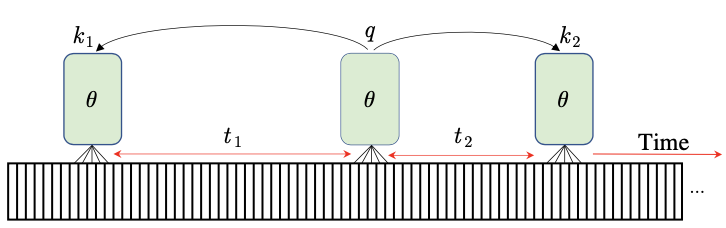 Positive samples are from another clip within the same video
The $\theta$ refers to parameter of the model $f_{\theata}$ that can extract features from a video, such as ResNet-50 or Slow pathway of SlowFast.
Given the anchor feature $q=f_{\theta}$ and positive/negative sample features $k+$/$k-$, the four self-supervised learning methods are trained to minimize the loss $\mathcal{L}_{q}$:
Positive samples are from another clip within the same video
The $\theta$ refers to parameter of the model $f_{\theata}$ that can extract features from a video, such as ResNet-50 or Slow pathway of SlowFast.
Given the anchor feature $q=f_{\theta}$ and positive/negative sample features $k+$/$k-$, the four self-supervised learning methods are trained to minimize the loss $\mathcal{L}_{q}$:
SimCLR/MoCo
\begin{equation} \mathcal{L}_{q} = -\log \frac{\sum_{k\in{k^{+} } } \exp(s(q,k)/\alpha)}{\sum_{k\in{k^{+},k^{-} } } \exp(s(q,k)/\alpha)}, \end{equation}
BYOL
\begin{equation} \mathcal{L}_{q} = - \sum _{k\in{ k^{+} }} s(q,k), \end{equation}
SwAV
\begin{equation} \mathcal{L}_{q} = D_{\text{KL}}(\tilde{q}||SK(\tilde{k}^{+})), \end{equation}
where $s$ is the cosine similarity, $\alpha$ is the temperature hyperparameter, $SK$ is the Sinkhorn-Knopp step, $\tilde{q}$ and $\tilde{k}^{+}$ are linearly mapped output of the anchor and positive features.
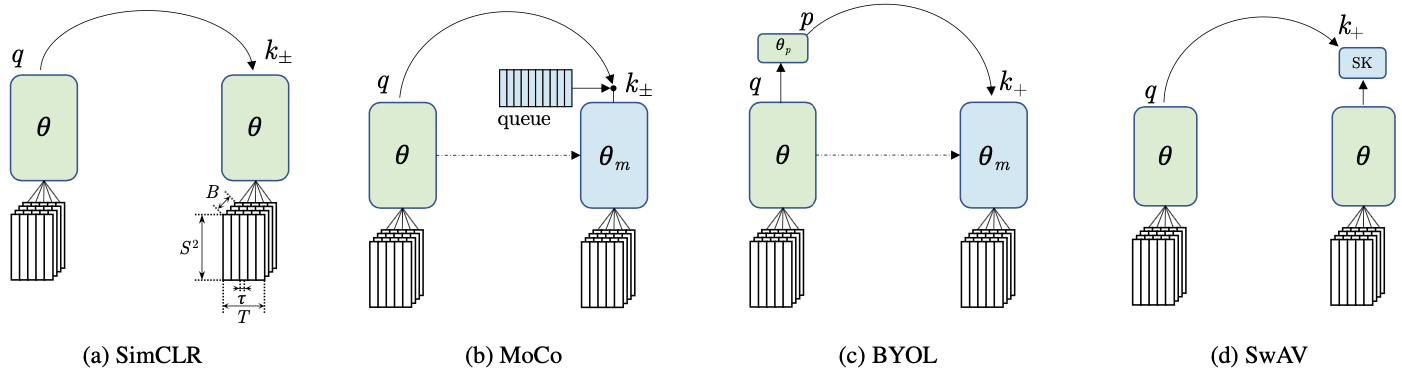 Four self-supervised methods for video representation learning
The method is very simple, but the experiment results demonstrate a remarkable performance gain.
Four self-supervised methods for video representation learning
The method is very simple, but the experiment results demonstrate a remarkable performance gain.
Demonstrate performance of the extended methods
Training of the model was done over Kinetics-400 (K400) and Instagram videos dataset (IG-Curated, IG-Uncrated, IG-Uncurated-Short).
Performance was evaluated by video classification accuracy, where pre-training of the model was done with K400 and a linear classifier on top of the frozen model was trained afterwards.
Finetuning was performed for a separate UCF101 dataset.
The results show performance improvement with respect to the number of temporal clips $\rho$, where $\rho=1$ correspond to no temporal domain self-supervision was done.
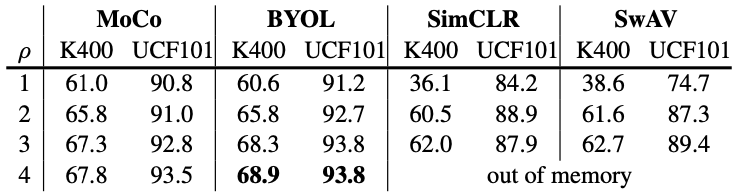 Performance gain with respect to the number of temporal clips
It can be inferred from the table that (i) no difference in performance is present between contrastive (SimCLR, MoCo) vs. non-contrastive (BYOL, SwAV) methods and (ii) momentum encoder (MoCo, BYOL) improves performance.
Performance gain with respect to the number of temporal clips
It can be inferred from the table that (i) no difference in performance is present between contrastive (SimCLR, MoCo) vs. non-contrastive (BYOL, SwAV) methods and (ii) momentum encoder (MoCo, BYOL) improves performance.
Self-comparison result of the backbone feature extraction model $f_{\theta}$ with varying input duration $T$ and sampling-rate $\tau$ is as follows.
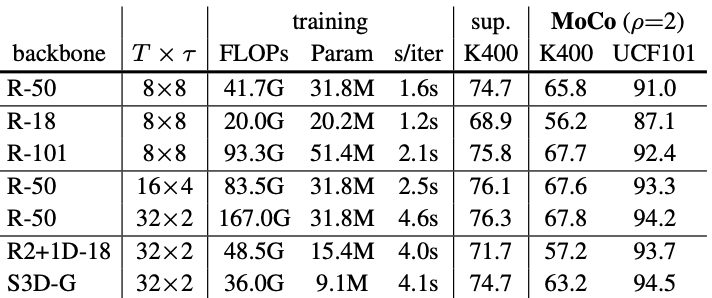 Self-comparison result
From the results, it can be seen that shallower ResNets (R-18) perform worse than deeper ones (R-101).
Increasing the duration $T$ and the temporal resolution $1/\tau$ also improved performance, especially for the UCF101 dataset.
Self-comparison result
From the results, it can be seen that shallower ResNets (R-18) perform worse than deeper ones (R-101).
Increasing the duration $T$ and the temporal resolution $1/\tau$ also improved performance, especially for the UCF101 dataset.
Data augmentation was experimented on temporal (T), spatial (S), and color (C) dimensions, corresponding to temporal clipping, spatial cropping, and radiometric color augmentations, respectively.
Results suggest that the combination of all three augmentations can add benefit to the model performance.
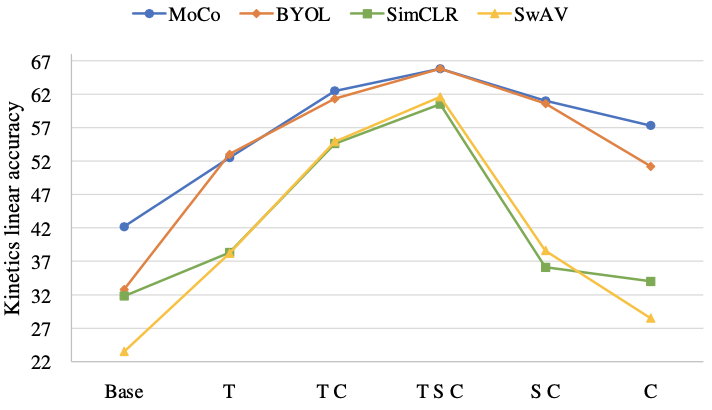 Data augmentation experiment results
Data augmentation experiment results
Lastly, the best performing model $\rho$BYOL is compared with other state-of-the-art methods for video classification.
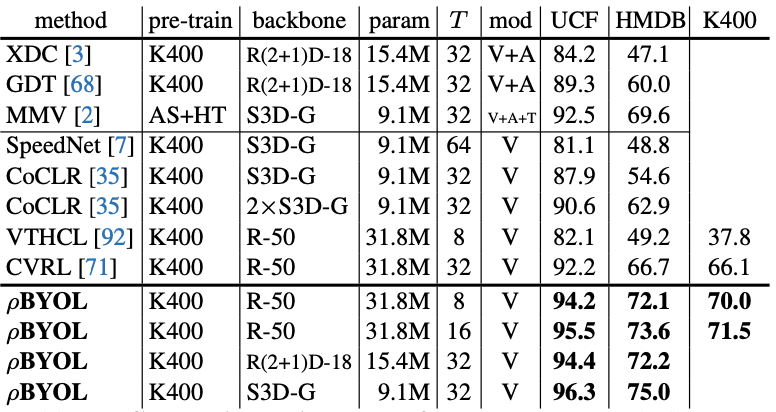 The experiment results show that $\rho$BYOL outperforms other methods in UCF101, HMDB, and K400 datasets.
The experiment results show that $\rho$BYOL outperforms other methods in UCF101, HMDB, and K400 datasets.
Experimental results on uncurated dataset and other downstream tasks are referred to the original paper