Significance
Keypoints
- Propose a natural language based video summarization framework
- Demonstrate performance of the proposed method in video summarization
Review
Background
Video summarization refers to generating a summary clip of a full video including important scenes. Generic video summarization is to make a general video summary clip, while query-focused video summarization is to make a video summary based on user’s given query. Recent improvements in multi-modal (text-image) learning has shown interesting applications that links text queries to navigate the image domain representations (for example, semantic image editing with text query) This work exploits one of these multi-modal models, CLIP, to improve both generic and query-focused video summarization.
Keypoints
Propose a natural language based video summarization framework
The proposed method is basically a query-focused video summarization framework with attention.
For generic video summarization, a pre-trained caption generator creates dense video caption for being input to the model instead of a query.
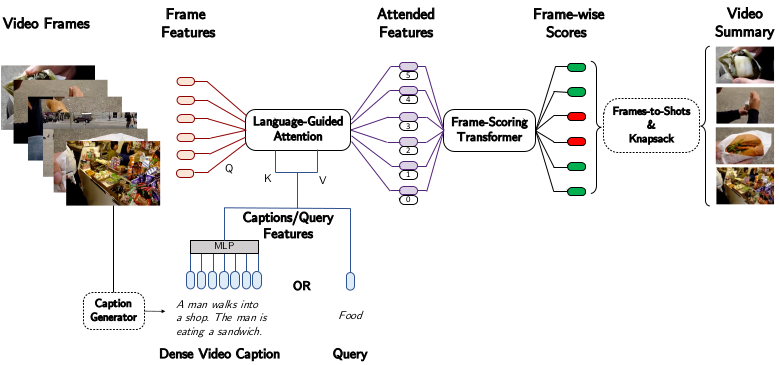 Scheme of the proposed method
Scheme of the proposed method
The language-guided attention attends between query (text) and video frame (image) features, extracted by the CLIP. Attention between the two type of features is realized by the Transformer, where image features serve as the query (Q) and the text features serve as the key (K) and the value (V). After the language-guided attention derive blended feature from the two input sources, importance of each frame is predicted by another Transformer named frame-scoring Transformer.
The proposed framework CLIP-It is trained by weighted sum of three loss functions (classification, diversity, and reconstruction). Classification loss is the weighted binary cross entropy loss for classifying each frame. Reconstruction loss is the MSE loss between the reconstructed and the input frame-level features, where the reconstruction by applying 1$\times$1 convolution to the Transformer output. Diversity loss is a repelling regularizer as the pairwise cosine similarity between the reconstructed feature vectors. CLIP-It can also be trained in an unsupervised fashion by only including the diversity and reconstruction loss for training.
Demonstrate performance of the proposed method in video summarization
Performance of the proposed method in generic video summarization is evaluated by comparing F1 scores with baseline models on the SumMe and TVSum datasets with three settings.
Train-test splits are from the same dataset for the standard setting, training is augmented with data from other datasets in the augment setting.
Transfer setting is the most challenging, which is to test on a separate held-out dataset.
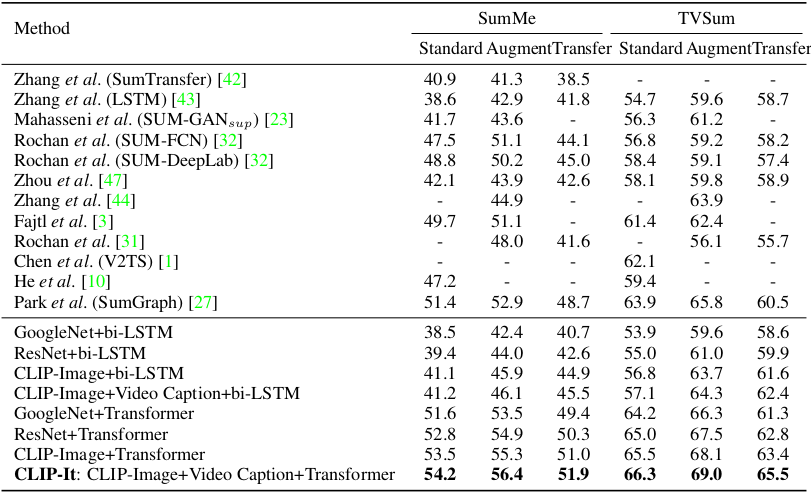 Generic video summarization F1 scores with supervised learning
Generic video summarization F1 scores with supervised learning
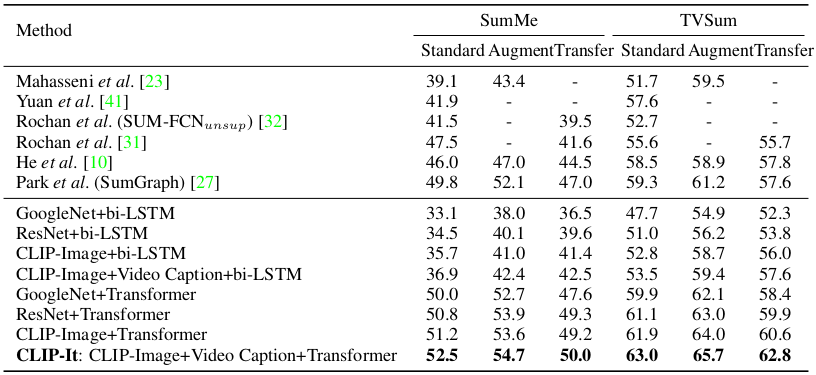 Generic video summarization F1 scores with unsupervised learning
It can be seen that the proposed CLIP-It outperforms other baseline methods on both supervised and unsupervised learning scheme in various settings.
Generic video summarization F1 scores with unsupervised learning
It can be seen that the proposed CLIP-It outperforms other baseline methods on both supervised and unsupervised learning scheme in various settings.
Query-focused video summarization is tested on the QFVS dataset.
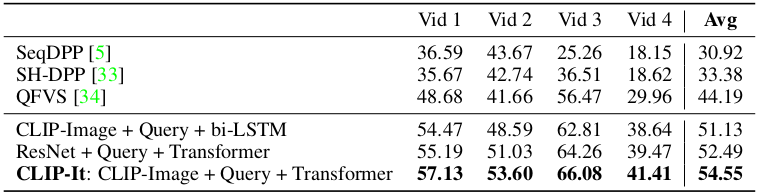 Quantitative result of the proposed method for query-based video summarization on QFVS dataset
It can be seen that the proposed method performs query-focused video summarization better than baseline methods quantitatively.
Quantitative result of the proposed method for query-based video summarization on QFVS dataset
It can be seen that the proposed method performs query-focused video summarization better than baseline methods quantitatively.
 Qualitative result of the proposed method for query-based video summarization on QFVS dataset
Qualitative result also suggests the plausibility of the proposed method for query-focused video summarization.
Qualitative result of the proposed method for query-based video summarization on QFVS dataset
Qualitative result also suggests the plausibility of the proposed method for query-focused video summarization.