Significance
Keypoints
- Propose three methods that bridge the gap between the latent space of StyleGAN and CLIP to realize text-driven image manipulation
- The proposed methods are compared with each other and other baseline methods
Review
Background
StyleGAN is a generative model that is capable of generating high quality (1024$\times$1024) images by AdaIN based style adaptation of a ProGAN.
A github repository was one of the first to investigate the high-level disentanglement of the StyleGAN latent space, which is injected to each level of the generator via AdaIN.
This interesting finding was elaborated by works such as Image2StyleGAN, InterFaceGAN, StyleFlow, confirming its potential to be applied to semantic image editing.
Along with this trend, recent introduction of powerful multimodal (or more specificaly, text-image) learning methods like DALL-E, CLIP suggest a possible semantic image editing based on natural language guidance.
The key point to achieve this is to find and map common image- and text- manipulation to a common direction between the StyleGAN latent space and the text-image model latent space.
This work proposes three ways to bridge the gap between the StyleGAN latent space direction and the CLIP latent space direction.
 Your cat is now cute!
Your cat is now cute!
Keypoints
Propose three methods that bridge the gap between the latent space of StyleGAN and CLIP to realize text-driven image manipulation
Method 1: Latent Optimization
This approach follows primitive methods of StyleGAN encoding which finds the embedding of an image by optimization in the latent space.
One difference is that the methods incorporates the cosine distance between the CLIP embeddings the text prompt $t$ and the generator $G$ output of the latent vector $w$ into its loss function for the optimization:
\begin{equation}
\underset{w \in \mathcal{W}+}{\arg\min}D_{\text{CLIP}}(G(w),t) + \lambda_{L2} ||w-w_{s}||_{2} + \lambda_{\text{ID}}\mathcal{L}_{\text{ID}}(w).
\end{equation}
The ID loss $\mathcal{L}_{\text{ID}}(w)$ is a cosine similarity between the source latent vector $w_{s}$ and the latent code being optimized $w$ which is input to the pre-trained ArcFace network $R$:
\begin{equation}
\mathcal{L}_{\text{ID}}(w) = 1 - \langle R(G(w_{s})), R(G(w)) \rangle,
\end{equation}
where $G$ is a pre-trained StyleGAN generator.
The ArcFace network is trained for face recognition, which means that keeping the cosine similarity can preserve identity of the face being edited.
(ArcFace is also well-known for its loss function, suited for metric learning to solve tasks like text-image retrieval.)
The latent optimization method is easy to implement and the process is straightforward, but takes long optimization time (over a few minutes per image).
 Examples of Latent Optimization output
Examples of Latent Optimization output
Method 2: Latent Mapper
The authors propose another method, Latent Mapper, which involves training of a fully-connected neural network that can shift the latent code to gain a certain attribute based on the text prompt $t$.
The Latent Mapper $M_{t}$ for text prompt $t$ is trained to minimize the CLIP loss
\begin{equation}
\mathcal{L}_{\text{CLIP}}(w) = D_{\text{CLIP}}(G(w+M_{t}(w)), t),
\end{equation}
where G is again a pre-trained StyleGAN generator.
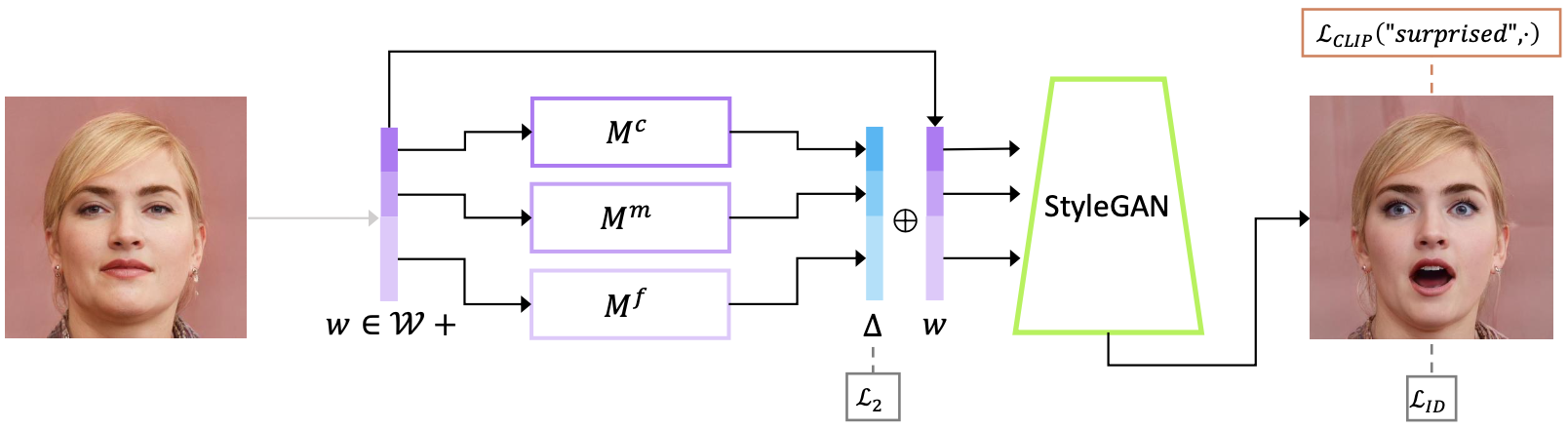 Latent Mapper method ($M = (M^{c}, M^{m}, M^{f}))
Latent Mapper method ($M = (M^{c}, M^{m}, M^{f}))
The final loss function is a weighted sum of the CLIP loss, ID loss with an L2 regularization of the network $M_{t}$.
Reviewing the definition of the Latent Mapper $M_{t}$ and the mathematics behind its training, the Latent Mapper does not take text prompt $t$ at test time but is trained with a specified text prompt (meaning that you need to train one neural network for one text prompt).
However, the authors mention that the text prompts are not limited to a single attribute at a time, which I have not yet understood.
 Examples of Latent Mapper output
Examples of Latent Mapper output
Method 3: Global Directions
The last method is based on the idea that the image $G(s)$ (or its latent embedding $i$) generated from a style space code $s$, and its manipulated image $G(s+\alpha \Delta s)$ (or its latent embedding $i+\Delta i$) should correspond to a certain difference in the text prompt latent code encoded with a CLIP encoder $\Delta t$.
To bridge this gap between the two latent space, the difference between the neutral and the with-attribute text in the latent space $\Delta t$ is obtained first by prompt engineering.
Now, the goal is to find a the style space manipulation $\Delta s$ that would yield a change $\Delta i$ correlated with the direction $\Delta t$.
To find the relationship between the $\Delta s$ and the $Delta i$, the authors propose to perturb a specific channel $c$ of each style code by a certain value, and define the relevance (relationship) as the mean projection of $\Delta i_{c}$ onto $\Delta i$:
\begin{equation}
R_{c} (\Delta i) = \mathbb{E}_{s\in \mathcal{S}} \{ \Delta i_{c}\cdot \Delta i \}.
\end{equation}
After the relevance is calculated for each channel, the channels with relevance below a threshold hyperparameter $\beta$ is set to zero,
\begin{equation}
\Delta s = \begin{cases} \Delta i_{c} \cdot \Delta i, & \text{if}\ |\Delta i_{c} \cdot \Delta i| \\ 0, & otherwise \end{cases}
\end{equation}
deriving style space code direction $\Delta s$ from the CLIP image latent space direction $\Delta i$.
One assumption here is that the latent space directions of the text prompt $\Delta t$ and the image $\Delta i$ are roughly collinear in well-trained areas of the CLIP space.
 Examples of Global Direction output
Examples of Global Direction output
The proposed methods are compared with each other and other baseline methods
The Latent Mapper, and the Global Direction methods are compared with TediGAN.
 Comparison of the Latent Mapper, Global Direction and the TediGAN
The authors conclude that the Latent Mapper is suitable for complex attributes, while the Global Direction suffices for simpler and/or a more common attributes.
Comparison of the Latent Mapper, Global Direction and the TediGAN
The authors conclude that the Latent Mapper is suitable for complex attributes, while the Global Direction suffices for simpler and/or a more common attributes.
The Global Direction method is compared with other StyleGAN manipulation methods including the GANSpace, InterFaceGAN, and the StyleSpace
 Comparison of the Global Direction with baseline methods
Comparison of the Global Direction with baseline methods
A point that should be noted is that when it comes to real-application, the initial latent code $w$ or $s$ should be approximated somehow (usually by optimization process). This means that it may take at least a few minutes to semantically edit an unseen image with unknown latent code. One of my research topic was to train a deep neural network that can directly map an image to the StyleGAN latent space, which can significantly reduce the bottleneck introduced by the latent code search. Although my attempts have not been very successful restoring blurry images from the deep neural network based latent code encoding, overcoming this time bottleneck of the latent code search is expected to allow real-world application of semantic image editing.
Related
- A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
- Video Language Planning
- PaLI-3 Vision Language Models: Smaller, Faster, Stronger
- Collaborative Score Distillation for Consistent Visual Synthesis
- Tackling the Generative Learning Trilemma with Denoising Diffusion GANs