Significance
Keypoints
- Propose a contrastive learning framework to address non-i.i.d dataset across local updates during federated training
- Image classification accuracy, training efficiency, scalability are improved over baseline federated-learning algorithms
Review
Background
The federated learning is a server-centered machine learning framework that does not require sharing local data between clients (or parties), keeping it safe from potential security/privacy issues. The federated learning process usually takes steps of (1) distributing the global model to local parties, (2) training the model locally with data on each party, (3) sending the trained model back to the server, and (4) aggregating the collected local models to update the global model.
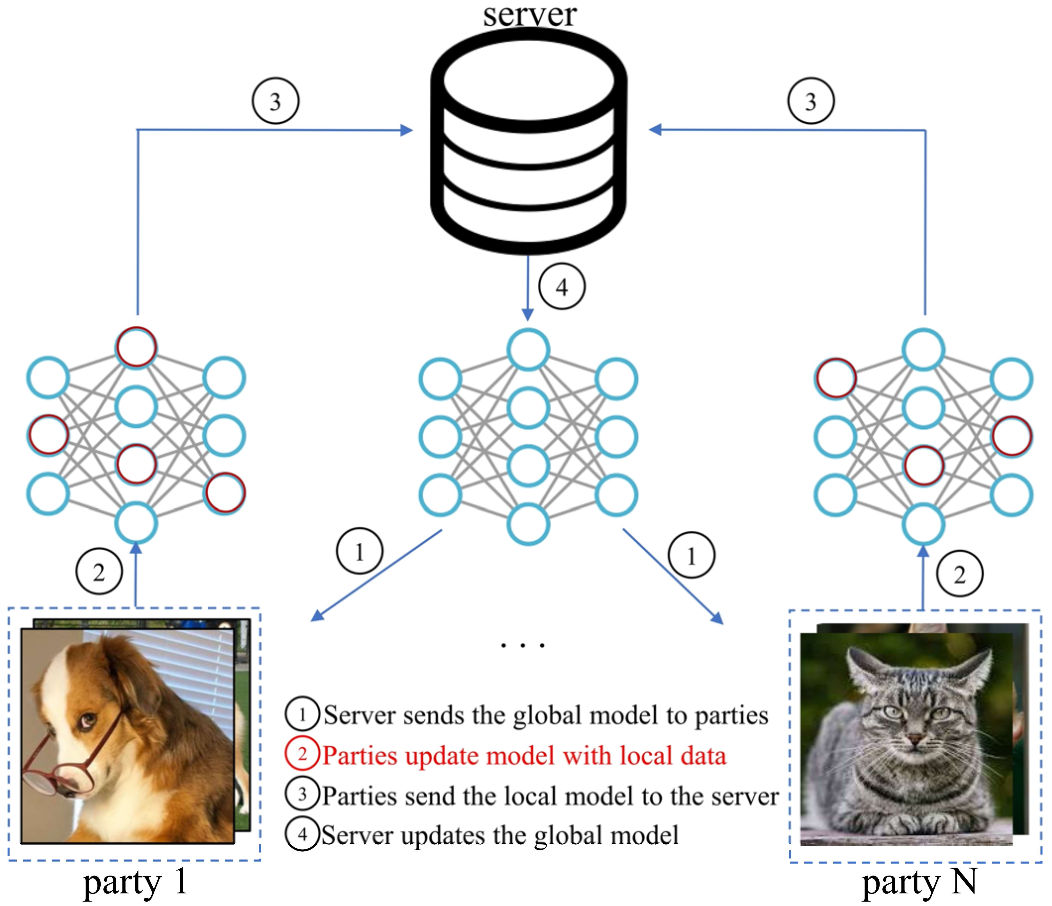 Federated learning process
For example, FedAvg is considered a de facto method for federated learning, which averages the parameter weights of the collected local models to update the global model.
Federated learning process
For example, FedAvg is considered a de facto method for federated learning, which averages the parameter weights of the collected local models to update the global model.
Training the local model with its own data resource ensures safety of the federated learning, but also leads to skewed distribution of the training dataset between parties. Training with non-i.i.d dataset can significantly hurt the performance in terms of generalization of the final model, and a few previous works (FedProx, SCAFFOLD) tried to tackle this non-i.i.d dataset issue of the federated learning. This work also tries to address this problem, with a contrastive style self-supervised strategy during the local training step.
Keypoints
Propose a contrastive learning framework to address non-i.i.d dataset across local updates during federated training
Setting appropriate target of the training is an important point when establishing a self-supervised learning process.
This work employs contrastive self-supervised learning, which updates the network with a set of anchor-positive, and anchor-negative pairs of training data.
The intuitive observation of the authors is that the general model is, and should be, trained with less skewed dataset than the local model.
Following this intuition, the authors suggest to minimize the distance between the latent representation obtained from the global model $z_{glob}$ and the representation obtained from the local model $z$, serving as the positive pair of training data.
The negative pair of training data is defined as the local model representation $z$ and the local model representation from the previous round $z_{prev}$.
Thus, the proposed contrastive loss is defined as:
\begin{equation}
\ell_{con} = -\log\frac{\exp(\text{sim}(z, z_{glob})/\tau)}{\exp(\text{sim}(z,z_{glob})/\tau)+\exp(\text{sim}(z,z_prev)/\tau)},
\end{equation}
where $\tau$ denotes the temperature parameter.
The final loss is a summation of the contrastive loss $\ell_{con}$ and the supervised learning loss $\ell_{sup}$ (e.g. cross-entropy loss), ratio controlled by a hyperparameter $\mu$:
\begin{equation}
\ell = \ell_{con} + \mu\ell_{sup}
\end{equation}
The global model update is done by averaging the trained local model weights at each round, as in the FedAvg.
 Pseudocode of the proposed method
Pseudocode of the proposed method
Image classification accuracy, training efficiency, scalability are improved over baseline federated-learning algorithms
The proposed method (abbreviated as MOON) is compared with baseline federated learning frameworks including FedAvg, FedProx, and SCAFFOLD.
A simple CNN or a ResNet-50 model is used in the experiment with CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets.
The proposed MOON achieves significant improvement on image classification accuracy over other baseline federated learning models with better training efficiency.
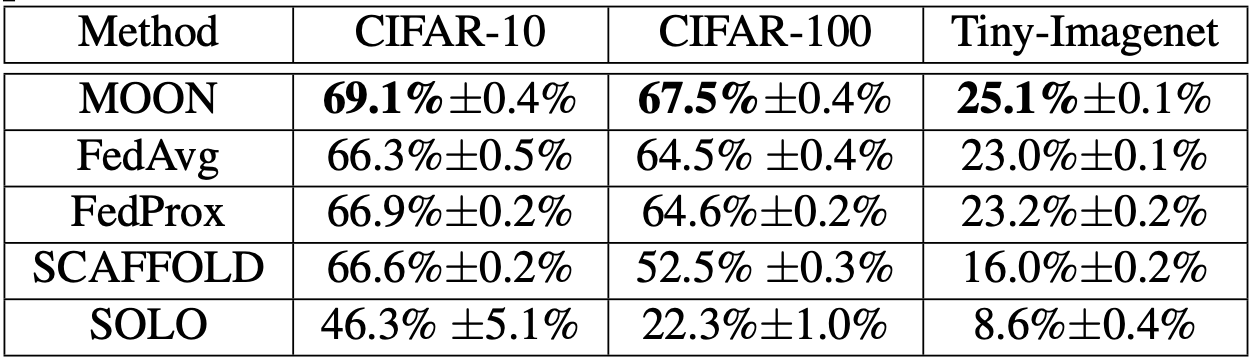 Image classification performance
Image classification performance
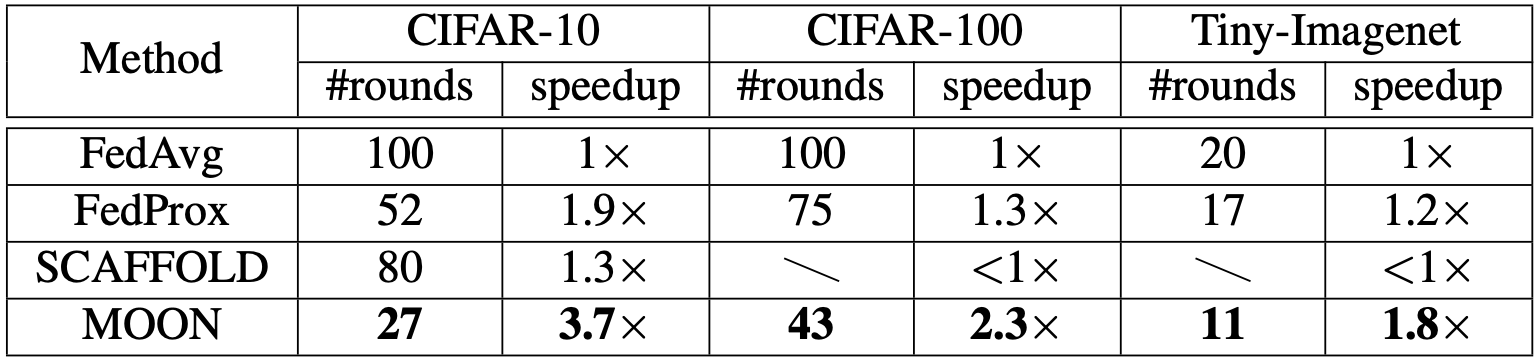 Training efficiency
Training efficiency
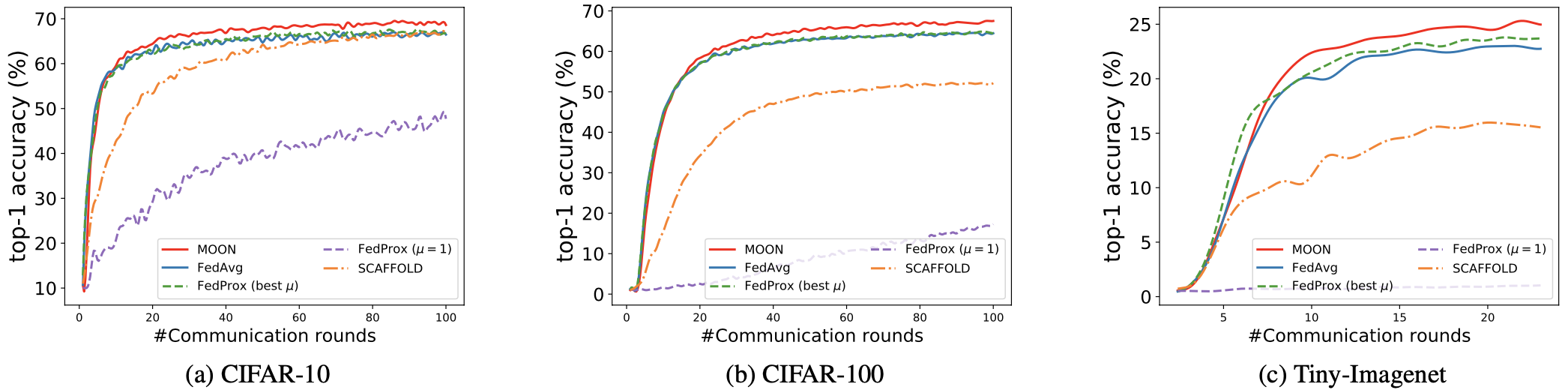 Top-1 accuracy with respect to training rounds
Top-1 accuracy with respect to training rounds
Scalability of the MOON is also demonstrated by the comparative experiment, setting number of parties to 50 and 100.
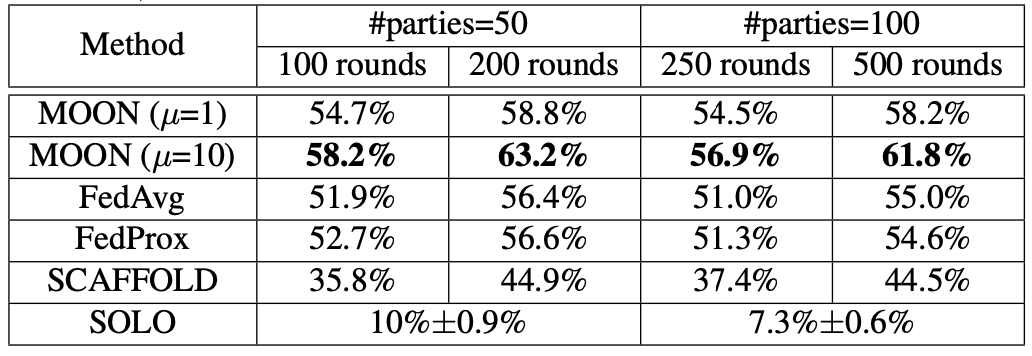
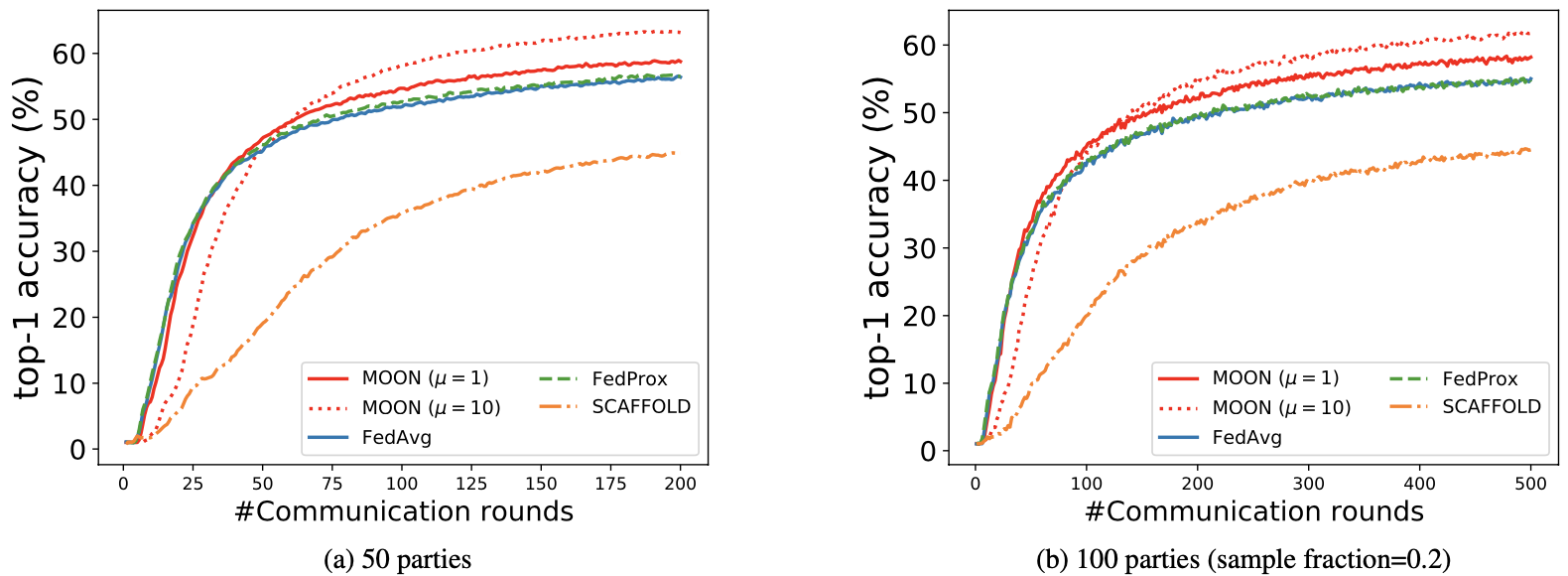 Scalability of the MOON
Scalability of the MOON
The improvement seems quite significant at first glance, and a more extensive experiment on other datasets/models is expected to further confirm this significance of the MOON.
Related
- Masked Autoencoders Are Scalable Vision Learners
- InfoGCL: Information-Aware Graph Contrastive Learning
- FedPara: Low-rank Hadamard Product Parameterization for Efficient Federated Learning
- Hybrid Generative-Contrastive Representation Learning
- MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training