Significance
Keypoints
- Propose a framework for video action localization incorporating actionness
- Demonstrate performance of proposed method by extensive comparative studies
Review
Background
Action localization refers to a task that aims to classify whether an instance (a frame, or a clip from the whole video) of a video includes one of the action classes or not. Weakly supervised learning is a prominent direction in the action localization task, since instance-wise labelling is too costly. In the weakly supervised setting, video-wise action labels, which is the union of all instance action classes in the video, are used to train the model.
Most methods learn to first select top-$k$ instances, and then perform localization. This top-$k$ selection usually contains useful information of the instance, but not specific to whether the instance contains an action. The authors address this issue and propose to incorporate actionness, which is the action-related intrinsic property of the instance.
Keypoints
Propose a framework for video action localization incorporating actionness
Given a video $X$ with a set of $T$ instances $\{ x_{1},…, x_{T}\}$, each instance of a video can be a frame or a fixed-interval segment represented by a feature vector $x_{t}\in\mathbb{R}^{d}$ with length $d$. The goal of the video action localization is to classify each instance $x_{i}$ of the video into a background, or one of an action of $C$ action classes, $Y\subseteq \{0,1,…,C\}$. For a weakly supervised setting, the label contains a union of action classes from the instances of the video, not per each instance.
The neural network video classifier $F_{c,t}$ is usually used to output a class activation sequence $s_{c,t}$ based on the instance set: \begin{equation} s_{c,t} = F_{c,t}(x_{1},…,x_{T}). \end{equation} Then, top-$k$ pooling is applied over $s_{c,t}$ to aggregate the highest activated instances to output predictions for the whole video: \begin{equation}\label{eq:topk} \mathcal{T}^{c} = \underset{\mathcal{T}\subseteq \{1,…,T\} }{\arg \max}\sum\nolimits_{t\in\mathcal{T}} s_{c,t}, \end{equation} where cardinality of $\mathcal{T}$ is constrained to be a pre-specified number $k$. The selected instances $\mathcal{T}^{c}$ are aggregated to make final video-level class probability prediction $p_{c}$: \begin{equation}\label{eq:prob} p_{c} = \text{softmax}(\frac{1}{|\mathcal{T}^{c}|}\sum_{t\in \mathcal{T}^{c}}s_{c,t}). \end{equation}
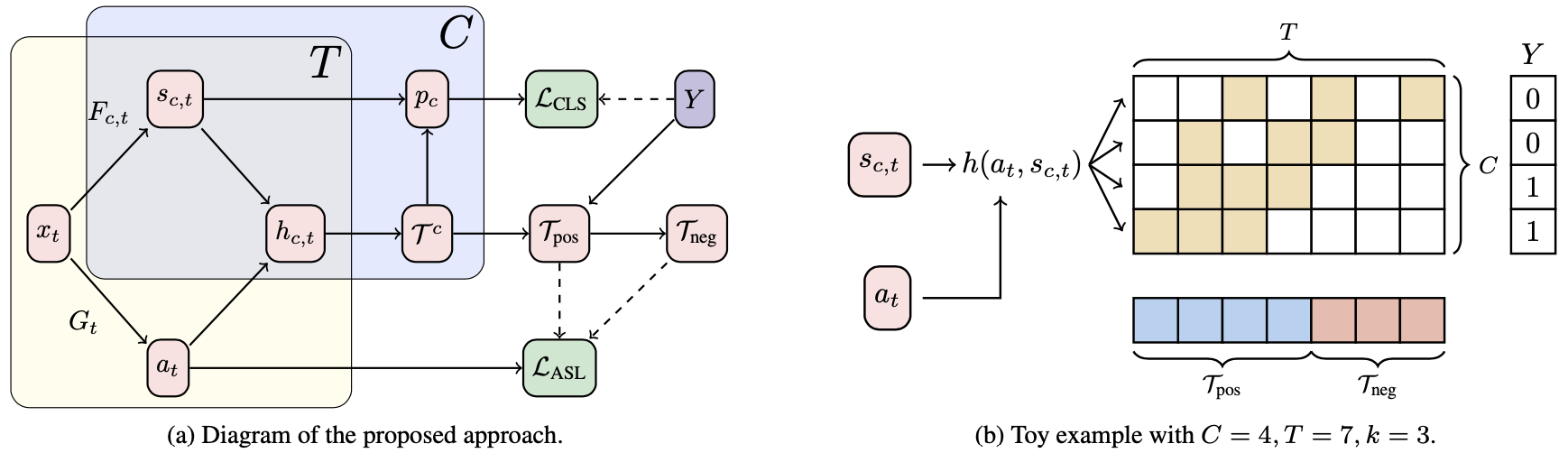 (a) Schematic diagram of the proposed method. The actionness $a_{t}$ is the key idea. (b) Contrastive training example
(a) Schematic diagram of the proposed method. The actionness $a_{t}$ is the key idea. (b) Contrastive training example
As mentioned in the background section, the authors aim to incorporate actionness $a_{t}$ to the class activation sequence $s_{c,t}$ to output a new instance $h_{c,t}$ which account for both properties: \begin{equation} h_{c,t} = g(a_{t}, s_{c,t}) \end{equation} where the selection function $g$ is defined as a linear interpolation between $a_{t}$ and $s_{c,t}$. To define actionness $a_{t}$, an intuitive obeservation of the authors is that action is more ubiquituous across time than a context, which is highly class dependent. Here, context refers to the context arising from the scene of the instance, which can falsely imply action and confuse the model. From the observation, the actionness is trained with a contrastive pair \begin{align} \mathcal{T}_{\text{pos}} = \underset{c\in Y}{\bigcup}\mathcal{T}^{c} \\ \mathcal{T}_{\text{neg}} = \{ 1,…,T \} \setminus \mathcal{T}_{\text{pos}} \end{align} and train a neural network $G$ which outputs actionness $a_{t} = \sigma (G_{t}(x_{1},…,x_{T}))$ with the loss: \begin{equation} \mathcal{L}_{\text{ASL}} = \frac{1}{|\mathcal{T}_{\text{pos}}|} \sum \nolimits _{t\in \mathcal{T}_{\text{pos}}} \frac{1-(a_{t})^{q}}{q} + \frac{1}{|\mathcal{T}_{\text{neg}}|}\sum \nolimits _{t\in \mathcal{T}_{\text{neg}}} \frac{1-(1-a_{t})^{q}}{q}. \end{equation} where $0<q\leq 1$ denotes noise tolerance.
Demonstrate performance of proposed method by extensive comparative studies
Extensive comparative experiments are conducted with two localization datasets: THUMOS-14 and ActivityNet-1.2.
The average precision at different intersection over union (AP@IOU, mAP) is compared with baseline methods including TSM, CMCS, MAAN, 3C-Net, CleanNet, BaSNet, BM, DGAM, TSCN, and EM-MIL.
The proposed method outperforms other baseline methods on both datasets.
Ablation experiments are also demonstrated for the THUMOS-14 dataset.
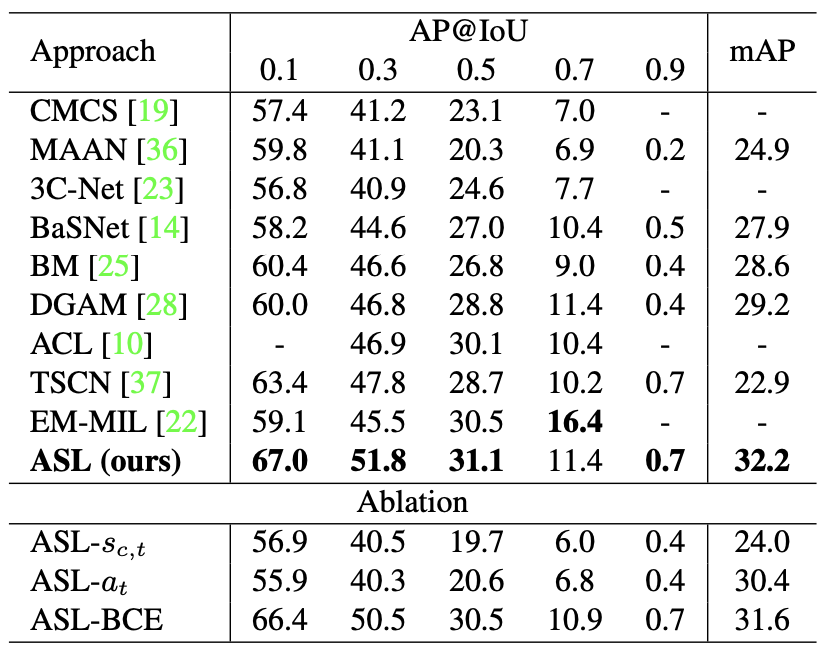 Comparative experiment result of the proposed method on THUMOS-14
Comparative experiment result of the proposed method on THUMOS-14
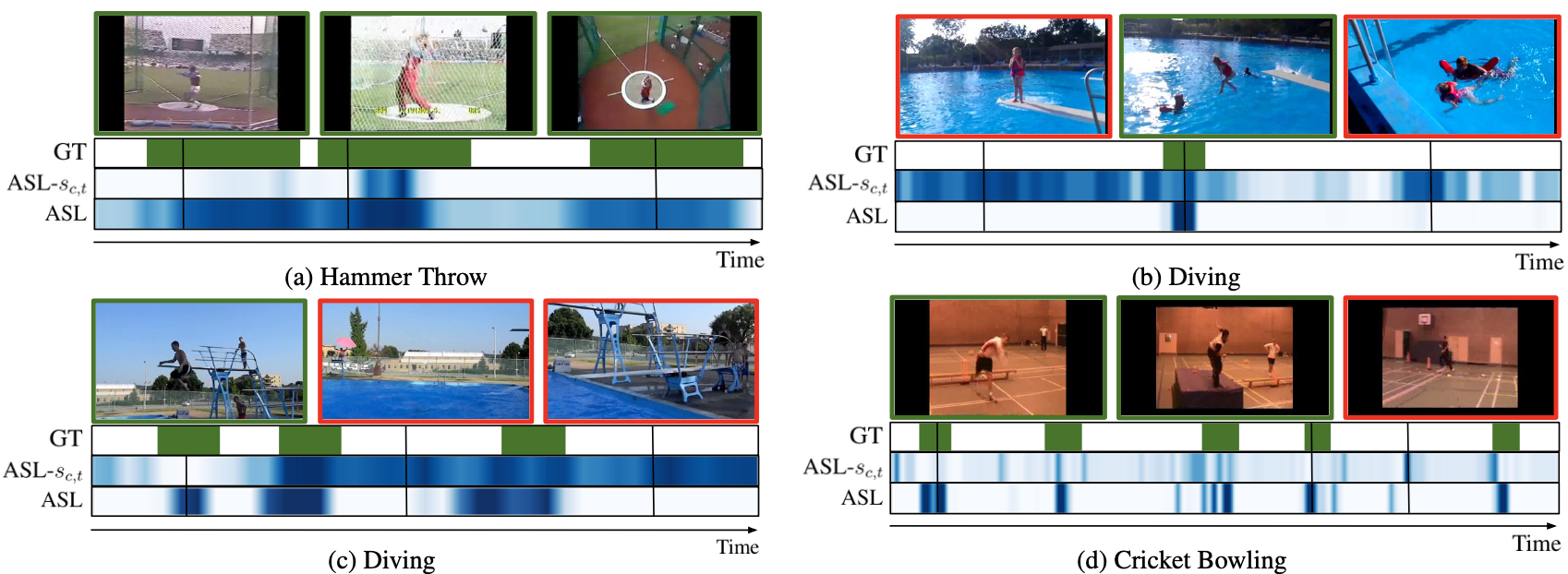 Qualitative performance of the proposed method on THUMOS-14
Qualitative performance of the proposed method on THUMOS-14
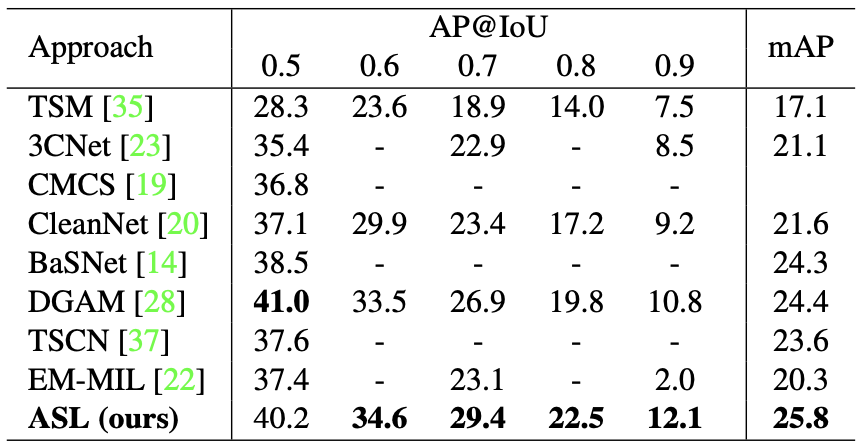 Comparative experiment result of the proposed method on ActivityNet-1.2
Comparative experiment result of the proposed method on ActivityNet-1.2
Per-class AP result is provided for further demonstration.
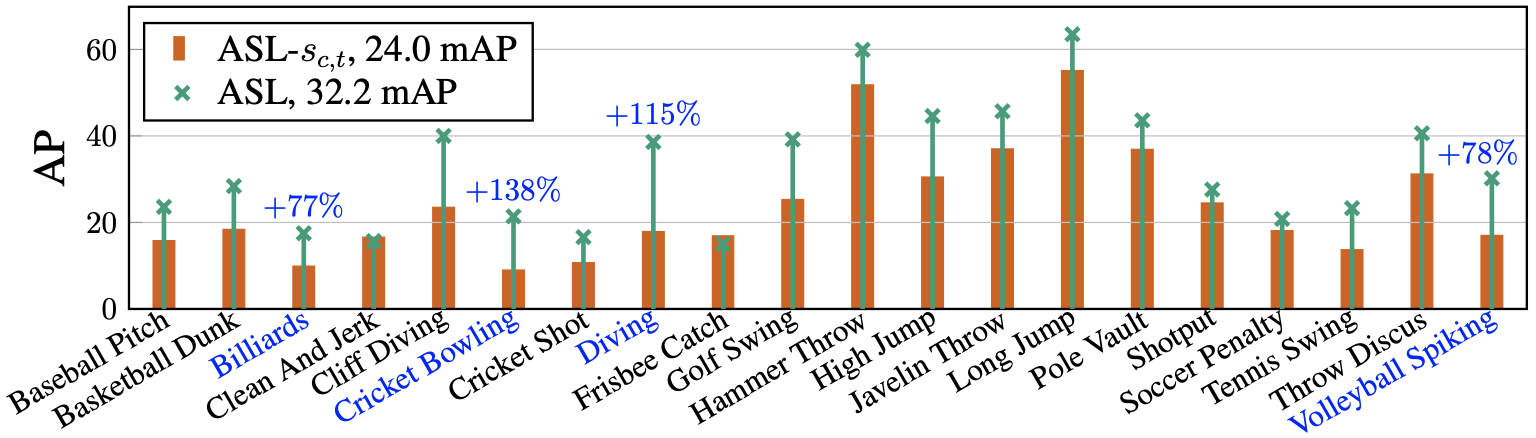 Per-class AP result of the proposed method on THUMOS-14
The blue highlighted classes indicate four classes with highest improvement on the mAP when compared to the proposed method without actionness (ASL-$s_{c,t}$).
Per-class AP result of the proposed method on THUMOS-14
The blue highlighted classes indicate four classes with highest improvement on the mAP when compared to the proposed method without actionness (ASL-$s_{c,t}$).
The extensive experimental results suggest exceptional performance of the proposed method on action localization, and the importance of incorporating actionness $a_{t}$.