Significance
Keypoints
- Propose a point-cloud based method for novel view synthesis with style transfer
- Demonstrate qualitative and quantitative performance of the proposed method
Review
Background
Novel view synthesis refers to a task that aims to generate an image of a new point of view, given a set of images from a 3D scene. Style transfer is a task that aims to modulate the style of an image to match that of a reference image. Although recent development in computer vision has led to remarkable progress in both tasks separately, a study that tries to perform style transfer and novel view synthesis at the same time is lacking. It might seem that performing style transfer followed by novel view synthesis, or the opposite would suffice for style transferring with novel view synthesis. However, the authors point out that this kind of serial application can lead to short-, long-range inconsistency or blurry results. The authors address this issue and propose a point cloud based method for novel view synthesis with style transfer.
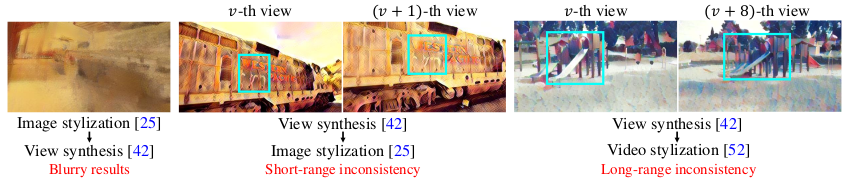 Serial application of style transfer and novel view synthesis lead to unsatisfactory results
Serial application of style transfer and novel view synthesis lead to unsatisfactory results
Keypoints
Propose a point cloud based method for novel view synthesis with style transfer
To accurately transfer style with an image from a novel view, the authors propose to first project the 2D image into a 3D point cloud.
Specifically, 3D point cloud are constructed from a set of input images with COLMAP and Delaunay-based schemes.
The point clouds are modulated with a reference image by pointwise linear transformation to match the covariance statistics of the reference image.
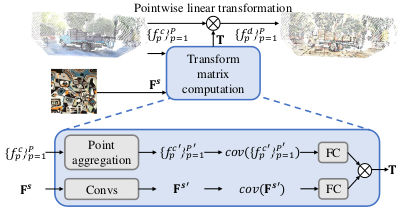 Modulating point clouds with a reference image $\mathbf{S}$
The style feature map $\mathbf{F}^{s}$ is defined as the relu3_1 activation of a ImageNet pre-trained VGG-19 network.
Given the input image point cloud $\{f^{c}_{p} \}^{P}_{p=1}$, the modulated point cloud $\{f^{d}_{p} \}^{P}_{p=1}$ is computed by:
\begin{align}
f^{d}_{p} = \mathbf{T}(f^{c}_{p}-\bar{f}^{c}) + \bar{f}^{s}, \quad \forall p \in [1,…,p],
\end{align}
where $\mathbf{T}$ is a predicted linear transformation matrix and the $\bar{f}$ refers to average of the features in the point cloud.
Linear transformation matrix $\mathbf{T}$ is a multiplication of two matrices from the input point cloud $\{f^{c}_{p} \}^{P}_{p=1}$ and the reference feature map $\mathbf{F}^{s}$ (see Figure above).
The point cloud aggregation process is based on the set abstraction concept.
Given the modulated point cloud $\{f^{d}_{p} \}^{P}_{p=1}$, a decoder network reconstructs stylized-novel view image.
The decoder network is trained first without style transfer, and the point cloud transformation module is trained afterwards with fixed decoder network.
Modulating point clouds with a reference image $\mathbf{S}$
The style feature map $\mathbf{F}^{s}$ is defined as the relu3_1 activation of a ImageNet pre-trained VGG-19 network.
Given the input image point cloud $\{f^{c}_{p} \}^{P}_{p=1}$, the modulated point cloud $\{f^{d}_{p} \}^{P}_{p=1}$ is computed by:
\begin{align}
f^{d}_{p} = \mathbf{T}(f^{c}_{p}-\bar{f}^{c}) + \bar{f}^{s}, \quad \forall p \in [1,…,p],
\end{align}
where $\mathbf{T}$ is a predicted linear transformation matrix and the $\bar{f}$ refers to average of the features in the point cloud.
Linear transformation matrix $\mathbf{T}$ is a multiplication of two matrices from the input point cloud $\{f^{c}_{p} \}^{P}_{p=1}$ and the reference feature map $\mathbf{F}^{s}$ (see Figure above).
The point cloud aggregation process is based on the set abstraction concept.
Given the modulated point cloud $\{f^{d}_{p} \}^{P}_{p=1}$, a decoder network reconstructs stylized-novel view image.
The decoder network is trained first without style transfer, and the point cloud transformation module is trained afterwards with fixed decoder network.
Demonstrate qualitative and quantitative performance of the proposed method
The proposed method is compared with a series of novel view synthesis → image/video style transfer, or image style transfer → novel view synthesis methods.
User preference study results indicate that the proposed method has better consistency and stylization over different generated views.
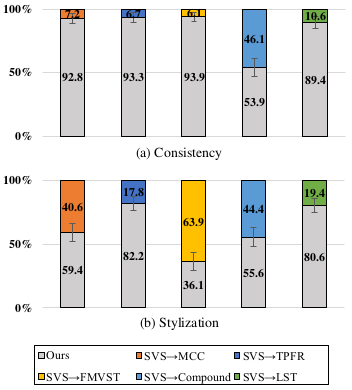 User preference study results
Quantitative evaluation of consistency is further done by measuring the warped LPIPS between the viewpoints from adjacent video frames (short-range consistency) or from 7-frame distant frames (long-range consistency).
User preference study results
Quantitative evaluation of consistency is further done by measuring the warped LPIPS between the viewpoints from adjacent video frames (short-range consistency) or from 7-frame distant frames (long-range consistency).
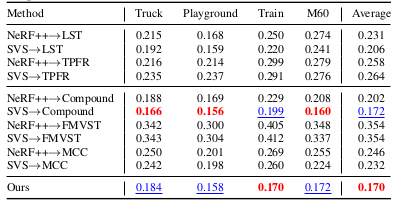 Short-range consistency result
Short-range consistency result
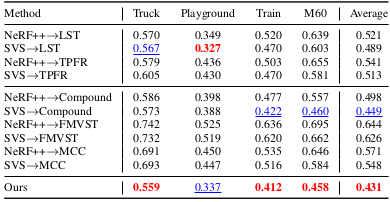 Long-range consistency result
Long-range consistency result
Qualitative results also imply superior performance of the proposed method in novel view synthesis with style transfer, when compared to the serial image style transfer + novel view synthesis methods.
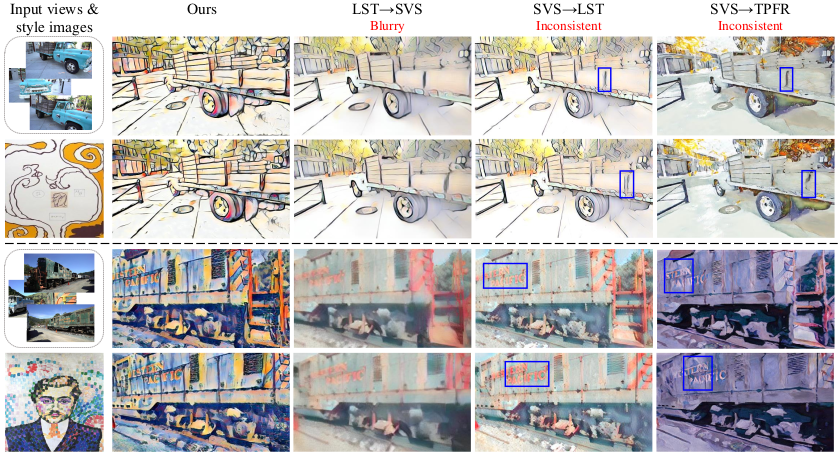 Qualitative result of the proposed method
Qualitative result of the proposed method