Significance
Keypoints
- Propose purchase likelihood estimation framework which integrates query, history, and product embeddings
- Show quantitative improvement over baseline and discuss qualitative limitations
Review
Background
Entity resolution (entity linking) refers to finding a matching entry within a knowledge database, based on a given query.
Application of entity resolution algorithms in industry is still limited due to difficulties related to the knowledge database or the query.
Specifically, a lot of new entities take up majority of the knowledge database but has little interaction with other entities (unpopular majority), and users often provide ambiguous variants as their queries.
To address the unpopular majority issue that arise in the shopping industry, the authors propose to define an extended knowledge database with richer interaction between the entities by merging two types of knowledge graphs, the customer-product graph and the product knowledge graph.
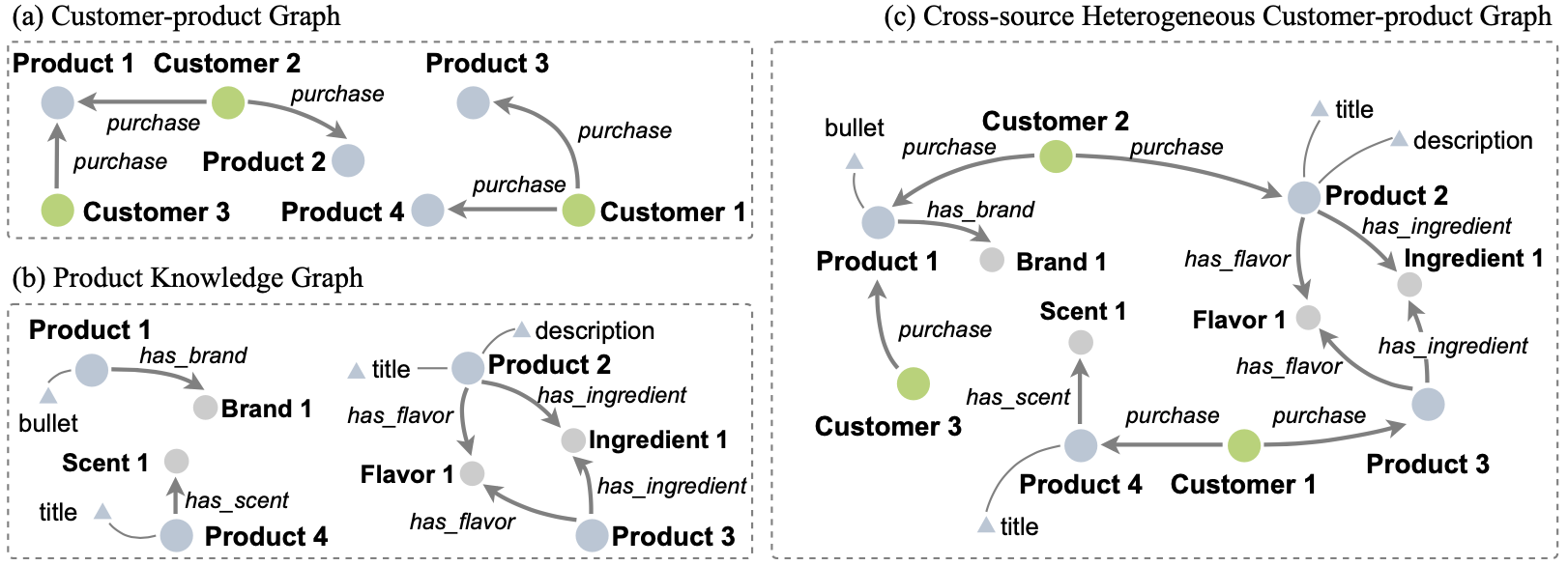 Customer 1 and 2 are related on the merged graph (c), but not on (a)
This extended knowledge graph is expected to provide better representation of the product, and can help provide better prediction of the candidate items that the user is going to actually purchase.
Customer 1 and 2 are related on the merged graph (c), but not on (a)
This extended knowledge graph is expected to provide better representation of the product, and can help provide better prediction of the candidate items that the user is going to actually purchase.
Keypoints
Propose purchase likelihood estimation framework which integrates query, history, and product embeddings
The most important idea of the proposed method is actually already provided in the Background section. Goal of the proposed framework is to output a candidate score in the range $[0,1]$ which demonstrates how likely the user is going to purchase that candidate item. Here, the item is described as a candidate, because not all items are input to the framework to output the score, but only a number of selected items are considered. These candidate items are selected by the QUARTS method based on the query of the user, which means that the proposed framework is built upon the QUARTS.
Next, the customer-product graph is merged with the product knowledge graph of the candidate items to form an extended knowledge database. Joint representation of the customers and products can now be obtained by using a GNN (two-layer Relational Graph Convolutional Network) over the merged graph. To further enrich the customer and product embeddings, other information regarding the customer (purchase history) and the product (rank from the QUARTS, relative price, whether previously purchased) are concatenated to the GNN extracted representations.
Finally, a two layer feed forward neural network is trained with a binary cross-entropy loss to output the candidate score.
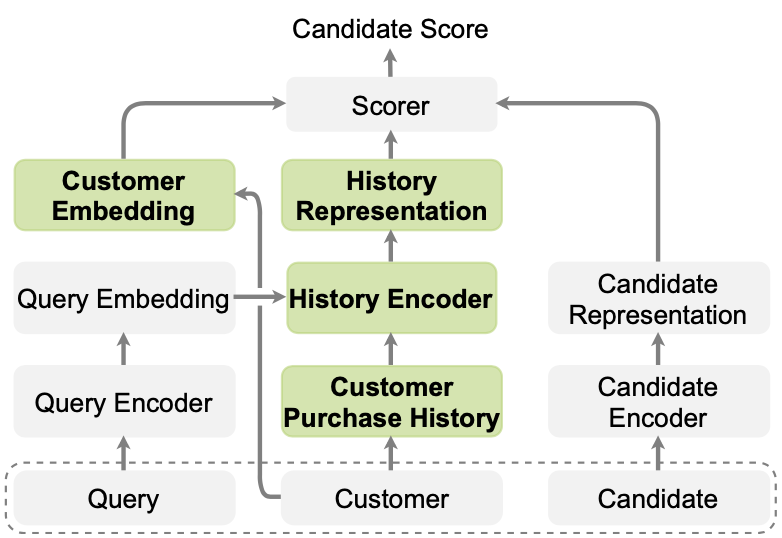 Schematic illustration of the proposed framework
Schematic illustration of the proposed framework
Show quantitative improvement over baseline and discuss qualitative limitations
The experiments are performed over in-house dataset with product knowledge graph (24 million product entities) and randomly selected user purchase session with queries (1 million purchases). Wow…
Query embedding is obtained with a pre-trained GloVe and textual features from knowledge database are encoded with RoBERTa.
Quantitative analysis is focused on comparing the performance of the proposed framework with QUARTS.
Since the framework is based on the QUARTS candidate selection, this can be viewed as evaluating how much improvement is obtained by integrating the extended knowledge graph embeddings.
The metric is calculated as whether the top-1 candidate score item matches the actual purchase of the customer.
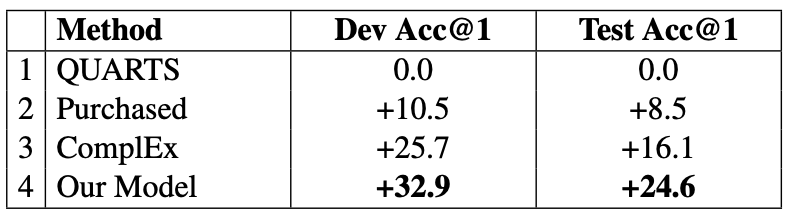 Quantitative performance improvement with respect to QUARTS
An improvement of 24.6% top-1 accuracy in the test dataset is reported, but the accuracy itself is not provided.
Quantitative performance improvement with respect to QUARTS
An improvement of 24.6% top-1 accuracy in the test dataset is reported, but the accuracy itself is not provided.
Ablation study is also performed by the authors.
 Ablation study result
Ablation study result
Qualitative analysis of randomly selected 100 failure cases revealed a number of reasons for wrong candidate scoring including different size, similar description, etc.
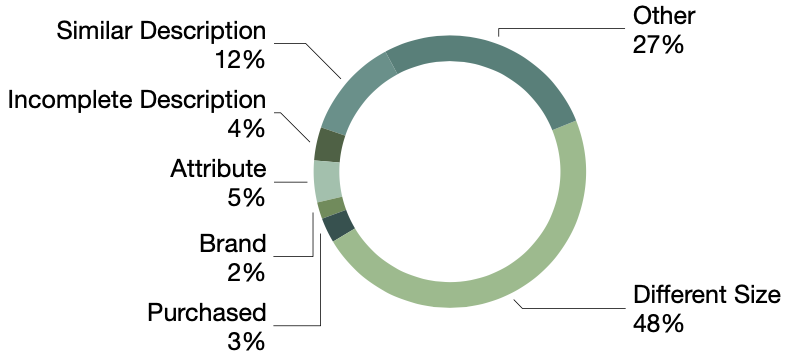 Qualitative assessment of failure cases
Qualitative assessment of failure cases
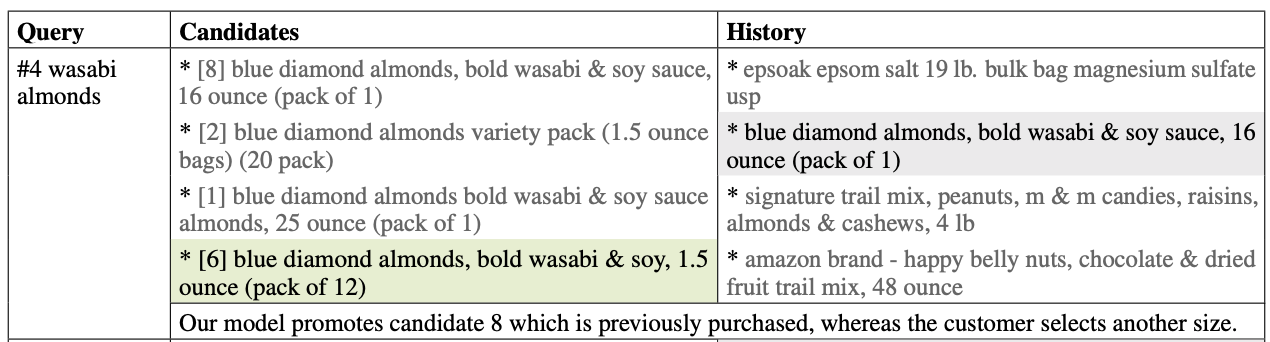 A negative example (different size) in the test set
Could the future algorithms accurately predict the item which is going to be purchased, along with its accurate size too?
A negative example (different size) in the test set
Could the future algorithms accurately predict the item which is going to be purchased, along with its accurate size too?