Significance
Keypoints
- Propose a heterogenous visual search framework for optimal efficiency-accuracy tradeoff
- Demonstrate performance and efficiency of the proposed method by experiments
Review
Background
Visual search, or image retrieval task refers to retrieving a set of gallery images $\mathcal{X}_{g}$ given a query image $\mathbf{x}_{q}\in\mathcal{X}_{q}$.
Recent image retrieval methods usually exploit the metric learning scheme by encoding the query and gallery images with a same neural network $\phi$ and computing the distance between the encoded latent vectors $\phi(\mathbf{x}_{q})$ and $\phi(\mathbf{x}_{g})$.
Although using the same $\phi$ for encoding both query and gallery image is straightforward, it can be not very optimal in terms of accuracy-efficiency tradeoff.
In other words, encoding model $\phi$ with a large number of parameters can achieve good retrieval accuracy while computationally inefficient, and vice versa.
The authors refer to the setup that splits the model $\phi$ for query $\phi_{q}$ and gallery $\phi_{g}$ images as heterogeneous visual search.
With the heterogenous visual search setup, both high-efficiency and comparable accuracy could be achieved.
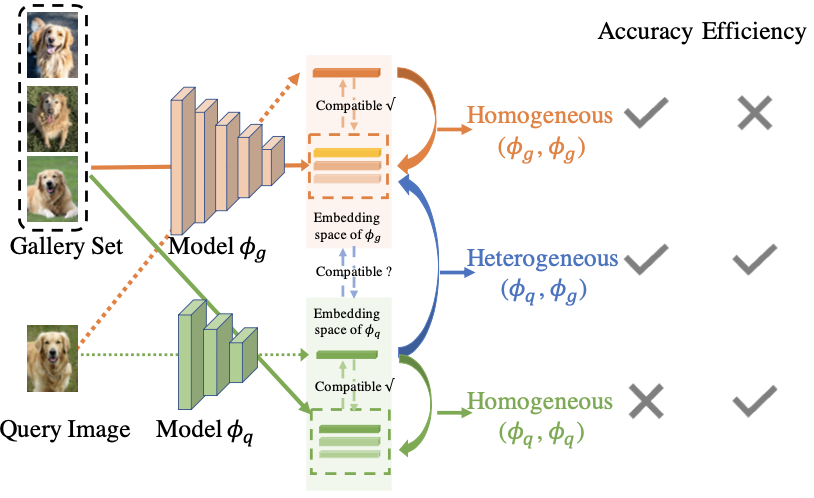 Heterogenous visual search and accuracy-efficiency tradeoff
Heterogenous visual search and accuracy-efficiency tradeoff
Keypoints
Propose a heterogenous visual search framework for optimal efficiency-accuracy tradeoff
The authors denote compatibility between the two models $\phi_{q}$ and $\phi_{g}$ as the two models with smaller parameters achieve better accuracy.
To achieve the compatibility between the two models, the Backward-compatible training (BCT) with the Neural architecture search (NAS) is used for optimization.
During preliminary experiments for searching the suitable light-weight model within ShuffleNet, it was shown that the heterogeneous accuracy was not dependent on the flops.
Furthermore, the homogeneous accuracy did not correlate well with the heterogenous accuracy when trained without the BCT.
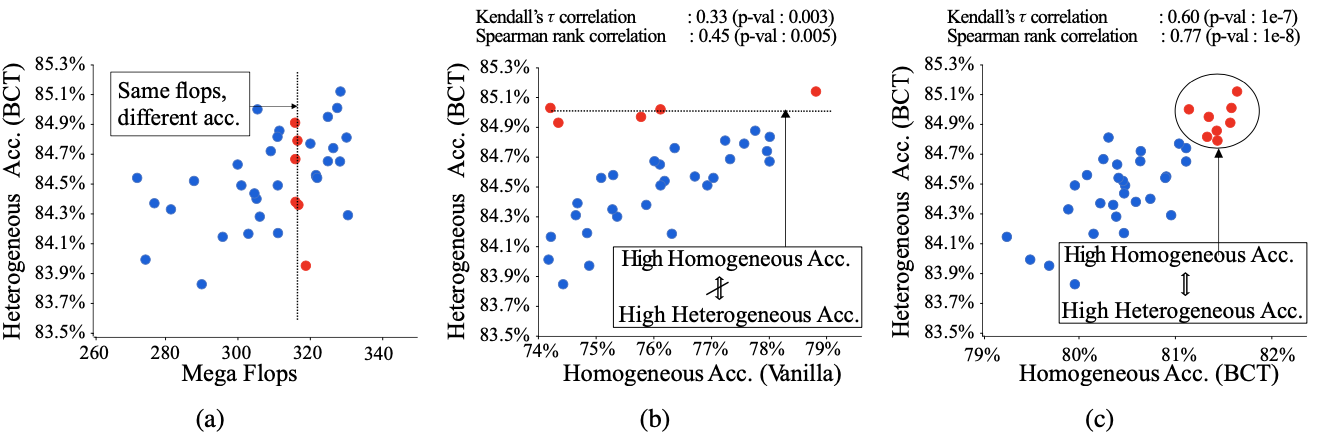 Heterogenous accuracy vs (a) FLOPs of the ShuffleNet models (b) NAS with no BCT (c) NAS with BCT
These motivated the use of BCT for training the NAS model.
Specifically, the reward $\mathcal{R}$ to be maximized within the search space $\omega$ is reformulated to incorporate both symmetric and asymmetric accuracies ($\mathcal{R}_{3}$ from the below table)
Heterogenous accuracy vs (a) FLOPs of the ShuffleNet models (b) NAS with no BCT (c) NAS with BCT
These motivated the use of BCT for training the NAS model.
Specifically, the reward $\mathcal{R}$ to be maximized within the search space $\omega$ is reformulated to incorporate both symmetric and asymmetric accuracies ($\mathcal{R}_{3}$ from the below table)
 Different reward formulations. $M$ is the metric, $a$ is the model architecture, $w$ is the weight
Different reward formulations. $M$ is the metric, $a$ is the model architecture, $w$ is the weight
Demonstrate performance and efficiency of the proposed method by experiments
The performance/efficiency is demonstrated with the (i) face retrieval task from IMDB-Face (train/validation) and IJB-C (test) face dataset, and (ii) fashion retrieval task from Deep-Fashion2 dataset.
The baseline large model is the ResNet-101 and the baseline light-weight model is the MobileNetV3.
It can be seen that the proposed method, using the query model as CMP-NAS, achieves accuracy similar to the large model while the query FLOPs are similar to the light-weight model.
 Performance and efficiency on face retrieval task
Performance and efficiency on face retrieval task
 Performance and efficiency on fashion retrieval task
Performance and efficiency on fashion retrieval task
Ablating the BCT strategy and the using the different reward ($\mathcal{R}_{1}$ and $\mathcal{R}_{2}$) suggest the importance of the BCT and the reward type.
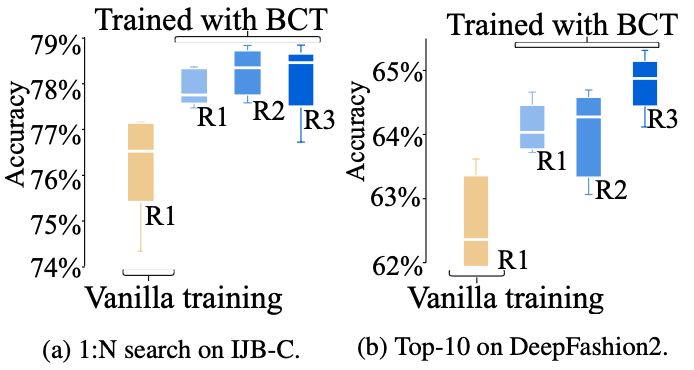 Ablation study results
Other detailed experiments and the discussion on the CMP-NAS are referred to the original paper.
Ablation study results
Other detailed experiments and the discussion on the CMP-NAS are referred to the original paper.