Significance
Keypoints
- Propose a GAN that can generate images of arbitrary resolution
- Demonstrate performance and computational efficiency of the proposed method
Review
Background
Recent Generative adversarial networks (GANs) are capable of generating realistic images with high resolution at the expense of large model size and long training time.
Whether the resolution is high is not quite definite, but many people who are familiar with GANs would think of 1024$\times$1024 image generated from a StyleGAN.
Is generating a 1024$\times$1024 image actually sufficient?
Shouldn’t an image of arbitrary width/height be generated based on the user’s intention, not fixed to a certain shape?
However, generating an image of arbitrary size requires considering a number of issues, such as finite computational resources and lack of arbitrarily shaped training data.
Models such as SinGAN is capable of generating an arbitrary image shape by its fully convolutional architecture, but memorizing patch distribution constrains the contextual diversity within an image.
The authors address these issues and propose InfinityGAN, which can generate an image of arbitrary shape with diverse global style using small amount of computational resources.
 InfinityGAN generated two-style high resolution image with single GTX Titan X
InfinityGAN generated two-style high resolution image with single GTX Titan X
Keypoints
Propose a GAN that can generate images of arbitrary resolution
The idea of generating an arbitrarily large image is realized by training a generator which can create small patches that compose the final image.
In this scheme, not only the local texture detail of the patch, but also the global structure consistency across the whole image that define the holistic appearance is important.
To make the large image realistic in both local and global scales, the authors propose to distinguish the texture synthesizer (generator) $G_{T}$ and the structure synthesizer $G_{S}$.
Specifically, the structure synthesizer first takes global latent $\mathbf{z}_{g}$ and local latent $\mathbf{z}_{l}$ sampled from Gaussian random noise along with coordinate embedding vector $\mathbf{c}$ to obtain structure latent vector $\mathbf{z}_{S}$:
\begin{align}
\mathbf{z}_{S} = G_{S}(\mathbf{z}_{g}, \mathbf{z}_{l}, \mathbf{c}) \\ \mathbf{c} &= (\tanh(i_{y}), \tanh(\frac{i_{x}}{T}), \sin(\frac{i_{x}}{T})),
\end{align}
where $T$ is the period of the sinusoid coordinates, $i_{x}$ and $i_{y}$ are horizontal and vertical indices, respectively.
Then, this structure latent vector $\mathbf{z}_{S}$ is input to the texture synthesizer $G_{T}$ along with global latent $\mathbf{z}_{g}$ and another random noise latent $\mathbf{z}_{n}$ for style diversity to generate patch image $\mathbf{p}_{\mathbf{c}}$ at coordinate $\mathbf{c}$:
\begin{equation}
\mathbf{p}_{\mathbf{c}} = G_{T}(\mathbf{z}_{S}, \mathbf{z}_{g}, \mathbf{z}_{n}).
\end{equation}
In this way, the patch image $\mathbf{p}_{\mathbf{c}}$ is created with the coordinate, structure latent noise, texture latent noise, and the style latent noise as prior.
The structure synthesizer $G_{S}$, the texture synthesizer $G_{T}$, and the discriminator $D$ are Convolution neural network, StyleGAN2 generator, and the StyleGAN2 discriminator with some modification, respectively.
The generator and the discriminator $D$ of the InfinityGAN are trained with the non-saturating logistic loss $\mathcal{L}_{adv}$ and the vertical coordinate match loss $\mathcal{L}_{ar}$ defined as:
\begin{equation}
\mathcal{L}_{ar} = || \hat{\mathbf{c}_{y}} - \bar{\mathbf{c}_{y}}||_{1},
\end{equation}
where $\hat{\mathbf{c}_{y}}$ is the vertical coordinate prediction by the discriminator and $\bar{\mathbf{c}_{y}}$ is the vertical coordinate from the real or generated images (I am not sure what “ar” is short for, when indicating the coordinate match loss).
The discriminator is further regularized with $R_{1}$ regularization $\mathcal{L}_{R_{1}}$, and the generator with path length regularization $\mathcal{L}_{path} and ModeSeek regularization $\mathcal{L}_{div}$. (I remember being impressed with the ModeSeek regularization when it was first proposed because it is quite easy to implement while addressing the mode collapse problem of GANs)
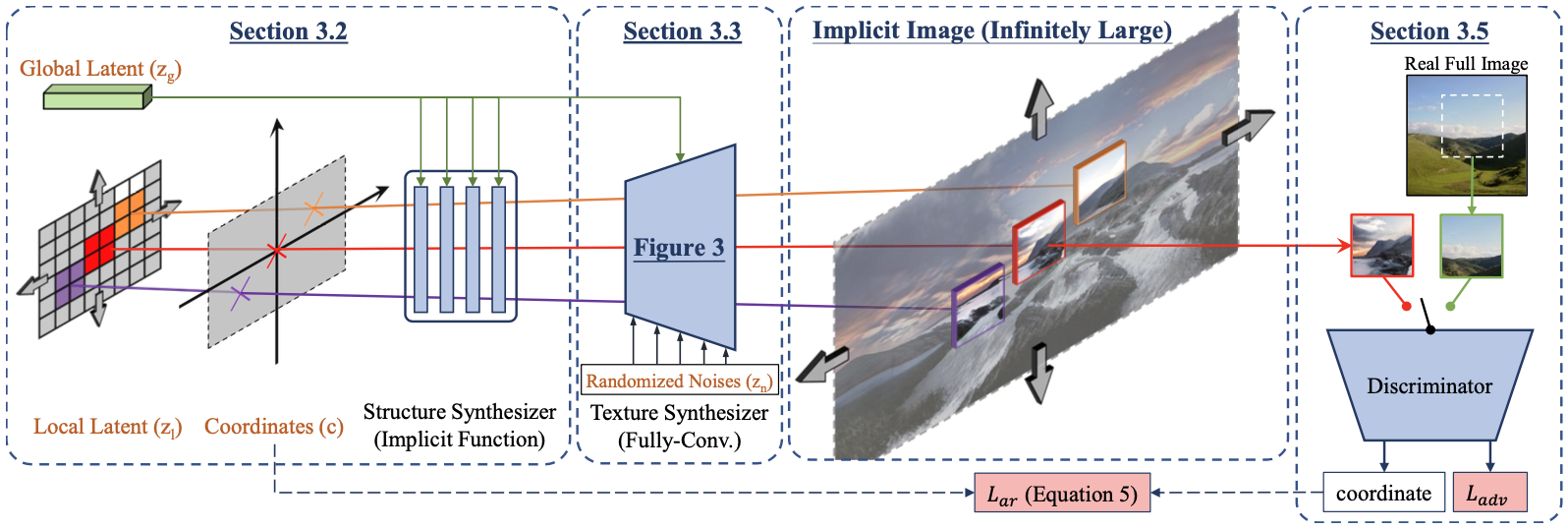 Overall scheme of the InfinityGAN
Overall scheme of the InfinityGAN
To generate high-resolution image by concatenating small patches seamlessly, the authors mention that removal of zero paddings from the convolution layer is important.
This is because output with zero paddings encode position information, where zeros can indicate the border of the convolution output.
By removing the zero paddings, the texture synthesizer can only be responsible for generating texture representation, not considering the pixel position within the patch.
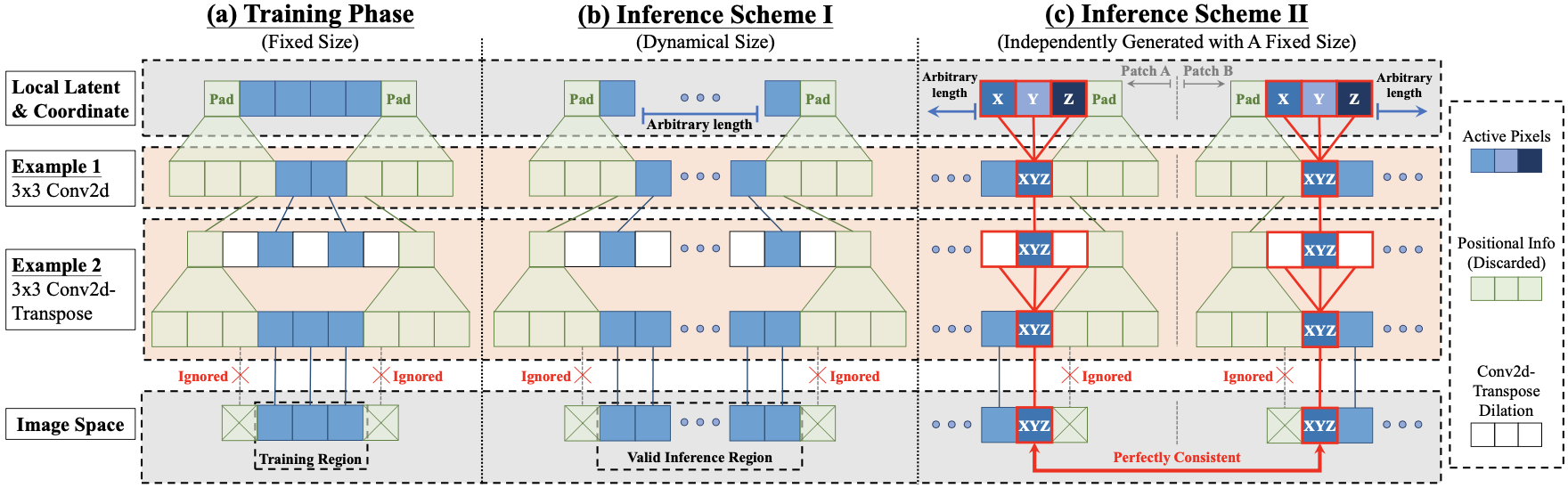 Spatially independent generation by convolution layer without paddings
These patches can be stacked into a mini-batch and be inferred in a parallel manner, speeding up the inference time of InfinityGAN significantly.
Spatially independent generation by convolution layer without paddings
These patches can be stacked into a mini-batch and be inferred in a parallel manner, speeding up the inference time of InfinityGAN significantly.
Demonstrate performance and computational efficiency of the proposed method
The authors compare the proposed InfinityGAN with SinGAN, COCO-GAN, and StyleGAN2.
The FID, ScaleInv FID, and user preference study are performed to quantitatively evaluate the performance.
ScaleInv FID refers to the FID score computed after downscaling (by bilinear interpolation) the generated image to match the training image size.
 Quantitative performance of InfinityGAN
It should be noted that the memory complexity is constant ($\mathcal{O}(1)$) irrespective of the resolution for the proposed method.
Quantitative performance of InfinityGAN
It should be noted that the memory complexity is constant ($\mathcal{O}(1)$) irrespective of the resolution for the proposed method.
Qualitatively, the InfinityGAN generates a more realistic image than baselines even when the image size is larger than the training dataset image size.
 Qualitative performance of InfinityGAN
The authors also qualitatively show that manipulating the local latent $\mathbf{z}_{l}$ or the texture latent $\mathbf{z}_{T}$ (the global latent $\mathbf{z}_{g}$ after nonlinear mapping) while other variables are fixed results in independent structural or style variation, respectively.
Qualitative performance of InfinityGAN
The authors also qualitatively show that manipulating the local latent $\mathbf{z}_{l}$ or the texture latent $\mathbf{z}_{T}$ (the global latent $\mathbf{z}_{g}$ after nonlinear mapping) while other variables are fixed results in independent structural or style variation, respectively.
 Structure and style are modeled separately
Structure and style are modeled separately
Possible applications of the InfinityGAN include spatial style fusion, image outpainting, etc. However, the InfinityGAN has not been tested on image datasets that focus on objects (faces, cars, animals) but only on the landscape. I think that generating an object image might be more difficult than generating a landscape image for the InfinityGAN because of the image cropping during training. A cropped landscape image still preserves the landscape image as a whole, but a cropped car image might be a different problem for the discriminator of the GANs to properly learn the expected representation. Further experiments with other image datasets would demonstrate whether InfinityGAN is capable of generating object images.
Related
- A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
- Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
- Image Synthesis and Editing with Stochastic Differential Equations
- RewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image
- ViTGAN: Training GANs with Vision Transformers