Significance
Keypoints
- Experiment Transformer based pre-training and token embedding schemes for Java language bug fix
Review
Background
Although some methods that can automatically fix bugs from a program have provided interesting performance metrics, the metrics are sometimes overestimated because simple corrections such as deletions account for large portion of the performance, limiting the real-world application of automated patching algorithms. This work aims to test a Transformer with copy mechanism for a number of pre-training and token embedding schemes in a more stringent condition: producing the exactly same bug fix as the developer who commit-pushed the patch code. The background and objective is quite simple, but this work is important in that it provides insight for generating bug fix with Transformer based models regarding pre-training and token-embedding by a number of experiments.
Keypoints
Experiment Transformer based pre-training and token embedding schemes for Java language bug fix
The dataset used for the experiments is the Java dataset from the Patches in the Wild, which mined non-fork github public repository commits with at least one of [bug, error, issue, fix, patch] included.
Abstraction of the code snippets are provided in the dataset for facilitating the learning process, so both the abstracted code and the concrete code are experimented in this work.
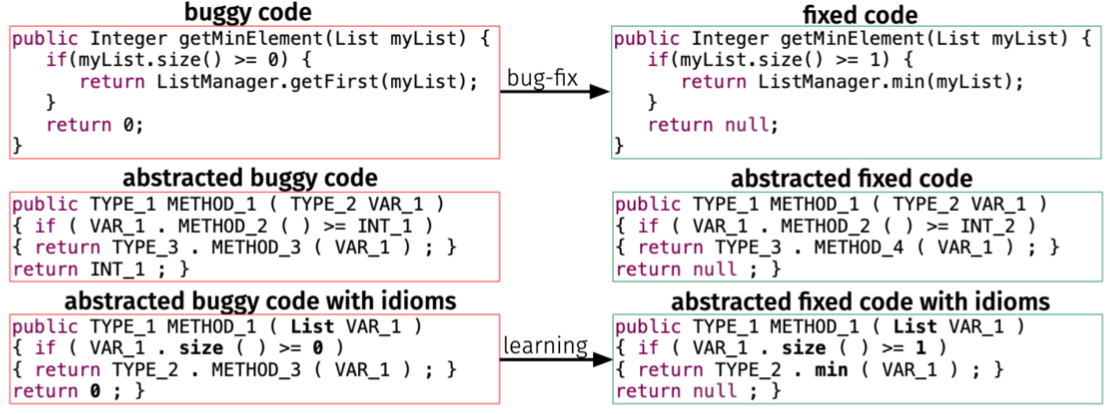 Concrete code, abstracted code, and abstracted code with idioms
Concrete code, abstracted code, and abstracted code with idioms
The Byte Pair Encoding vocabulary of around 50,000 tokens are used for standard embedding of concrete and abstracted codes.
The authors experiment on adding syntax embedding to this standard embedding with an expectation that distinguishing tokens like “return” or “static” can provide performance improvement as the developers can get help from syntax highlighting.
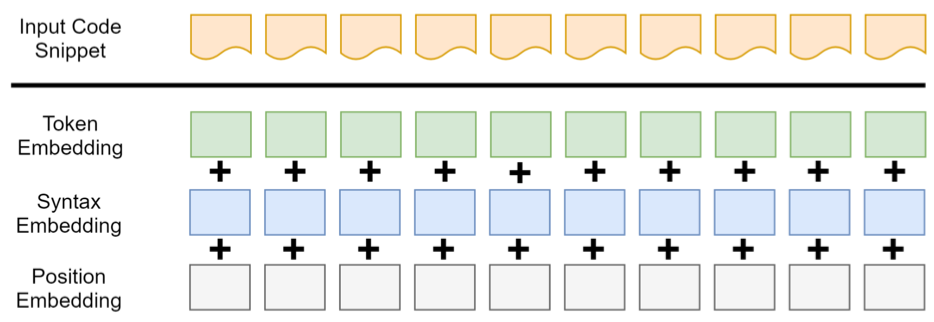 Adding syntax embeddings
Adding syntax embeddings
The model used for the experiments is the original Transformer encoder-decoder architecture with copy mechanism. The authors compare three pre-training strategies: i) pre-training on Java, ii) fine-tune on Java with English pre-trained with BART, iii) adaptive pre-training on Java with warmstart from BART.
Three variations are mentioned in this section so far (concrete vs. abstract code / adding syntax embedding / pre-training strategies), and the authors experiment the last variation as adding a token-type classification loss.
With the auxiliary token-type loss, the model is trained to classify each token to be one of the [TYPE, METHOD, VARIABLE, STRING_LIT, NUM_LIT, OTHER] with the expectation that it can regularize the training process.
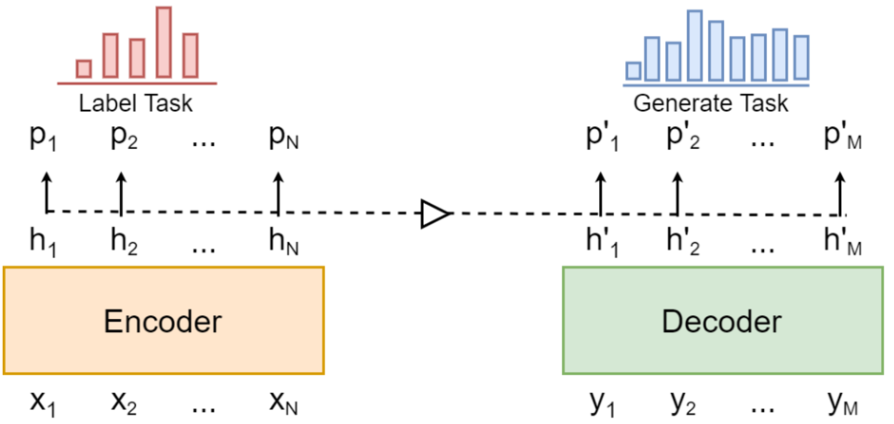 Auxiliary token-type classification loss
Auxiliary token-type classification loss
Concrete code versus abstracted code
It is suggested from experiments that Transformer models can benefit from training on concrete code.
Transformers trained on abstracted code with idioms were especially destructive, producing mostly deletion bug fixes, while smaller GRU models showed better performance with abstracted codes.
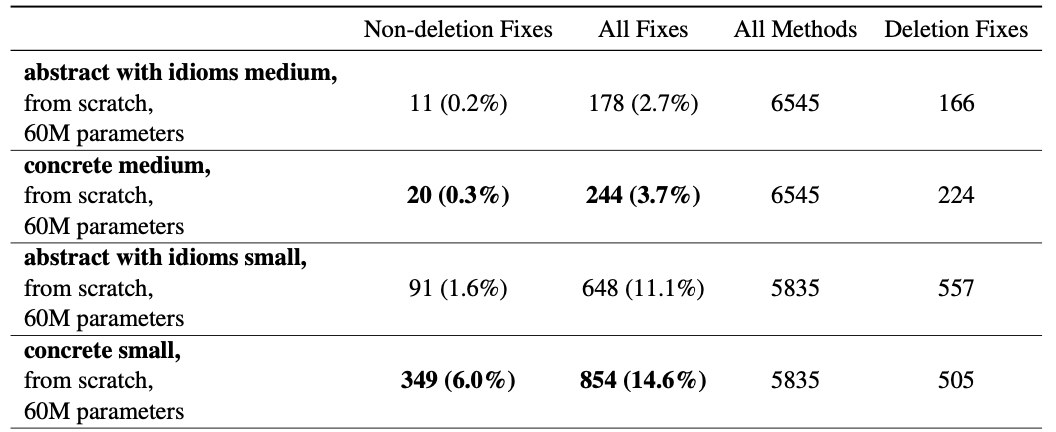 Transformer experiment on concrete code versus abstracted code
Transformer experiment on concrete code versus abstracted code
Pre-training strategies
One of the main finding of this paper is that the pre-training can help Transformer based bug-fix models.
Among the pre-training strategies, English plus Java (Java pre-training with BART warmstart) showed the best performance for both medium and small methods.
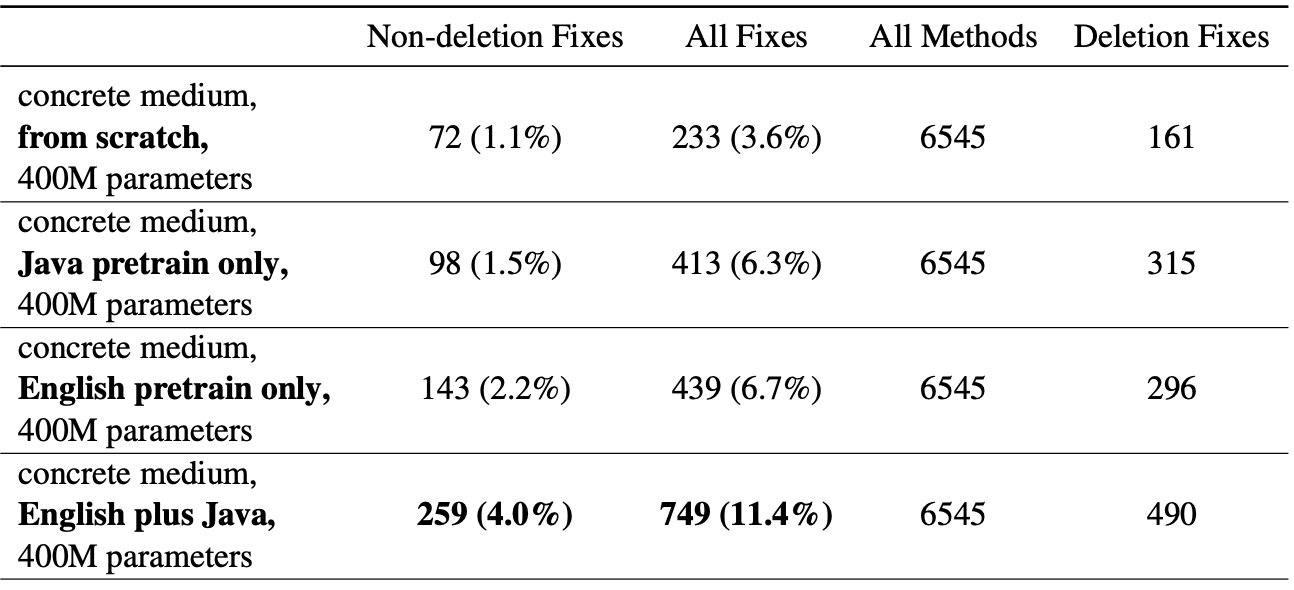 Transformer pre-training strategies of medium methods
Transformer pre-training strategies of medium methods
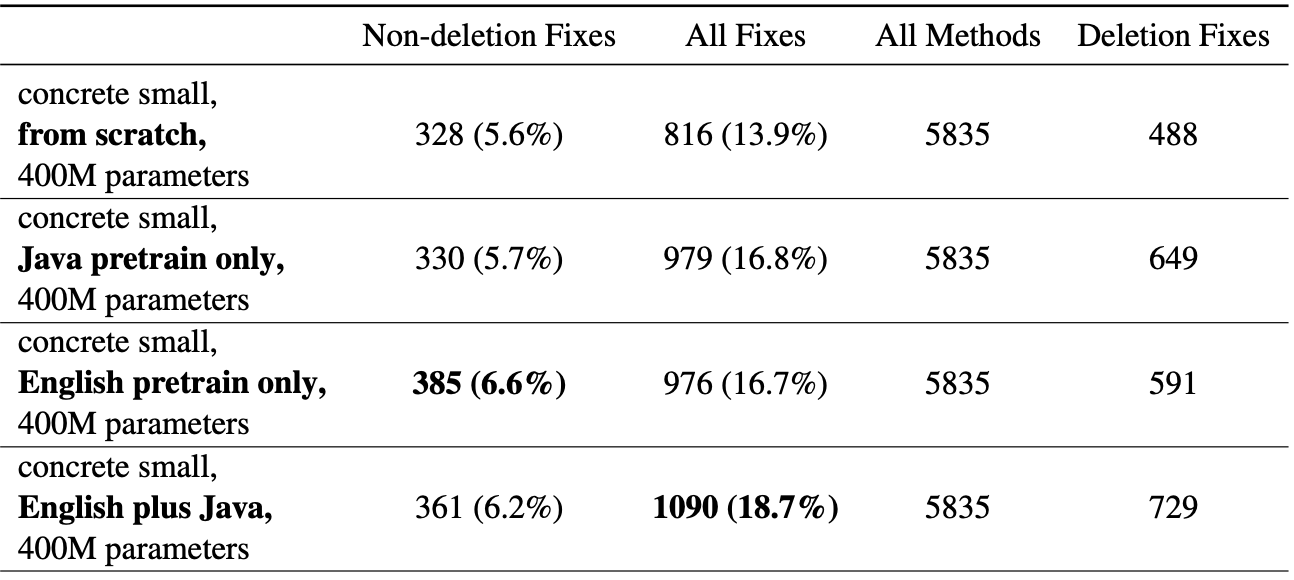 Transformer pre-training strategies of small methods
Transformer pre-training strategies of small methods
The best performing model, which is pre-trained with BART warmstart strategy, is named DeepDebug by the authors.
The DeepDebug outperformed other recent bug-fix methods including CodeBERT and BART
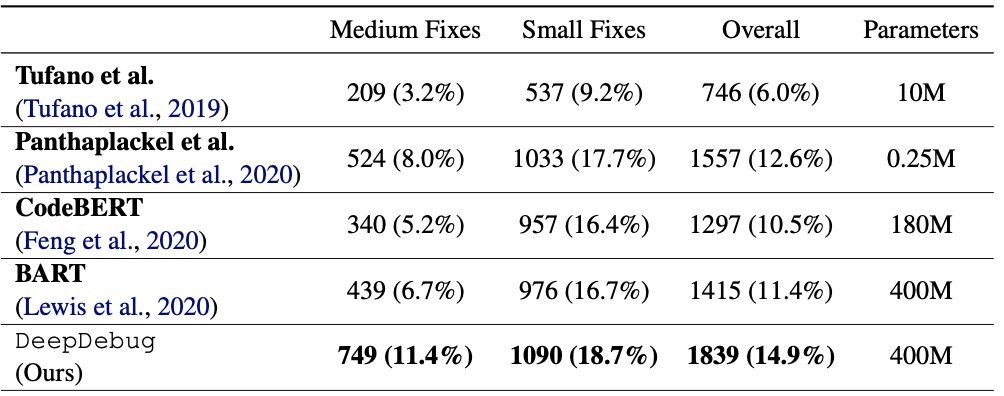 Performance of the proposed DeepDebug, which is a Transformer model with English+Java pre-training
Performance of the proposed DeepDebug, which is a Transformer model with English+Java pre-training
Adding syntax embedding / Auxiliary token-type prediction
For adding syntax embedding and training with an auxiliary classification loss, the two methods showed similar result in that they provided small improvement when training from scratch which was not apparent in the case of fine-tuning.
The authors mention that this is not a very surprising result considering that the classification task may be too easy for a well-pretrained Transformer model.
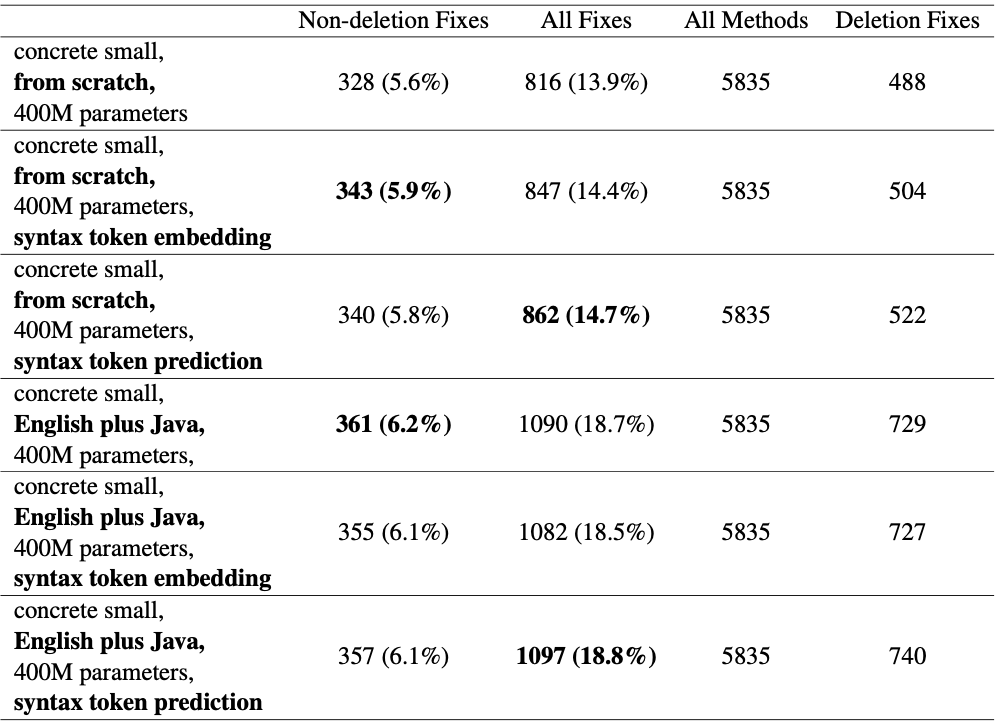 Syntax embedding / token classification experiment result
Syntax embedding / token classification experiment result