Significance
Keypoints
- Propose a self-attention layer with feed-forward network as a CNN
- Demonstrate improvement in performance of ViT models with the proposed self-attention layer
Review
Background
Many variants of the Vision transformer (ViT) are being introduced recently. To survive as a benchmark model from this flooding of ViTs, many studies try to address the non-locality issue of the ViT. For example, the ConViT tried to introduce locality to the self-attention layer by initializing it like a convolution layer (my previous review post on ConViT). However, experiments indicated that the self-attention layer of the ConViT is shifted towards non-locality throughout the training. Can the locality be explicitly introduced to the ViT layers? The authors say yes to this question.
Keypoints
Propose a self-attention layer with feed-forward network as a CNN
In the MobileNetV2, computational efficiency is gained while preserving the performance by a special type of convolution: the depth-wise convolution.
More specifically, convolution layer of a CNN is replaced by a sequence of 1$\times$1 convolution, depth-wise convolution, and again 1$\times$1 convolution.
The authors are motivated by the fact that this sequence of convolution layers share similarity with the feed-forward network of the Transformer encoder.
In fact, the 1$\times$1 convolution is mathematically equivalent to the matrix multiplication, which means that the fully connected layers can be replaced by the 1$\times$1 convolution.
Thus, the feed-forward network of the proposed model consists of two 1$\times$1 convolution and a depth-wise convolution between those two.
However, one problem that should be addressed before this replacement is that the self-attention layer of the ViT takes in the image patches as a 1-dimensional sequence.
The authors overcome this problem by rearranging the self-attended tokens into the original image shape before being input to the feed-forward network, and bypassing the appended class token separately.
This process of rearrangement is denoted as Seq2Img, or Img2Seq.
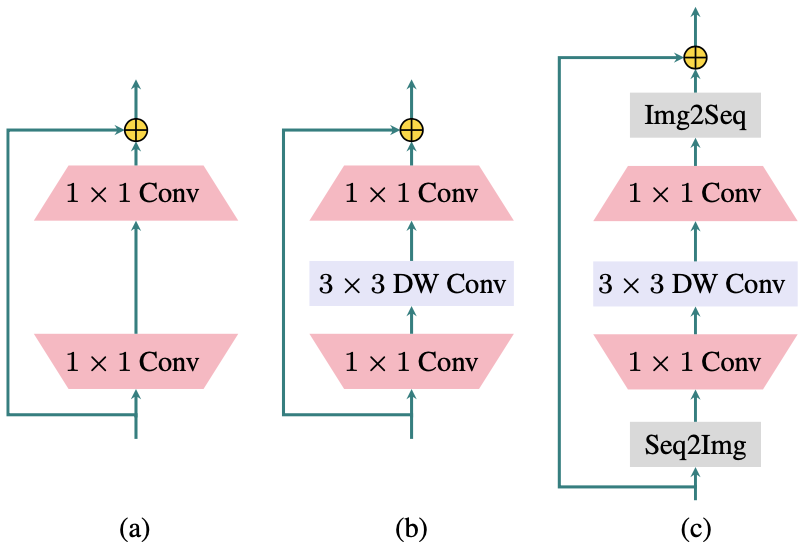 Feed-forward network of the (a) Transformer encoder (b) MobileNetV2 (c) LocalViT (proposed)
Now, the locality of the depth-wise convolution is seamlessly merged into the self-attention layer of the ViTs!
Feed-forward network of the (a) Transformer encoder (b) MobileNetV2 (c) LocalViT (proposed)
Now, the locality of the depth-wise convolution is seamlessly merged into the self-attention layer of the ViTs!
Demonstrate improvement in performance of ViT models with the proposed self-attention layer
The proposed replacement of the feed-forward network can be applied to most of the ViT model variants.
Improvement of the image classification accuracy from the ImageNet dataset is demonstrated by extensive experiments using DeiT-T, T2T-ViT, PVT, and TNT.
Performance of CNNs are also included in the comparative analysis.
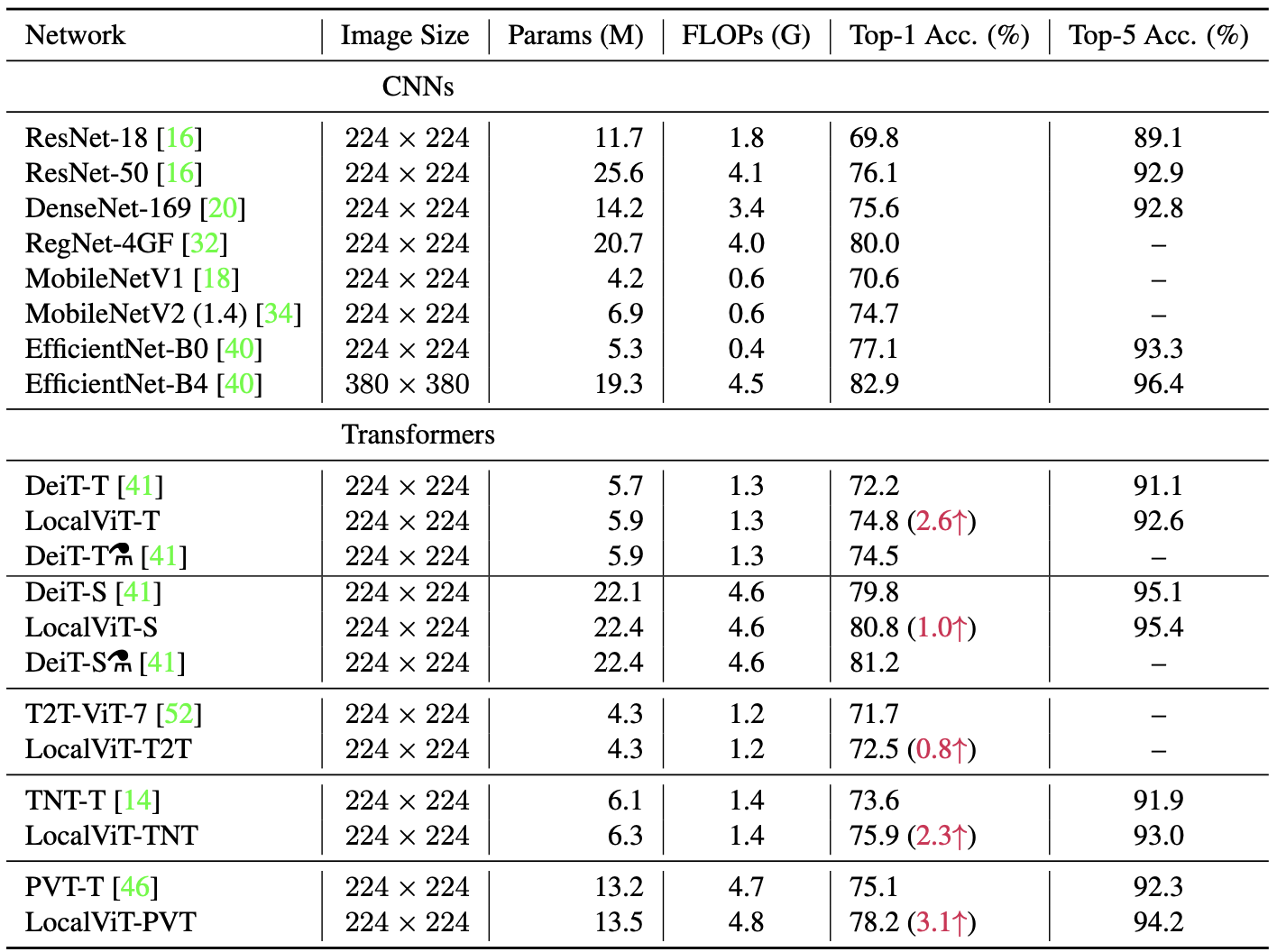 Performance gain by applying LocalViT to ViT models
Performance gain by applying LocalViT to ViT models
The performance gain can further be boosted by employing well-known tricks for CNN layers (e.g. squeeze-excitation), or by changing the activation functions.
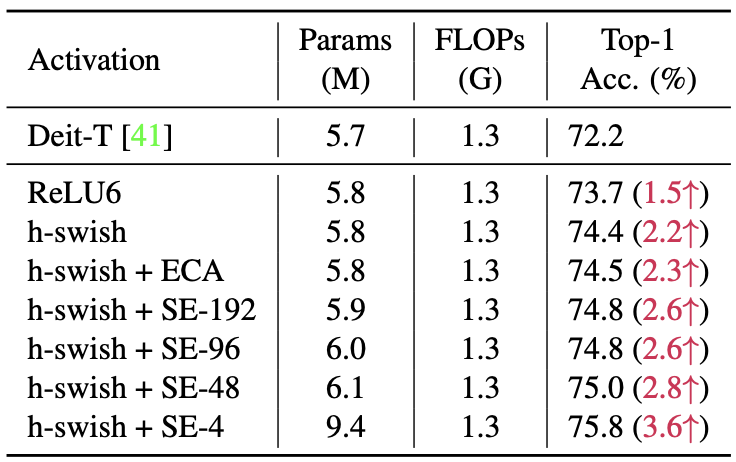 Squeeze-excitation (SE) and swish activation can further improve performance
Squeeze-excitation (SE) and swish activation can further improve performance
The improvement in performance was more apparent when the lower layers were equipped with the locality, but applying the proposed method to all layers did not hurt the performance.
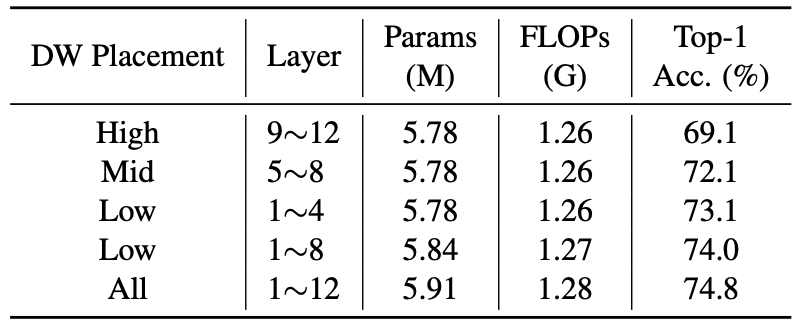 Locality can be equipped to any layers of ViT
Locality can be equipped to any layers of ViT
The training log of the LocalViTs showed lower training loss and higher validation accuracy when compared to the vanilla ViTs.
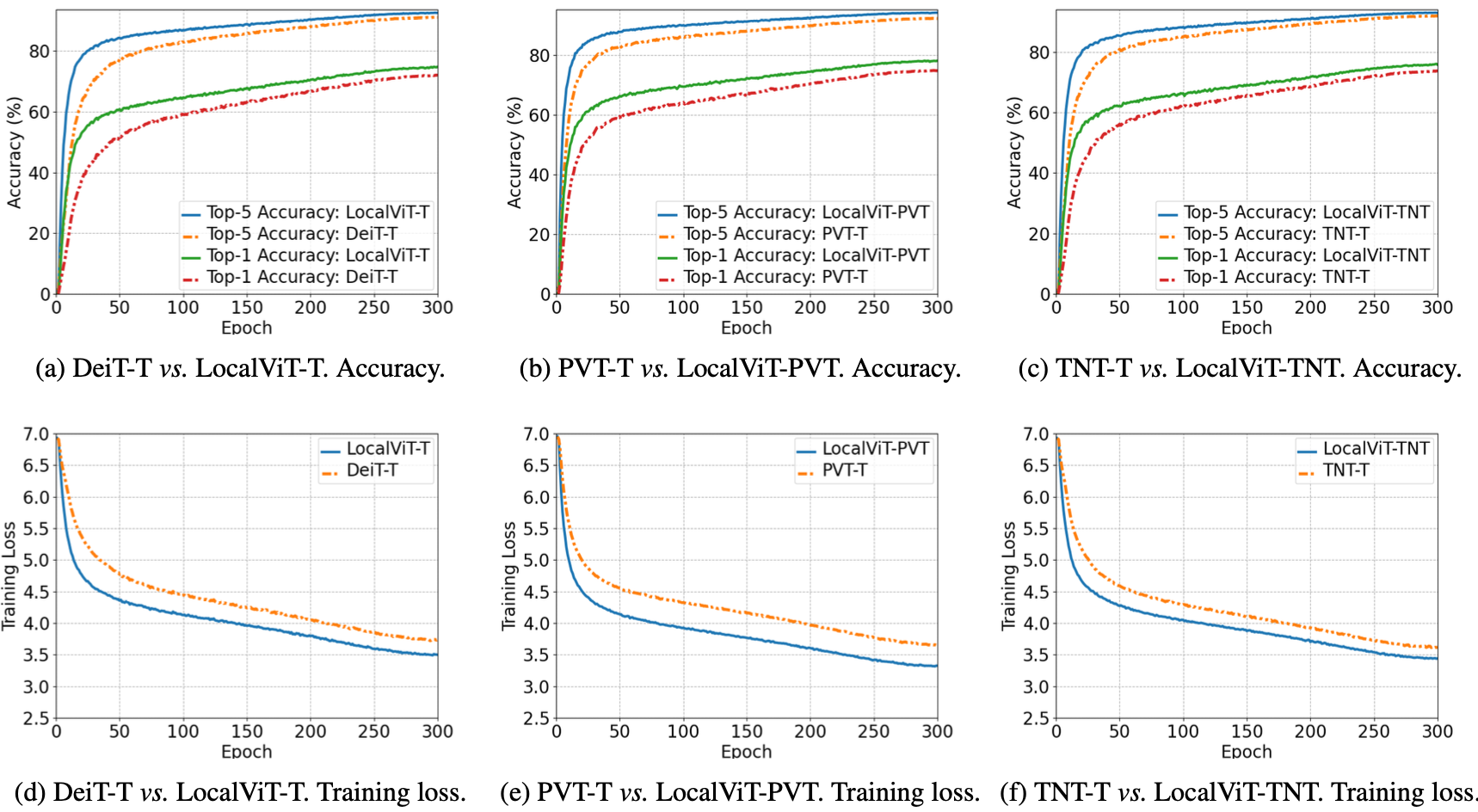 Better training with LocalViTs
Better training with LocalViTs
In conclusion, this paper proposes a simple, general, explicit, and effective way to introduce locality to ViTs which can significantly improve the image classification performance.